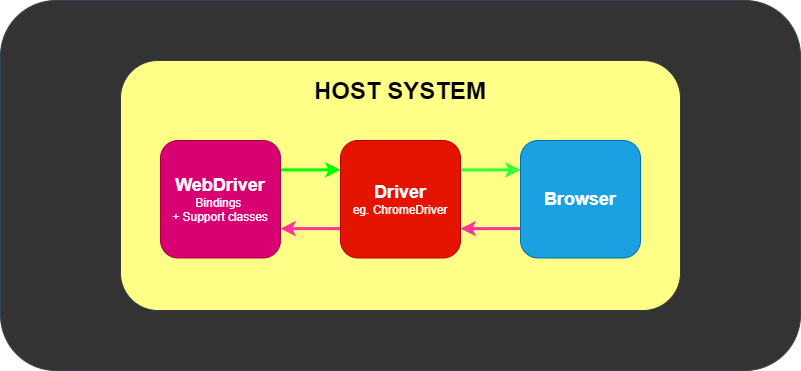
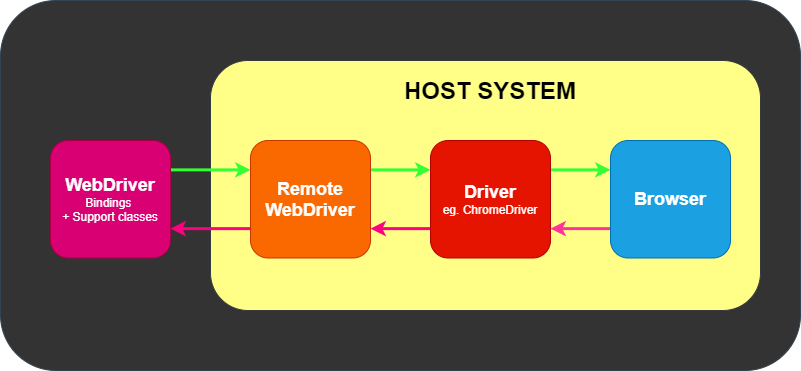
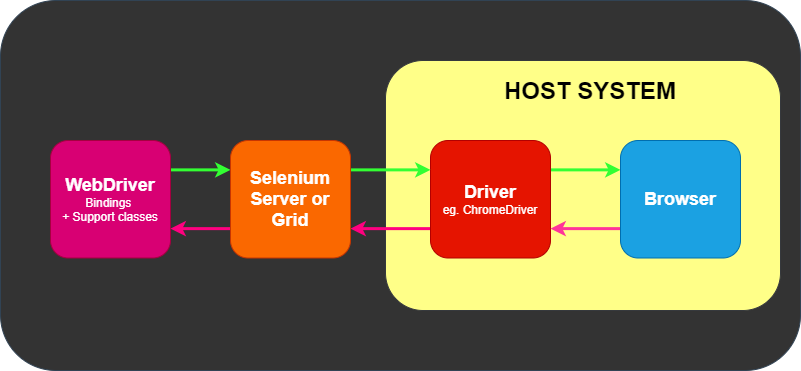
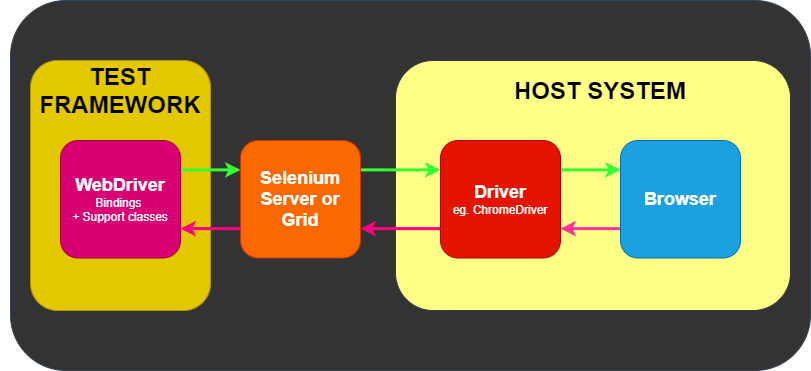
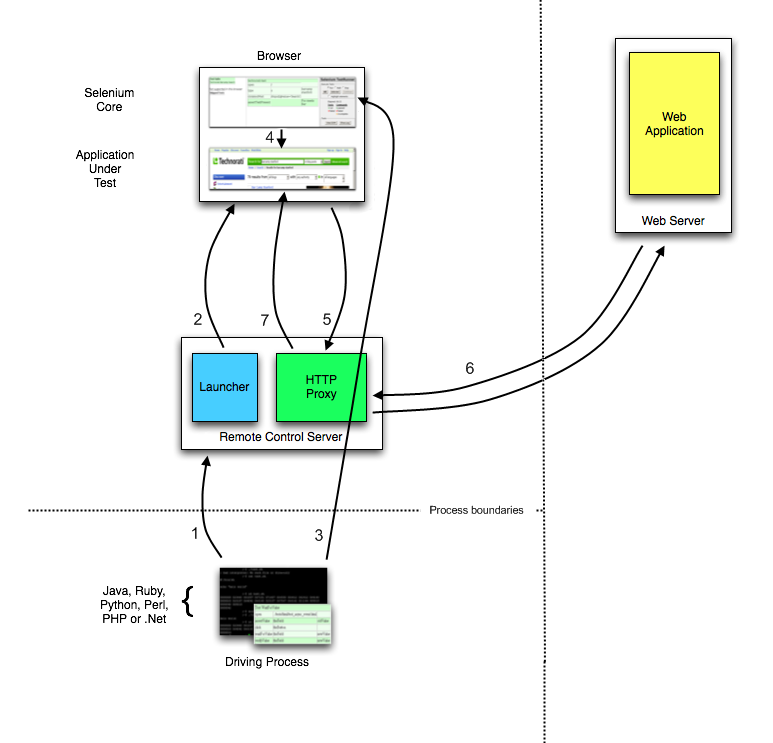
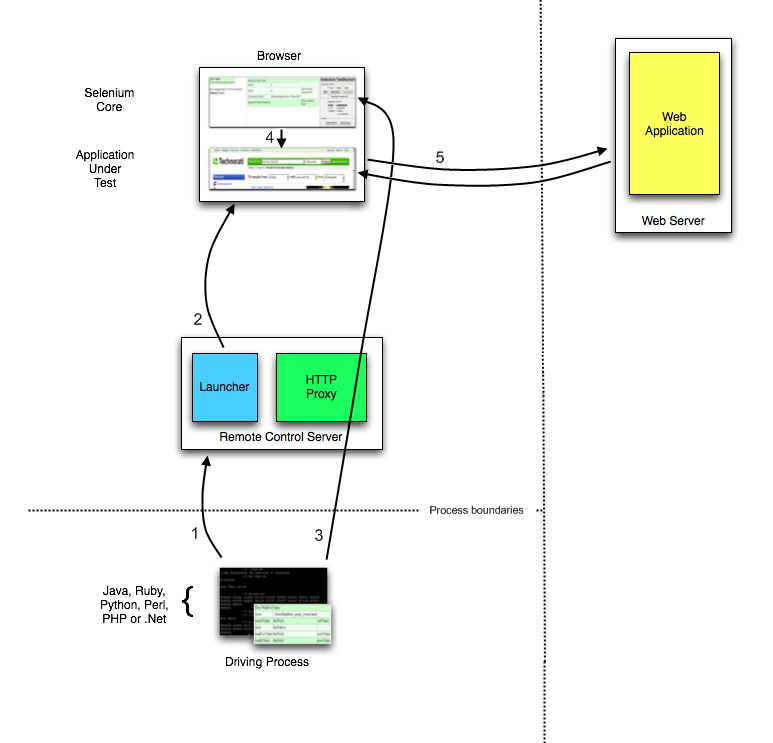
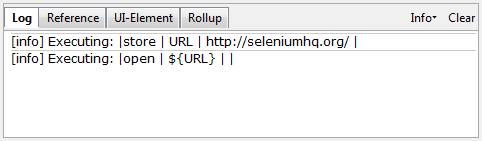
You can find the minimum required version of Node for any given version of Selenium in the
你可以在此查看 Selenium 对 Node 的版本支持情况
位于 Node Support Policy 中的相关章节 npmjs
Java requires you to use the Augmenter class, which allows it to automatically pull in implementations for
all interfaces that match the capabilities used with the RemoteWebDriver
ChromiumNetworkConditionsnetworkConditions=newChromiumNetworkConditions();networkConditions.setOffline(false);networkConditions.setLatency(java.time.Duration.ofMillis(20));// 20 ms of latencynetworkConditions.setDownloadThroughput(2000*1024/8);// 2000 kbpsnetworkConditions.setUploadThroughput(2000*1024/8);// 2000 kbps((ChromeDriver)driver).setNetworkConditions(networkConditions);
network_conditions={"offline":False,"latency":20,# 20 ms of latency"download_throughput":2000*1024/8,# 2000 kbps"upload_throughput":2000*1024/8,# 2000 kbps}driver.set_network_conditions(**network_conditions)
ChromiumNetworkConditionsnetworkConditions=newChromiumNetworkConditions();networkConditions.setOffline(false);networkConditions.setLatency(java.time.Duration.ofMillis(20));// 20 ms of latencynetworkConditions.setDownloadThroughput(2000*1024/8);// 2000 kbpsnetworkConditions.setUploadThroughput(2000*1024/8);// 2000 kbps
network_conditions={"offline":False,"latency":20,# 20 ms of latency"download_throughput":2000*1024/8,# 2000 kbps"upload_throughput":2000*1024/8,# 2000 kbps}driver.set_network_conditions(**network_conditions)
Here are a few common use cases with different capabilities:
Arguments
The args parameter is for a list of Command line switches used when starting the browser. Commonly used args include -headless and "-profile", "/path/to/profile"
The binary parameter takes the path of an alternate location of browser to use. For example, with this parameter you can
use geckodriver to drive Firefox Nightly instead of the production version when both are present on your computer.
const{Builder}=require("selenium-webdriver");constfirefox=require('selenium-webdriver/firefox');constoptions=newfirefox.Options();letprofile='/path to custom profile';options.setProfile(profile);constdriver=newBuilder().forBrowser('firefox').setFirefoxOptions(options).build();
Note: Whether you create an empty FirefoxProfile or point it to the directory of your own profile, Selenium
will create a temporary directory to store either the data of the new profile or a copy of your existing one. Every
time you run your program, a different temporary directory will be created. These directories are not cleaned up
explicitly by Selenium, they should eventually get removed by the operating system. However, if you want to remove
the copy manually (e.g. if your profile is large in size), the path of the copy is exposed by the FirefoxProfile
object. Check the language specific implementation to see how to retrieve that location.
If you want to use an existing Firefox profile, you can pass in the path to that profile. Please refer to the official
Firefox documentation
for instructions on how to find the directory of your profile.
Service
Service settings common to all browsers are described on the Service page.
Log output
Getting driver logs can be helpful for debugging various issues. The Service class lets you
direct where the logs will go. Logging output is ignored unless the user directs it somewhere.
File output
To change the logging output to save to a specific file:
Note: Java also allows setting console output by System Property; Property key: GeckoDriverService.GECKO_DRIVER_LOG_PROPERTY Property value: DriverService.LOG_STDOUT or DriverService.LOG_STDERR
Note: Java also allows setting log level by System Property: Property key: GeckoDriverService.GECKO_DRIVER_LOG_LEVEL_PROPERTY Property value: String representation of FirefoxDriverLogLevel enum
The driver logs everything that gets sent to it, including string representations of large binaries, so
Firefox truncates lines by default. To turn off truncation:
Note: Java also allows setting log level by System Property: Property key: GeckoDriverService.GECKO_DRIVER_LOG_NO_TRUNCATE Property value: "true" or "false"
The default directory for profiles is the system temporary directory. If you do not have access to that directory,
or want profiles to be created some place specific, you can change the profile root directory:
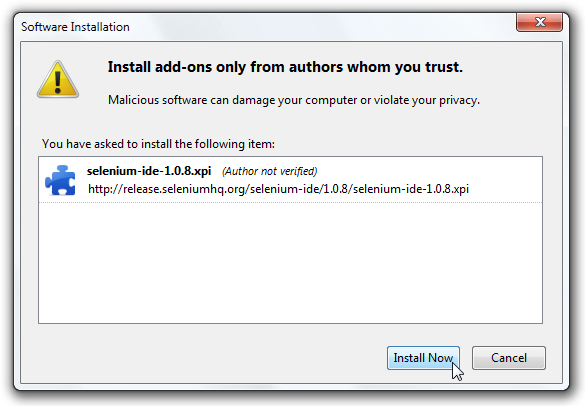
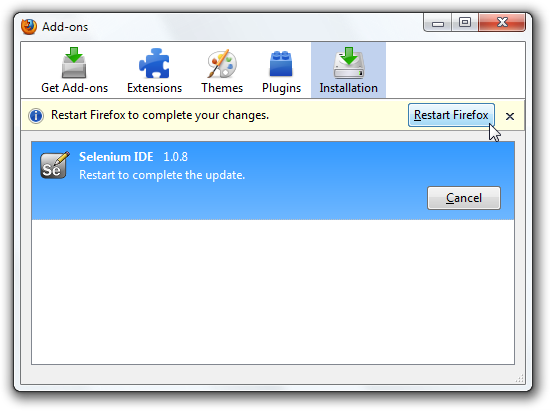
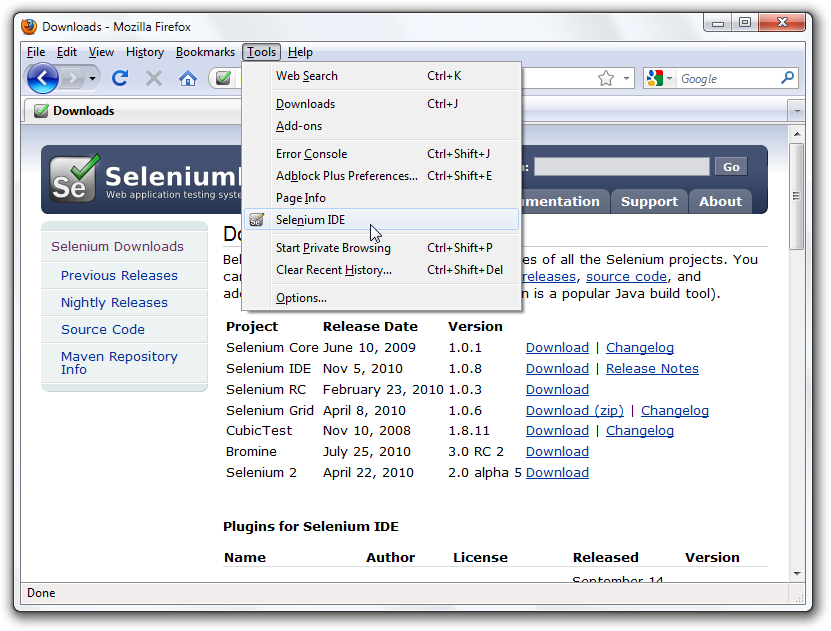
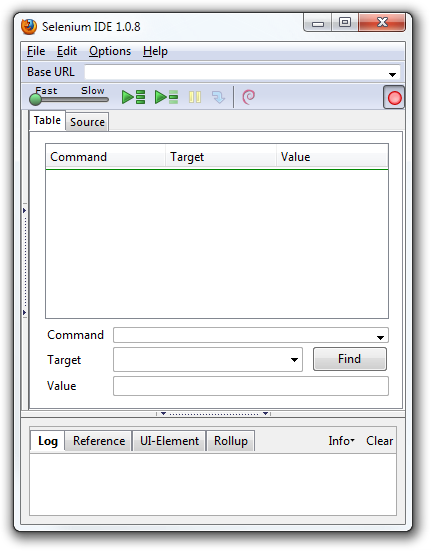
When working with an unfinished or unpublished extension, it will likely not be signed. As such, it can only
be installed as “temporary.” This can be done by passing in either a zip file or a directory, here’s an
example with a directory:
<p><ahref=/documentation/about/contributing/#moving-examples><spanclass="selenium-badge-code"data-bs-toggle="tooltip"data-bs-placement="right"title="One or more of these examples need to be implemented in the examples directory; click for details in the contribution guide">MoveCode</span></a></p>valoptions=InternetExplorerOptions()valdriver=InternetExplorerDriver(options)
以下是几种具有不同功能的常见用例:
fileUploadDialogTimeout
在某些环境中, 当打开文件上传对话框时, Internet Explorer可能会超时. IEDriver的默认超时为1000毫秒, 但您可以使用fileUploadDialogTimeout功能来增加超时时间.
Note: Java also allows setting console output by System Property; Property key: InternetExplorerDriverService.IE_DRIVER_LOGFILE_PROPERTY Property value: DriverService.LOG_STDOUT or DriverService.LOG_STDERR
Note: Java also allows setting log level by System Property: Property key: InternetExplorerDriverService.IE_DRIVER_LOGLEVEL_PROPERTY Property value: String representation of InternetExplorerDriverLogLevel.DEBUG.toString() enum
Perhaps the most common challenge for browser automation is ensuring
that the web application is in a state to execute a particular
Selenium command as desired. The processes often end up in
a race condition where sometimes the browser gets into the right
state first (things work as intended) and sometimes the Selenium code
executes first (things do not work as intended). This is one of the
primary causes of flaky tests.
All navigation commands wait for a specific readyState value
based on the page load strategy (the
default value to wait for is "complete") before the driver returns control to the code.
The readyState only concerns itself with loading assets defined in the HTML,
but loaded JavaScript assets often result in changes to the site,
and elements that need to be interacted with may not yet be on the page
when the code is ready to execute the next Selenium command.
Similarly, in a lot of single page applications, elements get dynamically
added to a page or change visibility based on a click.
An element must be both present and
displayed on the page
in order for Selenium to interact with it.
Take this page for example: https://www.selenium.dev/selenium/web/dynamic.html
When the “Add a box!” button is clicked, a “div” element that does not exist is created.
When the “Reveal a new input” button is clicked, a hidden text field element is displayed.
In both cases the transition takes a couple seconds.
If the Selenium code is to click one of these buttons and interact with the resulting element,
it will do so before that element is ready and fail.
The first solution many people turn to is adding a sleep statement to
pause the code execution for a set period of time.
Because the code can’t know exactly how long it needs to wait, this
can fail when it doesn’t sleep long enough. Alternately, if the value is set too high
and a sleep statement is added in every place it is needed, the duration of
the session can become prohibitive.
Selenium provides two different mechanisms for synchronization that are better.
Implicit waits
Selenium has a built-in way to automatically wait for elements called an implicit wait.
An implicit wait value can be set either with the timeouts
capability in the browser options, or with a driver method (as shown below).
This is a global setting that applies to every element location call for the entire session.
The default value is 0, which means that if the element is not found, it will
immediately return an error. If an implicit wait is set, the driver will wait for the
duration of the provided value before returning the error. Note that as soon as the
element is located, the driver will return the element reference and the code will continue executing,
so a larger implicit wait value won’t necessarily increase the duration of the session.
Warning:
Do not mix implicit and explicit waits.
Doing so can cause unpredictable wait times.
For example, setting an implicit wait of 10 seconds
and an explicit wait of 15 seconds
could cause a timeout to occur after 20 seconds.
Solving our example with an implicit wait looks like this:
Explicit waits are loops added to the code that poll the application
for a specific condition to evaluate as true before it exits the loop and
continues to the next command in the code. If the condition is not met before a designated timeout value,
the code will give a timeout error. Since there are many ways for the application not to be in the desired state,
explicit waits are a great choice to specify the exact condition to wait for
in each place it is needed.
Another nice feature is that, by default, the Selenium Wait class automatically waits for the designated element to exist.
This example shows the condition being waited for as a lambda. Java also supports
Expected Conditions
The Wait class can be instantiated with various parameters that will change how the conditions are evaluated.
This can include:
Changing how often the code is evaluated (polling interval)
Specifying which exceptions should be handled automatically
Changing the total timeout length
Customizing the timeout message
For instance, if the element not interactable error is retried by default, then we can
add an action on a method inside the code getting executed (we just need to
make sure that the code returns true when it is successful):
The easiest way to customize Waits in Java is to use the FluentWait class:
```java
import org.openqa.selenium.By
import org.openqa.selenium.chrome.ChromeDriver
fun main() {
val driver = ChromeDriver()
driver.get("https://the-internet.herokuapp.com/upload")
driver.findElement(By.id("file-upload")).sendKeys("selenium-snapshot.jpg")
driver.findElement(By.id("file-submit")).submit()
if(driver.pageSource.contains("File Uploaded!")) {
println("file uploaded")
}
else{
println("file not uploaded")
}
}
```
2.5.2 - 查询网络元素
根据提供的定位值定位元素.
One of the most fundamental aspects of using Selenium is obtaining element references to work with.
Selenium offers a number of built-in locator strategies to uniquely identify an element.
There are many ways to use the locators in very advanced scenarios. For the purposes of this documentation,
let’s consider this HTML snippet:
<olid="vegetables"><liclass="potatoes">…
<liclass="onions">…
<liclass="tomatoes"><span>Tomato is a Vegetable</span>…
</ol><ulid="fruits"><liclass="bananas">…
<liclass="apples">…
<liclass="tomatoes"><span>Tomato is a Fruit</span>…
</ul>
First matching element
Many locators will match multiple elements on the page. The singular find element method will return a reference to the
first element found within a given context.
Evaluating entire DOM
When the find element method is called on the driver instance, it
returns a reference to the first element in the DOM that matches with the provided locator.
This value can be stored and used for future element actions. In our example HTML above, there are
two elements that have a class name of “tomatoes” so this method will return the element in the “vegetables” list.
Rather than finding a unique locator in the entire DOM, it is often useful to narrow the search to the scope
of another located element. In the above example there are two elements with a class name of “tomatoes” and
it is a little more challenging to get the reference for the second one.
One solution is to locate an element with a unique attribute that is an ancestor of the desired element and not an
ancestor of the undesired element, then call find element on that object:
Java and C# WebDriver, WebElement and ShadowRoot classes all implement a SearchContext interface, which is
considered a role-based interface. Role-based interfaces allow you to determine whether a particular
driver implementation supports a given feature. These interfaces are clearly defined and try
to adhere to having only a single role of responsibility.
Evaluating the Shadow DOM
The Shadow DOM is an encapsulated DOM tree hidden inside an element.
With the release of v96 in Chromium Browsers, Selenium can now allow you to access this tree
with easy-to-use shadow root methods. NOTE: These methods require Selenium 4.0 or greater.
There are several use cases for needing to get references to all elements that match a locator, rather
than just the first one. The plural find elements methods return a collection of element references.
If there are no matches, an empty list is returned. In this case,
references to all fruits and vegetable list items will be returned in a collection.
Often you get a collection of elements but want to work with a specific element, which means you
need to iterate over the collection and identify the one you want.
fromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriver=webdriver.Firefox()# Navigate to Urldriver.get("https://www.example.com")# Get all the elements available with tag name 'p'elements=driver.find_elements(By.TAG_NAME,'p')foreinelements:print(e.text)
usingOpenQA.Selenium;usingOpenQA.Selenium.Firefox;usingSystem.Collections.Generic;namespaceFindElementsExample{classFindElementsExample{publicstaticvoidMain(string[]args){IWebDriverdriver=newFirefoxDriver();try{// Navigate to Urldriver.Navigate().GoToUrl("https://example.com");// Get all the elements available with tag name 'p'IList<IWebElement>elements=driver.FindElements(By.TagName("p"));foreach(IWebElementeinelements){System.Console.WriteLine(e.Text);}}finally{driver.Quit();}}}}
const{Builder,By}=require('selenium-webdriver');(asyncfunctionexample(){letdriver=awaitnewBuilder().forBrowser('firefox').build();try{// Navigate to Url
awaitdriver.get('https://www.example.com');// Get all the elements available with tag 'p'
letelements=awaitdriver.findElements(By.css('p'));for(leteofelements){console.log(awaite.getText());}}finally{awaitdriver.quit();}})();
importorg.openqa.selenium.Byimportorg.openqa.selenium.firefox.FirefoxDriverfunmain(){valdriver=FirefoxDriver()try{driver.get("https://example.com")// Get all the elements available with tag name 'p'
valelements=driver.findElements(By.tagName("p"))for(elementinelements){println("Paragraph text:"+element.text)}}finally{driver.quit()}}
Find Elements From Element
It is used to find the list of matching child WebElements within the context of parent element.
To achieve this, the parent WebElement is chained with ‘findElements’ to access child elements
importorg.openqa.selenium.By;importorg.openqa.selenium.WebDriver;importorg.openqa.selenium.WebElement;importorg.openqa.selenium.chrome.ChromeDriver;importjava.util.List;publicclassfindElementsFromElement{publicstaticvoidmain(String[]args){WebDriverdriver=newChromeDriver();try{driver.get("https://example.com");// Get element with tag name 'div'WebElementelement=driver.findElement(By.tagName("div"));// Get all the elements available with tag name 'p'List<WebElement>elements=element.findElements(By.tagName("p"));for(WebElemente:elements){System.out.println(e.getText());}}finally{driver.quit();}}}
fromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriver=webdriver.Chrome()driver.get("https://www.example.com")##get elements from parent element using TAG_NAME# Get element with tag name 'div'element=driver.find_element(By.TAG_NAME,'div')# Get all the elements available with tag name 'p'elements=element.find_elements(By.TAG_NAME,'p')foreinelements:print(e.text)##get elements from parent element using XPATH##NOTE: in order to utilize XPATH from current element, you must add "." to beginning of path# Get first element of tag 'ul'element=driver.find_element(By.XPATH,'//ul')# get children of tag 'ul' with tag 'li'elements=driver.find_elements(By.XPATH,'.//li')foreinelements:print(e.text)
usingOpenQA.Selenium;usingOpenQA.Selenium.Chrome;usingSystem.Collections.Generic;namespaceFindElementsFromElement{classFindElementsFromElement{publicstaticvoidMain(string[]args){IWebDriverdriver=newChromeDriver();try{driver.Navigate().GoToUrl("https://example.com");// Get element with tag name 'div'IWebElementelement=driver.FindElement(By.TagName("div"));// Get all the elements available with tag name 'p'IList<IWebElement>elements=element.FindElements(By.TagName("p"));foreach(IWebElementeinelements){System.Console.WriteLine(e.Text);}}finally{driver.Quit();}}}}
const{Builder,By}=require('selenium-webdriver');(asyncfunctionexample(){letdriver=newBuilder().forBrowser('chrome').build();awaitdriver.get('https://www.example.com');// Get element with tag name 'div'
letelement=driver.findElement(By.css("div"));// Get all the elements available with tag name 'p'
letelements=awaitelement.findElements(By.css("p"));for(leteofelements){console.log(awaite.getText());}})();
importorg.openqa.selenium.Byimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")// Get element with tag name 'div'
valelement=driver.findElement(By.tagName("div"))// Get all the elements available with tag name 'p'
valelements=element.findElements(By.tagName("p"))for(einelements){println(e.text)}}finally{driver.quit()}}
Get Active Element
It is used to track (or) find DOM element which has the focus in the current browsing context.
importorg.openqa.selenium.*;importorg.openqa.selenium.chrome.ChromeDriver;publicclassactiveElementTest{publicstaticvoidmain(String[]args){WebDriverdriver=newChromeDriver();try{driver.get("http://www.google.com");driver.findElement(By.cssSelector("[name='q']")).sendKeys("webElement");// Get attribute of current active elementStringattr=driver.switchTo().activeElement().getAttribute("title");System.out.println(attr);}finally{driver.quit();}}}
fromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriver=webdriver.Chrome()driver.get("https://www.google.com")driver.find_element(By.CSS_SELECTOR,'[name="q"]').send_keys("webElement")# Get attribute of current active elementattr=driver.switch_to.active_element.get_attribute("title")print(attr)
usingOpenQA.Selenium;usingOpenQA.Selenium.Chrome;namespaceActiveElement{classActiveElement{publicstaticvoidMain(string[]args){IWebDriverdriver=newChromeDriver();try{// Navigate to Urldriver.Navigate().GoToUrl("https://www.google.com");driver.FindElement(By.CssSelector("[name='q']")).SendKeys("webElement");// Get attribute of current active elementstringattr=driver.SwitchTo().ActiveElement().GetAttribute("title");System.Console.WriteLine(attr);}finally{driver.Quit();}}}}
const{Builder,By}=require('selenium-webdriver');(asyncfunctionexample(){letdriver=awaitnewBuilder().forBrowser('chrome').build();awaitdriver.get('https://www.google.com');awaitdriver.findElement(By.css('[name="q"]')).sendKeys("webElement");// Get attribute of current active element
letattr=awaitdriver.switchTo().activeElement().getAttribute("title");console.log(`${attr}`)})();
importorg.openqa.selenium.Byimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://www.google.com")driver.findElement(By.cssSelector("[name='q']")).sendKeys("webElement")// Get attribute of current active element
valattr=driver.switchTo().activeElement().getAttribute("title")print(attr)}finally{driver.quit()}}
driver.get("https://www.selenium.dev/selenium/web/inputs.html");// Click on the element WebElementcheckInput=driver.findElement(By.name("checkbox_input"));checkInput.click();
# Navigate to URLdriver.get("https://www.selenium.dev/selenium/web/inputs.html")# Click on the checkboxcheck_input=driver.find_element(By.NAME,"checkbox_input")check_input.click()
// Navigate to Urldriver.Navigate().GoToUrl("https://www.selenium.dev/selenium/web/inputs.html");// Click on the element IWebElementcheckInput=driver.FindElement(By.Name("checkbox_input"));checkInput.Click();
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")// Click the element
driver.findElement(By.name("color_input")).click();
// Clear field to empty it from any previous dataWebElementemailInput=driver.findElement(By.name("email_input"));emailInput.clear();//Enter TextStringemail="admin@localhost.dev";emailInput.sendKeys(email);
# Handle the email input fieldemail_input=driver.find_element(By.NAME,"email_input")email_input.clear()# Clear fieldemail="admin@localhost.dev"email_input.send_keys(email)# Enter text
//SendKeys// Clear field to empty it from any previous dataIWebElementemailInput=driver.FindElement(By.Name("email_input"));emailInput.Clear();//Enter TextStringemail="admin@localhost.dev";emailInput.SendKeys(email);
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//Clear field to empty it from any previous data
driver.findElement(By.name("email_input")).clear()// Enter text
driver.findElement(By.name("email_input")).sendKeys("admin@localhost.dev")
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//Clear field to empty it from any previous data
driver.findElement(By.name("email_input")).clear()
To work on a web element using Selenium, we need to first locate it on the web page.
Selenium provides us above mentioned ways, using which we can locate element on the
page. To understand and create locator we will use the following HTML snippet.
<html><body><style>.information{background-color:white;color:black;padding:10px;}</style><h2>Contact Selenium</h2><form><inputtype="radio"name="gender"value="m"/>Male <inputtype="radio"name="gender"value="f"/>Female <br><br><labelfor="fname">First name:</label><br><inputclass="information"type="text"id="fname"name="fname"value="Jane"><br><br><labelfor="lname">Last name:</label><br><inputclass="information"type="text"id="lname"name="lname"value="Doe"><br><br><labelfor="newsletter">Newsletter:</label><inputtype="checkbox"name="newsletter"value="1"/><br><br><inputtype="submit"value="Submit"></form><p>To know more about Selenium, visit the official page
<ahref ="www.selenium.dev">Selenium Official Page</a></p></body></html>
class name
The HTML page web element can have attribute class. We can see an example in the
above shown HTML snippet. We can identify these elements using the class name locator
available in Selenium.
CSS is the language used to style HTML pages. We can use css selector locator strategy
to identify the element on the page. If the element has an id, we create the locator
as css = #id. Otherwise the format we follow is css =[attribute=value] .
Let us see an example from above HTML snippet. We will create locator for First Name
textbox, using css.
We can use the ID attribute available with element in a web page to locate it.
Generally the ID property should be unique for a element on the web page.
We will identify the Last Name field using it.
We can use the NAME attribute available with element in a web page to locate it.
Generally the NAME property should be unique for a element on the web page.
We will identify the Newsletter checkbox using it.
If the element we want to locate is a link, we can use the link text locator
to identify it on the web page. The link text is the text displayed of the link.
In the HTML snippet shared, we have a link available, lets see how will we locate it.
WebDriverdriver=newChromeDriver();driver.findElement(By.linkText("Selenium Official Page"));
driver=webdriver.Chrome()driver.get("https://www.selenium.dev/selenium/web/locators_tests/locators.html")element=driver.find_element(By.LINK_TEXT,"Selenium Official Page")
letdriver=awaitnewBuilder().forBrowser('chrome').build();constloc=awaitdriver.findElement(By.linkText('Selenium Official Page'));
valdriver=ChromeDriver()valloc:WebElement=driver.findElement(By.linkText("Selenium Official Page"))
partial link text
If the element we want to locate is a link, we can use the partial link text locator
to identify it on the web page. The link text is the text displayed of the link.
We can pass partial text as value.
In the HTML snippet shared, we have a link available, lets see how will we locate it.
We can use the HTML TAG itself as a locator to identify the web element on the page.
From the above HTML snippet shared, lets identify the link, using its html tag “a”.
A HTML document can be considered as a XML document, and then we can use xpath
which will be the path traversed to reach the element of interest to locate the element.
The XPath could be absolute xpath, which is created from the root of the document.
Example - /html/form/input[1]. This will return the male radio button.
Or the xpath could be relative. Example- //input[@name=‘fname’]. This will return the
first name text box. Let us create locator for female radio button using xpath.
The FindElement makes using locators a breeze! For most languages,
all you need to do is utilize webdriver.common.by.By, however in
others it’s as simple as setting a parameter in the FindElement function
The ByChained class enables you to chain two By locators together. For example,
instead of having to locate a parent element, and then a child element of that parent,
you can instead combine those two FindElement functions into one.
The ByAll class enables you to utilize two By locators at once, finding elements that mach either of your By locators.
For example, instead of having to utilize two FindElement() functions to find the username and password input fields
seperately, you can instead find them together in one clean FindElements()
Selenium 4 introduces Relative Locators (previously
called as Friendly Locators). These locators are helpful when it is not easy to construct a locator for
the desired element, but easy to describe spatially where the element is in relation to an element that does have
an easily constructed locator.
How it works
Selenium uses the JavaScript function
getBoundingClientRect()
to determine the size and position of elements on the page, and can use this information to locate neighboring elements. find the relative elements.
Relative locator methods can take as the argument for the point of origin, either a previously located element reference,
or another locator. In these examples we’ll be using locators only, but you could swap the locator in the final method with
an element object and it will work the same.
Let us consider the below example for understanding the relative locators.
Available relative locators
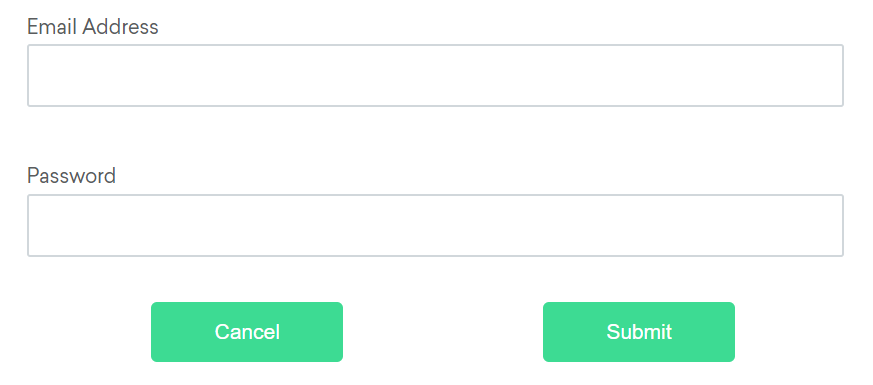
Above
If the email text field element is not easily identifiable for some reason, but the password text field element is,
we can locate the text field element using the fact that it is an “input” element “above” the password element.
If the password text field element is not easily identifiable for some reason, but the email text field element is,
we can locate the text field element using the fact that it is an “input” element “below” the email element.
If the cancel button is not easily identifiable for some reason, but the submit button element is,
we can locate the cancel button element using the fact that it is a “button” element to the “left of” the submit element.
If the submit button is not easily identifiable for some reason, but the cancel button element is,
we can locate the submit button element using the fact that it is a “button” element “to the right of” the cancel element.
If the relative positioning is not obvious, or it varies based on window size, you can use the near method to
identify an element that is at most 50px away from the provided locator.
One great use case for this is to work with a form element that doesn’t have an easily constructed locator,
but its associated input label element does.
You can also chain locators if needed. Sometimes the element is most easily identified as being both above/below one element and right/left of another.
driver.get("https://www.selenium.dev/selenium/web/inputs.html");// isDisplayed // Get boolean value for is element displaybooleanisEmailVisible=driver.findElement(By.name("email_input")).isDisplayed();
// Navigate to Urldriver.Url="https://www.selenium.dev/selenium/web/inputs.html";// isDisplayed // Get boolean value for is element displayboolisEmailVisible=driver.FindElement(By.Name("email_input")).Displayed;
//navigates to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//returns true if element is displayed else returns false
valflag=driver.findElement(By.name("email_input")).isDisplayed()
//navigates to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//returns true if element is enabled else returns false
valattr=driver.findElement(By.name("button_input")).isEnabled()
// isSelected// returns true if element is checked else returns falsebooleanisSelectedCheck=driver.findElement(By.name("checkbox_input")).isSelected();
//navigates to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//returns true if element is checked else returns false
valattr=driver.findElement(By.name("checkbox_input")).isSelected()
//navigates to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//returns TagName of the element
valattr=driver.findElement(By.name("email_input")).getTagName()
位置和大小
用于获取参照元素的尺寸和坐标。
提取的数据主体包含以下详细信息:
元素左上角的X轴位置
元素左上角的y轴位置
元素的高度
元素的宽度
// GetRect// Returns height, width, x and y coordinates referenced elementRectangleres=driver.findElement(By.name("range_input")).getRect();
// Navigate to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")// Returns height, width, x and y coordinates referenced element
valres=driver.findElement(By.name("range_input")).rect// Rectangle class provides getX,getY, getWidth, getHeight methods
println(res.getX())
获取元素CSS值
获取当前浏览上下文中元素的特定计算样式属性的值。
// Retrieves the computed style property 'font-size' of fieldStringcssValue=driver.findElement(By.name("color_input")).getCssValue("font-size");
awaitdriver.get('https://www.selenium.dev/selenium/web/colorPage.html');// Returns background color of the element
letvalue=awaitdriver.findElement(By.id('namedColor')).getCssValue('background-color');
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/colorPage.html")// Retrieves the computed style property 'color' of linktext
valcssValue=driver.findElement(By.id("namedColor")).getCssValue("background-color")
文本内容
获取特定元素渲染后的文本内容。
// GetText// Retrieves the text of the elementStringtext=driver.findElement(By.tagName("h1")).getText();
awaitdriver.get('https://www.selenium.dev/selenium/web/linked_image.html');// Returns text of the element
lettext=awaitdriver.findElement(By.id('justanotherLink')).getText();
// Navigate to URL
driver.get("https://www.selenium.dev/selenium/web/linked_image.html")// retrieves the text of the element
valtext=driver.findElement(By.id("justanotherlink")).getText()
获取特性或属性
获取与 DOM 属性关联的运行时的值。
它返回与该元素的 DOM 特性或属性关联的数据。
// FetchAttributes// identify the email text boxWebElementemailTxt=driver.findElement(By.name(("email_input")));// fetch the value property associated with the textboxStringvalueInfo=emailTxt.getAttribute("value");
// FetchAttributes// identify the email text boxIWebElementemailTxt=driver.FindElement(By.Name("email_input"));// fetch the value property associated with the textboxstringvalueInfo=emailTxt.GetAttribute("value");
// identify the email text box
constemailElement=awaitdriver.findElement(By.xpath('//input[@name="email_input"]'));//fetch the attribute "name" associated with the textbox
constnameAttribute=awaitemailElement.getAttribute("name");
// Navigate to URL
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//fetch the value property associated with the textbox
valattr=driver.findElement(By.name("email_input")).getAttribute("value")
wait.until(ExpectedConditions.alertIsPresent());Alertalert=driver.switchTo().alert();//Store the alert text in a variable and verify itStringtext=alert.getText();assertEquals(text,"Sample Alert");//PresstheOKbutton
element=driver.find_element(By.LINK_TEXT,"See an example alert")element.click()wait=WebDriverWait(driver,timeout=2)alert=wait.until(lambdad:d.switch_to.alert)text=alert.textalert.accept()
//Click the link to activate the alertdriver.FindElement(By.LinkText("See an example alert")).Click();//Wait for the alert to be displayed and store it in a variableIAlertalert=wait.Until(ExpectedConditions.AlertIsPresent());//Store the alert text in a variablestringtext=alert.Text;//Press the OK buttonalert.Accept();
# Store the alert reference in a variablealert=driver.switch_to.alert# Get the text of the alertalert.text# Press on Cancel buttonalert.dismiss
//Click the link to activate the alert
driver.findElement(By.linkText("See an example alert")).click()//Wait for the alert to be displayed and store it in a variable
valalert=wait.until(ExpectedConditions.alertIsPresent())//Store the alert text in a variable
valtext=alert.getText()//Press the OK button
alert.accept()
alert=driver.switchTo().alert();//Store the alert text in a variable and verify ittext=alert.getText();assertEquals(text,"Are you sure?");//PresstheCancelbutton
element=driver.find_element(By.LINK_TEXT,"See a sample confirm")driver.execute_script("arguments[0].click();",element)wait=WebDriverWait(driver,timeout=2)alert=wait.until(lambdad:d.switch_to.alert)text=alert.textalert.dismiss()
//Click the link to activate the alertdriver.FindElement(By.LinkText("See a sample confirm")).Click();//Wait for the alert to be displayedwait.Until(ExpectedConditions.AlertIsPresent());//Store the alert in a variableIAlertalert=driver.SwitchTo().Alert();//Store the alert in a variable for reusestringtext=alert.Text;//Press the Cancel buttonalert.Dismiss();
# Store the alert reference in a variablealert=driver.switch_to.alert# Get the text of the alertalert.text# Press on Cancel buttonalert.dismiss
//Click the link to activate the alert
driver.findElement(By.linkText("See a sample confirm")).click()//Wait for the alert to be displayed
wait.until(ExpectedConditions.alertIsPresent())//Store the alert in a variable
valalert=driver.switchTo().alert()//Store the alert in a variable for reuse
valtext=alert.text//Press the Cancel button
alert.dismiss()
wait.until(ExpectedConditions.alertIsPresent());alert=driver.switchTo().alert();//Store the alert text in a variable and verify ittext=alert.getText();assertEquals(text,"What is your name?");//Type your messagealert.sendKeys("Selenium");//PresstheOKbutton
element=driver.find_element(By.LINK_TEXT,"See a sample prompt")driver.execute_script("arguments[0].click();",element)wait=WebDriverWait(driver,timeout=2)alert=wait.until(lambdad:d.switch_to.alert)alert.send_keys("Selenium")text=alert.textalert.accept()
//Click the link to activate the alertdriver.FindElement(By.LinkText("See a sample prompt")).Click();//Wait for the alert to be displayed and store it in a variableIAlertalert=wait.Until(ExpectedConditions.AlertIsPresent());//Type your messagealert.SendKeys("Selenium");//Press the OK buttonalert.Accept();
# Store the alert reference in a variablealert=driver.switch_to.alert# Type a messagealert.send_keys('selenium')# Press on Ok buttonalert.accept
//Click the link to activate the alert
driver.findElement(By.linkText("See a sample prompt")).click()//Wait for the alert to be displayed and store it in a variable
valalert=wait.until(ExpectedConditions.alertIsPresent())//Type your message
alert.sendKeys("Selenium")//Press the OK button
alert.accept()
driver.get("https://www.selenium.dev/selenium/web/blank.html");// Add cookie into current browser contextdriver.manage().addCookie(newCookie("key","value"));
driver=webdriver.Chrome()driver.get("http://www.example.com")# Adds the cookie into current browser contextdriver.add_cookie({"name":"key","value":"value"})
driver.Url="https://www.selenium.dev/selenium/web/blank.html";// Add cookie into current browser contextdriver.Manage().Cookies.AddCookie(newCookie("key","value"));
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'# Adds the cookie into current browser contextdriver.manage.add_cookie(name:"key",value:"value")ensuredriver.quitend
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")// Adds the cookie into current browser context
driver.manage().addCookie(Cookie("key","value"))}finally{driver.quit()}}
获取命名的 Cookie
此方法返回与cookie名称匹配的序列化cookie数据中所有关联的cookie.
driver.get("https://www.selenium.dev/selenium/web/blank.html");// Add cookie into current browser contextdriver.manage().addCookie(newCookie("foo","bar"));// Get cookie details with named cookie 'foo'Cookiecookie=driver.manage().getCookieNamed("foo");
driver=webdriver.Chrome()driver.get("http://www.example.com")# Adds the cookie into current browser contextdriver.add_cookie({"name":"foo","value":"bar"})# Get cookie details with named cookie 'foo'print(driver.get_cookie("foo"))
driver.Url="https://www.selenium.dev/selenium/web/blank.html";// Add cookie into current browser contextdriver.Manage().Cookies.AddCookie(newCookie("foo","bar"));// Get cookie details with named cookie 'foo'Cookiecookie=driver.Manage().Cookies.GetCookieNamed("foo");
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'driver.manage.add_cookie(name:"foo",value:"bar")# Get cookie details with named cookie 'foo'putsdriver.manage.cookie_named('foo')ensuredriver.quitend
awaitdriver.manage().addCookie({name:'foo',value:'bar'});// Get cookie details with named cookie 'foo'
awaitdriver.manage().getCookie('foo').then(function(cookie){
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")driver.manage().addCookie(Cookie("foo","bar"))// Get cookie details with named cookie 'foo'
valcookie=driver.manage().getCookieNamed("foo")println(cookie)}finally{driver.quit()}}
driver.get("https://www.selenium.dev/selenium/web/blank.html");// Add cookies into current browser contextdriver.manage().addCookie(newCookie("test1","cookie1"));driver.manage().addCookie(newCookie("test2","cookie2"));// Get cookiesSet<Cookie>cookies=driver.manage().getCookies();for(Cookiecookie:cookies){if(cookie.getName().equals("test1")){Assertions.assertEquals(cookie.getValue(),"cookie1");}if(cookie.getName().equals("test2")){Assertions.assertEquals(cookie.getValue(),"cookie2");}}
driver=webdriver.Chrome()driver.get("http://www.example.com")driver.add_cookie({"name":"test1","value":"cookie1"})driver.add_cookie({"name":"test2","value":"cookie2"})# Get all available cookiesprint(driver.get_cookies())
driver.Url="https://www.selenium.dev/selenium/web/blank.html";// Add cookies into current browser contextdriver.Manage().Cookies.AddCookie(newCookie("test1","cookie1"));driver.Manage().Cookies.AddCookie(newCookie("test2","cookie2"));// Get cookiesvarcookies=driver.Manage().Cookies.AllCookies;foreach(varcookieincookies){if(cookie.Name.Equals("test1")){Assert.AreEqual("cookie1",cookie.Value);}if(cookie.Name.Equals("test2")){Assert.AreEqual("cookie2",cookie.Value);}}
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'driver.manage.add_cookie(name:"test1",value:"cookie1")driver.manage.add_cookie(name:"test2",value:"cookie2")# Get all available cookiesputsdriver.manage.all_cookiesensuredriver.quitend
// Get all Available cookies
awaitdriver.manage().getCookies().then(function(cookies){
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")driver.manage().addCookie(Cookie("test1","cookie1"))driver.manage().addCookie(Cookie("test2","cookie2"))// Get All available cookies
valcookies=driver.manage().cookiesprintln(cookies)}finally{driver.quit()}}
driver=webdriver.Chrome()driver.get("http://www.example.com")driver.add_cookie({"name":"test1","value":"cookie1"})driver.add_cookie({"name":"test2","value":"cookie2"})# Delete cookie with name 'test1'driver.delete_cookie("test1")
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'driver.manage.add_cookie(name:"test1",value:"cookie1")driver.manage.add_cookie(name:"test2",value:"cookie2")# delete a cookie with name 'test1'driver.manage.delete_cookie('test1')ensuredriver.quitend
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")driver.manage().addCookie(Cookie("test1","cookie1"))valcookie1=Cookie("test2","cookie2")driver.manage().addCookie(cookie1)// delete a cookie with name 'test1'
driver.manage().deleteCookieNamed("test1")// delete cookie by passing cookie object of current browsing context.
driver.manage().deleteCookie(cookie1)}finally{driver.quit()}}
删除所有 Cookies
此方法删除当前访问上下文的所有cookie.
driver.get("https://www.selenium.dev/selenium/web/blank.html");// Add cookies into current browser contextdriver.manage().addCookie(newCookie("test1","cookie1"));driver.manage().addCookie(newCookie("test2","cookie2"));// Delete All cookiesdriver.manage().deleteAllCookies();
driver=webdriver.Chrome()driver.get("http://www.example.com")driver.add_cookie({"name":"test1","value":"cookie1"})driver.add_cookie({"name":"test2","value":"cookie2"})# Delete all cookiesdriver.delete_all_cookies()
driver.Url="https://www.selenium.dev/selenium/web/blank.html";// Add cookies into current browser contextdriver.Manage().Cookies.AddCookie(newCookie("test1","cookie1"));driver.Manage().Cookies.AddCookie(newCookie("test2","cookie2"));// Delete All cookiesdriver.Manage().Cookies.DeleteAllCookies();
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'driver.manage.add_cookie(name:"test1",value:"cookie1")driver.manage.add_cookie(name:"test2",value:"cookie2")# deletes all cookiesdriver.manage.delete_all_cookiesensuredriver.quitend
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")driver.manage().addCookie(Cookie("test1","cookie1"))driver.manage().addCookie(Cookie("test2","cookie2"))// deletes all cookies
driver.manage().deleteAllCookies()}finally{driver.quit()}}
driver=webdriver.Chrome()driver.get("http://www.example.com")# Adds the cookie into current browser context with sameSite 'Strict' (or) 'Lax'driver.add_cookie({"name":"foo","value":"value","sameSite":"Strict"})driver.add_cookie({"name":"foo1","value":"value","sameSite":"Lax"})cookie1=driver.get_cookie("foo")cookie2=driver.get_cookie("foo1")print(cookie1)print(cookie2)
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'# Adds the cookie into current browser context with sameSite 'Strict' (or) 'Lax'driver.manage.add_cookie(name:"foo",value:"bar",same_site:"Strict")driver.manage.add_cookie(name:"foo1",value:"bar",same_site:"Lax")putsdriver.manage.cookie_named('foo')putsdriver.manage.cookie_named('foo1')ensuredriver.quitend
awaitdriver.get('https://www.selenium.dev/selenium/web/blank.html');// set a cookie on the current domain with sameSite 'Strict' (or) 'Lax'
但是,如果 iframe 之外没有按钮,那么您可能会得到一个 no such element 无此元素 的错误。
这是因为 Selenium 只知道顶层文档中的元素。为了与按钮进行交互,我们需要首先切换到框架,
这与切换窗口的方式类似。WebDriver 提供了三种切换到帧的方法。
使用 WebElement
使用 WebElement 进行切换是最灵活的选择。您可以使用首选的选择器找到框架并切换到它。
//switch To IFrame using Web ElementWebElementiframe=driver.findElement(By.id("iframe1"));//Switch to the framedriver.switchTo().frame(iframe);assertEquals(true,driver.getPageSource().contains("We Leave From Here"));//Now we can type text into email fieldWebElementemailE=driver.findElement(By.id("email"));emailE.sendKeys("admin@selenium.dev");emailE.clear();
# --- Switch to iframe using WebElement ---iframe=driver.find_element(By.ID,"iframe1")driver.switch_to.frame(iframe)assert"We Leave From Here"indriver.page_sourceemail_element=driver.find_element(By.ID,"email")email_element.send_keys("admin@selenium.dev")email_element.clear()driver.switch_to.default_content()
//switch To IFrame using Web ElementIWebElementiframe=driver.FindElement(By.Id("iframe1"));//Switch to the framedriver.SwitchTo().Frame(iframe);Assert.AreEqual(true,driver.PageSource.Contains("We Leave From Here"));//Now we can type text into email fieldIWebElementemailE=driver.FindElement(By.Id("email"));emailE.SendKeys("admin@selenium.dev");emailE.Clear();
# Store iframe web elementiframe=driver.find_element(:css,'#modal> iframe')# 切换到 framedriver.switch_to.frameiframe# 单击按钮driver.find_element(:tag_name,'button').click
如果您的 frame 或 iframe 具有 id 或 name 属性,则可以使用该属性。如果名称或 id 在页面上不是唯一的,
那么将切换到找到的第一个。
//switch To IFrame using name or iddriver.findElement(By.name("iframe1-name"));//Switch to the framedriver.switchTo().frame(iframe);assertEquals(true,driver.getPageSource().contains("We Leave From Here"));WebElementemail=driver.findElement(By.id("email"));//Now we can type text into email fieldemail.sendKeys("admin@selenium.dev");email.clear();
# --- Switch to iframe using name or ID ---iframe1=driver.find_element(By.NAME,"iframe1-name")# (This line doesn't switch, just locates)driver.switch_to.frame(iframe)assert"We Leave From Here"indriver.page_sourceemail=driver.find_element(By.ID,"email")email.send_keys("admin@selenium.dev")email.clear()driver.switch_to.default_content()
//switch To IFrame using name or iddriver.FindElement(By.Name("iframe1-name"));//Switch to the framedriver.SwitchTo().Frame(iframe);Assert.AreEqual(true,driver.PageSource.Contains("We Leave From Here"));IWebElementemail=driver.FindElement(By.Id("email"));//Now we can type text into email fieldemail.SendKeys("admin@selenium.dev");email.Clear();
# Switch by IDdriver.switch_to.frame'buttonframe'# 单击按钮driver.find_element(:tag_name,'button').click
// 使用 ID
awaitdriver.switchTo().frame('buttonframe');// 或者使用 name 代替
awaitdriver.switchTo().frame('myframe');// 现在可以点击按钮
awaitdriver.findElement(By.css('button')).click();
// 使用 ID
driver.switchTo().frame("buttonframe")// 或者使用 name 代替
driver.switchTo().frame("myframe")// 现在可以点击按钮
driver.findElement(By.tagName("button")).click()
publicvoidTestRange(){IWebDriverdriver=newChromeDriver();driver.Navigate().GoToUrl("https://selenium.dev");PrintOptionsprintOptions=newPrintOptions();printOptions.AddPageRangeToPrint("1-3");// add range of pagesprintOptions.AddPageToPrint(5);// add individual page}
driver.get("https://www.selenium.dev/");PrintOptionsprintOptions=newPrintOptions();printOptions.setPageSize(newPageSize(27.94,21.59));// A4 size in cmdoublecurrentHeight=printOptions.getPageSize().getHeight();//usegetWidth()toretrievewidth
配置好打印选项后,就可以打印页面了。为此,您可以调用打印功能,生成网页的 PDF 表示形式。
生成的 PDF 文件可以保存到本地存储器中,以便进一步使用或分发。
使用 PrintsPage() 时,打印命令将以 base64 编码格式返回 PDF
数据,该格式可以解码并写入所需位置的文件,而使用 BrowsingContext() 时将返回字符串。
// Navigate to Urldriver.get("https://www.selenium.dev/selenium/web/window_switching_tests/page_with_frame.html");//fetch handle of thisStringcurrHandle=driver.getWindowHandle();assertNotNull(currHandle);
// Navigate to Urldriver.Url="https://www.selenium.dev/selenium/web/window_switching_tests/page_with_frame.html";//fetch handle of thisStringcurrHandle=driver.CurrentWindowHandle;Assert.IsNotNull(currHandle);
不过,Selenium 4 提供了一个新的 api NewWindow
它创建一个新选项卡 (或) 新窗口并自动切换到它。
//click on link to open a new windowdriver.findElement(By.linkText("Open new window")).click();//fetch handles of all windows, there will be two, [0]- default, [1] - new windowObject[]windowHandles=driver.getWindowHandles().toArray();driver.switchTo().window((String)windowHandles[1]);//assert on title of new windowStringtitle=driver.getTitle();assertEquals("Simple Page",title);
//click on link to open a new windowdriver.FindElement(By.LinkText("Open new window")).Click();//fetch handles of all windows, there will be two, [0]- default, [1] - new windowIList<string>windowHandles=newList<string>(driver.WindowHandles);driver.SwitchTo().Window(windowHandles[1]);//assert on title of new windowStringtitle=driver.Title;Assert.AreEqual("Simple Page",title);
//Opens a new tab and switches to new tabdriver.switchTo().newWindow(WindowType.TAB);assertEquals("",driver.getTitle());//Opens a new window and switches to new windowdriver.switchTo().newWindow(WindowType.WINDOW);assertEquals("",driver.getTitle());
//Opens a new tab and switches to new tabdriver.SwitchTo().NewWindow(WindowType.Tab);Assert.AreEqual("",driver.Title);//Opens a new window and switches to new windowdriver.SwitchTo().NewWindow(WindowType.Window);Assert.AreEqual("",driver.Title);
#Access each dimension individuallyx=driver.manage.window.position.xy=driver.manage.window.position.y# Or store the dimensions and query them laterrect=driver.manage.window.rectx1=rect.xy1=rect.y
fromseleniumimportwebdriverdriver=webdriver.Chrome()# Navigate to urldriver.get("http://www.example.com")# Returns and base64 encoded string into imagedriver.save_screenshot('./image.png')driver.quit()
usingOpenQA.Selenium;usingOpenQA.Selenium.Chrome;usingOpenQA.Selenium.Support.UI;vardriver=newChromeDriver();driver.Navigate().GoToUrl("http://www.example.com");Screenshotscreenshot=(driverasITakesScreenshot).GetScreenshot();screenshot.SaveAsFile("screenshot.png",ScreenshotImageFormat.Png);// Format values are Bmp, Gif, Jpeg, Png, Tiff
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://example.com/'# Takes and Stores the screenshot in specified pathdriver.save_screenshot('./image.png')end
// Captures the screenshot
letencodedString=awaitdriver.takeScreenshot();// save screenshot as below
// await fs.writeFileSync('./image.png', encodedString, 'base64');
fromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriver=webdriver.Chrome()# Navigate to urldriver.get("http://www.example.com")ele=driver.find_element(By.CSS_SELECTOR,'h1')# Returns and base64 encoded string into imageele.screenshot('./image.png')driver.quit()
usingOpenQA.Selenium;usingOpenQA.Selenium.Chrome;usingOpenQA.Selenium.Support.UI;// Webdrivervardriver=newChromeDriver();driver.Navigate().GoToUrl("http://www.example.com");// Fetch element using FindElementvarwebElement=driver.FindElement(By.CssSelector("h1"));// Screenshot for the elementvarelementScreenshot=(webElementasITakesScreenshot).GetScreenshot();elementScreenshot.SaveAsFile("screenshot_of_element.png");
# Works with Selenium4-alpha7 Ruby bindings and aboverequire'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://example.com/'ele=driver.find_element(:css,'h1')# Takes and Stores the element screenshot in specified pathele.save_screenshot('./image.jpg')end
letheader=awaitdriver.findElement(By.css('h1'));// Captures the element screenshot
letencodedString=awaitheader.takeScreenshot(true);// save screenshot as below
// await fs.writeFileSync('./image.png', encodedString, 'base64');
//Creating the JavascriptExecutor interface object by Type castingJavascriptExecutorjs=(JavascriptExecutor)driver;//Button ElementWebElementbutton=driver.findElement(By.name("btnLogin"));//Executing JavaScript to click on elementjs.executeScript("arguments[0].click();",button);//Get return value from scriptStringtext=(String)js.executeScript("return arguments[0].innerText",button);//Executing JavaScript directlyjs.executeScript("console.log('hello world')");
# Stores the header elementheader=driver.find_element(By.CSS_SELECTOR,"h1")# Executing JavaScript to capture innerText of header elementdriver.execute_script('return arguments[0].innerText',header)
//creating Chromedriver instanceIWebDriverdriver=newChromeDriver();//Creating the JavascriptExecutor interface object by Type castingIJavaScriptExecutorjs=(IJavaScriptExecutor)driver;//Button ElementIWebElementbutton=driver.FindElement(By.Name("btnLogin"));//Executing JavaScript to click on elementjs.ExecuteScript("arguments[0].click();",button);//Get return value from scriptStringtext=(String)js.ExecuteScript("return arguments[0].innerText",button);//Executing JavaScript directlyjs.ExecuteScript("console.log('hello world')");
# Stores the header elementheader=driver.find_element(css:'h1')# Get return value from scriptresult=driver.execute_script("return arguments[0].innerText",header)# Executing JavaScript directlydriver.execute_script("alert('hello world')")
// Stores the header element
letheader=awaitdriver.findElement(By.css('h1'));// Executing JavaScript to capture innerText of header element
lettext=awaitdriver.executeScript('return arguments[0].innerText',header);
// Stores the header element
valheader=driver.findElement(By.cssSelector("h1"))// Get return value from script
valresult=driver.executeScript("return arguments[0].innerText",header)// Executing JavaScript directly
driver.executeScript("alert('hello world')")
awaitdriver.get('https://www.selenium.dev/selenium/web/alerts.html');letbase64=awaitdriver.printPage({pageRanges:["1-2"]});// page can be saved as a PDF as below
// await fs.writeFileSync('./test.pdf', base64, 'base64');
options=VirtualAuthenticatorOptions()options.protocol=VirtualAuthenticatorOptions.Protocol.U2Foptions.has_resident_key=False# Register a virtual authenticatordriver.add_virtual_authenticator(options)
# parameters for Resident Credentialcredential_id=bytearray({1,2,3,4})rp_id="localhost"user_handle=bytearray({1})privatekey=urlsafe_b64decode(BASE64__ENCODED_PK)sign_count=0# create a resident credential using above parametersresident_credential=Credential.create_resident_credential(credential_id,rp_id,user_handle,privatekey,sign_count)
# parameters for Non Resident Credentialcredential_id=bytearray({1,2,3,4})rp_id="localhost"privatekey=urlsafe_b64decode(BASE64__ENCODED_PK)sign_count=0# create a non resident credential using above parameterscredential=Credential.create_non_resident_credential(credential_id,rp_id,privatekey,sign_count)
A Pen is a type of pointer input that has most of the same behavior as a mouse, but can
also have event properties unique to a stylus. Additionally, while a mouse
has 5 buttons, a pen has 3 equivalent button states:
0 — Touch Contact (the default; equivalent to a left click)
2 — Barrel Button (equivalent to a right click)
5 — Eraser Button (currently unsupported by drivers)
This is the most common scenario. Unlike traditional click and send keys methods,
the actions class does not automatically scroll the target element into view,
so this method will need to be used if elements are not already inside the viewport.
This method takes a web element as the sole argument.
Regardless of whether the element is above or below the current viewscreen,
the viewport will be scrolled so the bottom of the element is at the bottom of the screen.
This is the second most common scenario for scrolling. Pass in an delta x and a delta y value for how much to scroll
in the right and down directions. Negative values represent left and up, respectively.
This scenario is effectively a combination of the above two methods.
To execute this use the “Scroll From” method, which takes 3 arguments.
The first represents the origination point, which we designate as the element,
and the second two are the delta x and delta y values.
If the element is out of the viewport,
it will be scrolled to the bottom of the screen, then the page will be scrolled by the provided
delta x and delta y values.
This scenario is used when you need to scroll only a portion of the screen, and it is outside the viewport.
Or is inside the viewport and the portion of the screen that must be scrolled
is a known offset away from a specific element.
This uses the “Scroll From” method again, and in addition to specifying the element,
an offset is specified to indicate the origin point of the scroll. The offset is
calculated from the center of the provided element.
If the element is out of the viewport,
it first will be scrolled to the bottom of the screen, then the origin of the scroll will be determined
by adding the offset to the coordinates of the center of the element, and finally
the page will be scrolled by the provided delta x and delta y values.
Note that if the offset from the center of the element falls outside of the viewport,
it will result in an exception.
expect(in_viewport?(checkbox)).toeqtrueendit'scrolls by given amount with offset'dodriver.get('https://selenium.dev/selenium/web/scrolling_tests/frame_with_nested_scrolling_frame.html')
Scroll from a offset of origin (element) by given amount
The final scenario is used when you need to scroll only a portion of the screen,
and it is already inside the viewport.
This uses the “Scroll From” method again, but the viewport is designated instead
of an element. An offset is specified from the upper left corner of the
current viewport. After the origin point is determined,
the page will be scrolled by the provided delta x and delta y values.
Note that if the offset from the upper left corner of the viewport falls outside of the screen,
it will result in an exception.
These features are related to logging. Because “logging” can refer to so many different things, these methods are made available via a “script” namespace.
Remember that to use WebDriver BiDi, you must enable it in Options.
For more details, see Enabling BiDi
Page being translated from
English to Chinese. Do you speak Chinese? Help us to translate
it by sending us pull requests!
While Selenium 4 provides direct access to the Chrome DevTools Protocol, these
methods will eventually be removed when WebDriver BiDi implemented.
Basic authentication
Some applications make use of browser authentication to secure pages.
It used to be common to handle them in the URL, but browsers stopped supporting this.
With this code you can insert the credentials into the header when necessary
The following list of APIs will be growing as the WebDriver BiDirectional Protocol grows
and browser vendors implement the same.
Additionally, Selenium will try to support real-world use cases that internally use a combination of W3C BiDi protocol APIs.
If there is additional functionality you’d like to see, please raise a
feature request.
2.8.5.1 - Browsing Context
Page being translated from
English to Chinese. Do you speak Chinese? Help us to translate
it by sending us pull requests!
Commands
This section contains the APIs related to browsing context commands.
A reference browsing context is a top-level browsing context.
The API allows to pass the reference browsing context, which is used to create a new window. The implementation is operating system specific.
A reference browsing context is a top-level browsing context.
The API allows to pass the reference browsing context, which is used to create a new tab. The implementation is operating system specific.
Provides a tree of all browsing contexts descending from the parent browsing context, including the parent browsing context upto the depth value passed.
voidtestGetTreeWithDepth(){StringreferenceContextId=driver.getWindowHandle();BrowsingContextparentWindow=newBrowsingContext(driver,referenceContextId);parentWindow.navigate("https://www.selenium.dev/selenium/web/iframes.html",ReadinessState.COMPLETE);List<BrowsingContextInfo>contextInfoList=parentWindow.getTree(0);Assertions.assertEquals(1,contextInfoList.size());BrowsingContextInfoinfo=contextInfoList.get(0);Assertions.assertNull(info.getChildren());// since depth is 0Assertions.assertEquals(referenceContextId,info.getId());}
try(Networknetwork=newNetwork(driver)){network.addIntercept(newAddInterceptParameters(InterceptPhase.AUTH_REQUIRED));network.onAuthRequired(responseDetails->// Does not handle the alertnetwork.continueWithAuthNoCredentials(responseDetails.getRequest().getRequestId()));driver.get("https://the-internet.herokuapp.com/basic_auth");
try(Networknetwork=newNetwork(driver)){network.addIntercept(newAddInterceptParameters(InterceptPhase.AUTH_REQUIRED));network.onAuthRequired(responseDetails->// Does not handle the alertnetwork.cancelAuth(responseDetails.getRequest().getRequestId()));driver.get("https://the-internet.herokuapp.com/basic_auth");
constinspector=awaitLogInspector(driver)awaitinspector.onJavascriptException(function(log){logEntry=log})awaitdriver.get('https://www.selenium.dev/selenium/web/bidi/logEntryAdded.html')awaitdriver.findElement({id:'jsException'}).click()assert.equal(logEntry.text,'Error: Not working')assert.equal(logEntry.type,'javascript')assert.equal(logEntry.level,'error')
publicclassDriverClash{//thread main (id 1) created this driverprivateWebDriverprotectedDriver=ThreadGuard.protect(newChromeDriver());static{System.setProperty("webdriver.chrome.driver","<Set path to your Chromedriver>");}//Thread-1 (id 24) is calling the same driver causing the clash to happenRunnabler1=()->{protectedDriver.get("https://selenium.dev");};Threadthr1=newThread(r1);voidrunThreads(){thr1.start();}publicstaticvoidmain(String[]args){newDriverClash().runThreads();}}
结果如下所示:
Exception in thread "Thread-1" org.openqa.selenium.WebDriverException:
Thread safety error; this instance of WebDriver was constructed
on thread main (id 1)and is being accessed by thread Thread-1 (id 24)
This is not permitted and *will* cause undefined behaviour
请注意,此类仅适用于 HTML 元素 select 和 option.
这个类将不适用于那些通过 div 或 li
并使用JavaScript遮罩层设计的下拉列表.
类型
选择方法的行为可能会有所不同,
具体取决于正在使用的 <select> 元素的类型.
单选
这是标准的下拉对象,其只能选定一个选项.
<selectname="selectomatic"><optionselected="selected"id="non_multi_option"value="one">One</option><optionvalue="two">Two</option><optionvalue="four">Four</option><optionvalue="still learning how to count, apparently">Still learning how to count, apparently</option></select>
This exception occurs when Selenium tries to click an element, but the click would instead
be received by a different element. Before Selenium will click an element, it checks if the
element is visible, unobscured by any other elements, and enabled - if the element is obscured,
it will raise this exception.
Likely Cause
UI Elements Overlapping
Elements on the UI are typically placed next to each other, but occasionally elements may overlap.
For example, a navbar always staying at the top of your window as you scroll a page. If that navbar
happens to be covering an element we are trying to click, Selenium might believe it to be visible
and enabled, but when you try to click it will throw this exception. Pop-ups and Modals are also
common offenders here.
Animations
Elements with animations have the potential to cause this exception as well - it is recommended
to wait for animations to cease before attempting to click an element.
Possible Solutions
Use Explicit Waits
Explicit Waits will likely be your best friend
in these instances. A great way is to use ExpectedCondition.ToBeClickable()
with WebDriverWait to wait until the right moment.
Scroll the Element into View
In instances where the element is out of view, but Selenium still registers the element as visible
(e.g. navbars overlapping a section at the top of your screen), you can use the
WebDriver.executeScript() method to execute a javascript function to scroll
(e.g. WebDriver.executeScript('window.scrollBy(0,-250)')) or you can utilize the
Actions class with Actions.moveToElement(element).
隐藏的元素:元素存在于 DOM 中,但由于 CSS、hidden 属性或元素超出可见视口范围而不可见。
可能的解决方案
根据元素类型使用适当的操作(例如,仅对 <input> 字段使用 sendKeys)。
确保定位器唯一标识目标元素,以避免错误匹配。
在与元素交互之前,检查其是否在页面上可见。如果需要,将元素滚动到视图中。
使用显式等待以确保元素在执行操作前可交互。
2.10.1.1 - Unable to Locate Driver Error
Troubleshooting missing path to driver executable.
Historically, this is the most common error beginning Selenium users get
when trying to run code for the first time:
The path to the driver executable must
be set by the webdriver.chrome.driver system property;
for more information, see https://chromedriver.chromium.org/.
The latest version can be downloaded from https://chromedriver.chromium.org/downloads
The executable chromedriver needs to be available in the path.
The file geckodriver does not exist. The driver can be downloaded at https://github.com/mozilla/geckodriver/releases"
Unable to locate the chromedriver executable;
Likely cause
Through WebDriver, Selenium supports all major browsers.
In order to drive the requested browser, Selenium needs to
send commands to it via an executable driver.
This error means the necessary driver could not be
found by any of the means Selenium attempts to use.
Possible solutions
There are several ways to ensure Selenium gets the driver it needs.
Use the latest version of Selenium
As of Selenium 4.6, Selenium downloads the correct driver for you.
You shouldn’t need to do anything. If you are using the latest version
of Selenium and you are getting an error,
please turn on logging
and file a bug report with that information.
If you want to read more information about how Selenium manages driver downloads for you,
you can read about the Selenium Manager.
This is a flexible option to change location of drivers without having to update your code,
and will work on multiple machines without requiring that each machine put the
drivers in the same place.
You can either place the drivers in a directory that is already listed in PATH,
or you can place them in a directory and add it to PATH.
To see what directories are already on PATH, open a Terminal and execute:
echo$PATH
If the location to your driver is not already in a directory listed,
you can add a new directory to PATH:
You can test if it has been added correctly by checking the version of the driver:
chromedriver --version
To see what directories are already on PATH, open a Command Prompt and execute:
echo %PATH%
If the location to your driver is not already in a directory listed,
you can add a new directory to PATH:
setx PATH "%PATH%;C:\WebDriver\bin"
You can test if it has been added correctly by checking the version of the driver:
chromedriver.exe --version
Specify the location of the driver
If you cannot upgrade to the latest version of Selenium, you
do not want Selenium to download drivers for you, and you can’t figure
out the environment variables, you can specify the location of the driver in the Service object.
Specifying the location in the code itself has the advantage of not needing
to figure out Environment Variables on your system, but has the drawback of
making the code less flexible.
Driver management libraries
Before Selenium managed drivers itself, other projects were created to
do so for you.
If you can’t use Selenium Manager because you are using
an older version of Selenium (please upgrade),
or need an advanced feature not yet implemented by Selenium Manager,
you might try one of these tools to keep your drivers automatically updated:
Python logs are typically created per module. You can match all submodules by referencing the top
level module. So to work with all loggers in selenium module, you can do this:
.NET logger is managed with a static class, so all access to logging is managed simply by referencing Log from the OpenQA.Selenium.Internal.Logging namespace.
If you want to see as much debugging as possible in all the classes,
you can turn on debugging globally in Ruby by setting $DEBUG = true.
For more fine-tuned control, Ruby Selenium created its own Logger class to wrap the default Logger class.
This implementation provides some interesting additional features.
Obtain the logger directly from the #loggerclass method on the Selenium::WebDriver module:
Things get complicated when you use PyTest, though. By default, PyTest hides logging unless the test
fails. You need to set 3 things to get PyTest to display logs on passing tests.
To always output logs with PyTest you need to run with additional arguments.
First, -s to prevent PyTest from capturing the console.
Second, -p no:logging, which allows you to override the default PyTest logging settings so logs can
be displayed regardless of errors.
So you need to set these flags in your IDE, or run PyTest on command line like:
pytest -s -p no:logging
Finally, since you turned off logging in the arguments above, you now need to add configuration to
turn it back on:
logging.basicConfig(level=logging.WARN)
.NET has 6 logger levels: Error, Warn, Info, Debug, Trace and None. The default level is Info.
Ruby’s logger allows you to opt in (“allow”) or opt out (“ignore”) of log messages based on their IDs.
Everything that Selenium logs includes an ID. You can also turn on or off all deprecation notices by
using :deprecations.
These methods accept one or more symbols or an array of symbols:
<dependencies><!-- more dependencies ... --><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>3.141.59</version></dependency><!-- more dependencies ... --></dependencies>
After
<dependencies><!-- more dependencies ... --><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.4.0</version></dependency><!-- more dependencies ... --></dependencies>
Browser name: chrome, firefox, edge, iexplorer, safari, safaritp, or webview2
--driver <DRIVER>
driver = "DRIVER"
SE_DRIVER=DRIVER
Driver name: chromedriver, geckodriver, msedgedriver, IEDriverServer, or safaridriver
--browser-version <BROWSER_VERSION>
browser-version = "BROWSER_VERSION"
SE_BROWSER_VERSION=BROWSER_VERSION
Major browser version (e.g., 105, 106, etc. Also: beta, dev, canary -or nightly-, and esr -in Firefox- are accepted)
--driver-version <DRIVER_VERSION>
driver-version = "DRIVER_VERSION"
SE_DRIVER_VERSION=DRIVER_VERSION
Driver version (e.g., 106.0.5249.61, 0.31.0, etc.)
--browser-path <BROWSER_PATH>
browser-path = "BROWSER_PATH"
SE_BROWSER_PATH=BROWSER_PATH
Browser path (absolute) for browser version detection (e.g., /usr/bin/google-chrome, /Applications/Google Chrome.app/Contents/MacOS/Google Chrome, C:\Program Files\Google\Chrome\Application\chrome.exe)
--driver-mirror-url <DRIVER_MIRROR_URL>
driver-mirror-url = "DRIVER_MIRROR_URL"
SE_DRIVER_MIRROR_URL=DRIVER_MIRROR_URL
Mirror URL for driver repositories
--browser-mirror-url <BROWSER_MIRROR_URL>
browser-mirror-url = "BROWSER_MIRROR_URL"
SE_BROWSER_MIRROR_URL=BROWSER_MIRROR_URL
Mirror URL for browser repositories
--output <OUTPUT>
output = "OUTPUT"
SE_OUTPUT=OUTPUT
Output type: LOGGER (using INFO, WARN, etc.), JSON (custom JSON notation), SHELL (Unix-like), or MIXED (INFO, WARN, DEBUG, etc. to stderr and minimal JSON to stdout). Default: LOGGER
--os <OS>
os = "OS"
SE_OS=OS
Operating system for drivers and browsers (i.e., windows, linux, or macos)
--arch <ARCH>
arch = "ARCH"
SE_ARCH=ARCH
System architecture for drivers and browsers (i.e., x32, x64, or arm64)
--proxy <PROXY>
proxy = "PROXY"
SE_PROXY=PROXY
HTTP proxy for network connection (e.g., myproxy:port, myuser:mypass@myproxy:port)
--timeout <TIMEOUT>
timeout = TIMEOUT
SE_TIMEOUT=TIMEOUT
Timeout for network requests (in seconds). Default: 300
--offline
offline = true
SE_OFFLINE=true
Offline mode (i.e., disabling network requests and downloads)
--force-browser-download
force-browser-download = true
SE_FORCE_BROWSER_DOWNLOAD=true
Force to download browser, e.g., when a browser is already installed in the system, but you want Selenium Manager to download and use it
--avoid-browser-download
avoid-browser-download = true
SE_AVOID_BROWSER_DOWNLOAD=true
Avoid to download browser, e.g., when a browser is supposed to be downloaded by Selenium Manager, but you prefer to avoid it
--debug
debug = true
SE_DEBUG=true
Display DEBUG messages
--trace
trace = true
SE_TRACE=true
Display TRACE messages
--cache-path <CACHE_PATH>
cache-path="CACHE_PATH"
SE_CACHE_PATH=CACHE_PATH
Local folder used to store downloaded assets (drivers and browsers), local metadata, and configuration file. See next section for details. Default: ~/.cache/selenium. For Windows paths in the TOML configuration file, double backslashes are required (e.g., C:\\custom\\cache).
--ttl <TTL>
ttl = TTL
SE_TTL=TTL
Time-to-live in seconds. See next section for details. Default: 3600 (1 hour)
--language-binding <LANGUAGE>
language-binding = "LANGUAGE"
SE_LANGUAGE_BINDING=LANGUAGE
Language that invokes Selenium Manager (e.g., Java, JavaScript, Python, DotNet, Ruby)
--avoid-stats
avoid-stats = true
SE_AVOID_STATS=true
Avoid sends usage statistics to plausible.io. Default: false
$ ./selenium-manager --browser chrome --browser-version beta --debug
DEBUG chromedriver not found in PATH
DEBUG chrome not found in PATH
DEBUG chrome beta not found in the system
DEBUG Discovering versions from https://googlechromelabs.github.io/chrome-for-testing/last-known-good-versions-with-downloads.json
DEBUG Required browser: chrome 117.0.5938.22
DEBUG Downloading chrome 117.0.5938.22 from https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/117.0.5938.22/win64/chrome-win64.zip
DEBUG chrome 117.0.5938.22 has been downloaded at C:\Users\boni\.cache\selenium\chrome\win64\117.0.5938.22\chrome.exe
DEBUG Discovering versions from https://googlechromelabs.github.io/chrome-for-testing/known-good-versions-with-downloads.json
DEBUG Required driver: chromedriver 117.0.5938.22
DEBUG Downloading chromedriver 117.0.5938.22 from https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/117.0.5938.22/win64/chromedriver-win64.zip
INFO Driver path: C:\Users\boni\.cache\selenium\chromedriver\win64\117.0.5938.22\chromedriver.exe
INFO Browser path: C:\Users\boni\.cache\selenium\chrome\win64\117.0.5938.22\chrome.exe
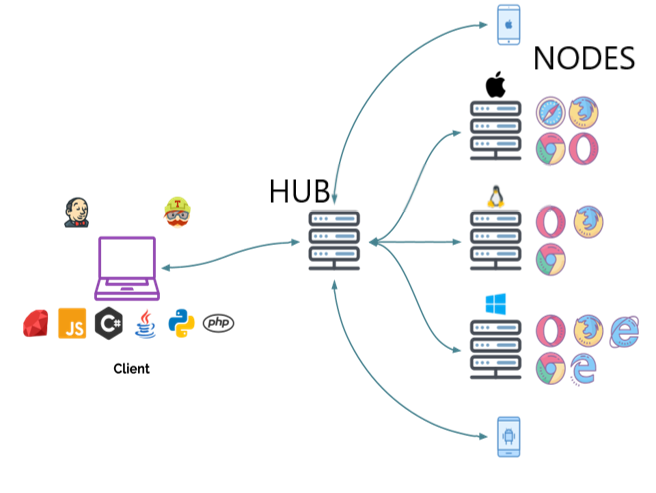
ChromeOptionschromeOptions=newChromeOptions();chromeOptions.setCapability("browserVersion","100");chromeOptions.setCapability("platformName","Windows");// Showing a test name instead of the session id in the Grid UIchromeOptions.setCapability("se:name","My simple test");// Other type of metadata can be seen in the Grid UI by clicking on the // session info or via GraphQLchromeOptions.setCapability("se:sampleMetadata","Sample metadata value");WebDriverdriver=newRemoteWebDriver(newURL("http://gridUrl:4444"),chromeOptions);driver.get("http://www.google.com");driver.quit();
Page being translated from
English to Chinese. Do you speak Chinese? Help us to translate
it by sending us pull requests!
Different sections are available to configure a Grid. Each section has options can be configured
through command line arguments.
A complete description of the component to section mapping can be seen below.
Note that this documentation could be outdated if an option was modified or added
but has not been documented yet. In case you bump into this situation, please check
the “Config help” section and feel free to send us a
pull request updating this page.
Full class name of non-default distributor implementation
--distributor-port
int
5553
Port on which the distributor is listening.
--reject-unsupported-caps
boolean
false
Allow the Distributor to reject a request immediately if the Grid does not support the requested capability. Rejecting requests immediately is suitable for a Grid setup that does not spin up Nodes on demand.
--slot-matcher
string
org.openqa.selenium.grid.data.DefaultSlotMatcher
Full class name of non-default slot matcher to use. This is used to determine whether a Node can support a particular session.
Full class name of non-default slot selector. This is used to select a slot in a Node once the Node has been matched.
--newsession-threadpool-size
int
24
The Distributor uses a fixed-sized thread pool to create new sessions as it consumes new session requests from the queue. This allows configuring the size of the thread pool. The default value is no. of available processors * 3. Note: If the no. of threads is way greater than the available processors it will not always increase the performance. A high number of threads causes more context switching which is an expensive operation.
--purge-nodes-interval
int
30
How often, in seconds, will the Distributor purge Nodes that have been down for a while. This is calculated based on the heartbeat received from a particular node.
Docker configs which map image name to stereotype capabilities (example `-D selenium/standalone-firefox:latest ‘{“browserName”: “firefox”}’)
--docker-devices
string[]
/dev/kvm:/dev/kvm
Exposes devices to a container. Each device mapping declaration must have at least the path of the device in both host and container separated by a colon like in this example: /device/path/in/host:/device/path/in/container
--docker-host
string
localhost
Host name where the Docker daemon is running
--docker-port
int
2375
Port where the Docker daemon is running
--docker-url
string
http://localhost:2375
URL for connecting to the Docker daemon
--docker-video-image
string
selenium/video:latest
Docker image to be used when video recording is enabled
--docker-host-config-keys
string[]
Dns DnsOptions DnsSearch ExtraHosts Binds
Specify which docker host configuration keys should be passed to browser containers. Keys name can be found in the Docker API documentation, or by running docker inspect the node-docker container.
Events
Option
Type
Value/Example
Description
--bind-bus
boolean
false
Whether the connection string should be bound or connected. When true, the component will be bound to the Event Bus (as in the Event Bus will also be started by the component, typically by the Distributor and the Hub). When false, the component will connect to the Event Bus.
--events-implementation
string
org.openqa.selenium.events.zeromq.ZeroMqEventBus
Full class name of non-default event bus implementation
--publish-events
string
tcp://*:4442
Connection string for publishing events to the event bus
--subscribe-events
string
tcp://*:4443
Connection string for subscribing to events from the event bus
Logging
Option
Type
Value/Example
Description
--http-logs
boolean
false
Enable http logging. Tracing should be enabled to log http logs.
--log-encoding
string
UTF-8
Log encoding
--log
string
Windows path example : '\path\to\file\gridlog.log' or 'C:\path\path\to\file\gridlog.log'
Linux/Unix/MacOS path example : '/path/to/file/gridlog.log'
File to write out logs. Ensure the file path is compatible with the operating system’s file path.
Full classname of non-default Node implementation. This is used to manage a session’s lifecycle.
--grid-url
string
https://grid.example.com
Public URL of the Grid as a whole (typically the address of the Hub or the Router)
--heartbeat-period
int
60
How often, in seconds, will the Node send heartbeat events to the Distributor to inform it that the Node is up.
--max-sessions
int
8
Maximum number of concurrent sessions. Default value is the number of available processors.
--override-max-sessions
boolean
false
The # of available processors is the recommended max sessions value (1 browser session per processor). Setting this flag to true allows the recommended max value to be overwritten. Session stability and reliability might suffer as the host could run out of resources.
--register-cycle
int
10
How often, in seconds, the Node will try to register itself for the first time to the Distributor.
--register-period
int
120
How long, in seconds, will the Node try to register to the Distributor for the first time. After this period is completed, the Node will not attempt to register again.
--session-timeout
int
300
Let X be the session-timeout in seconds. The Node will automatically kill a session that has not had any activity in the last X seconds. This will release the slot for other tests.
--vnc-env-var
string[]
SE_START_XVFB SE_START_VNC SE_START_NO_VNC
Environment variable to check in order to determine if a vnc stream is available or not.
--no-vnc-port
int
7900
If VNC is available, sets the port where the local noVNC stream can be obtained
--drain-after-session-count
int
1
Drain and shutdown the Node after X sessions have been executed. Useful for environments like Kubernetes. A value higher than zero enables this feature.
--hub
string
http://localhost:4444
The address of the Hub in a Hub-and-Node configuration. Can be a hostname or IP address (hostname), in which case the Hub will be assumed to be http://hostname:4444, the --grid-url will be the same --publish-events will be tcp://hostname:4442 and --subscribe-events will be tcp://hostname:4443. If hostname contains a port number, that will be used for --grid-url but the URIs for the event bus will remain the same. Any of these default values may be overridden but setting the correct flags. If the hostname has a protocol (such as https) that will be used too.
--enable-cdp
boolean
true
Enable CDP proxying in Grid. A Grid admin can disable CDP if the network doesnot allow websockets. True by default.
--enable-managed-downloads
boolean
false
This causes the Node to auto manage files downloaded for a given session on the Node.
--selenium-manager
boolean
false
When drivers are not available on the current system, use Selenium Manager. False by default.
--connection-limit-per-session
int
10
Let X be the maximum number of websocket connections per session.This will ensure one session is not able to exhaust the connection limit of the host.
Relay
Option
Type
Value/Example
Description
--service-url
string
http://localhost:4723
URL for connecting to the service that supports WebDriver commands like an Appium server or a cloud service.
--service-host
string
localhost
Host name where the service that supports WebDriver commands is running
--service-port
int
4723
Port where the service that supports WebDriver commands is running
--service-status-endpoint
string
/status
Optional, endpoint to query the WebDriver service status, an HTTP 200 response is expected
--service-protocol-version
string
HTTP/1.1
Optional, enforce a specific protocol version in HttpClient when communicating with the endpoint service status
Configuration for the service where calls will be relayed to. It is recommended to provide this type of configuration through a toml config file to improve readability.
Router
Option
Type
Value/Example
Description
--password
string
myStrongPassword
Password clients must use to connect to the server. Both this and the username need to be set in order to be used.
--username
string
admin
User name clients must use to connect to the server. Both this and the password need to be set in order to be used.
--sub-path
string
my_company/selenium_grid
A sub-path that should be considered for all user facing routes on the Hub/Router/Standalone.
--disable-ui
boolean
true
Disable the Grid UI.
Server
Option
Type
Value/Example
Description
--allow-cors
boolean
true
Whether the Selenium server should allow web browser connections from any host
--host
string
localhost
Server IP or hostname: usually determined automatically.
--bind-host
boolean
true
Whether the server should bind to the host address/name, or only use it to" report its reachable url. Helpful in complex network topologies where the server cannot report itself with the current IP/hostname but rather an external IP or hostname (e.g. inside a Docker container)
--https-certificate
path
/path/to/cert.pem
Server certificate for https. Get more detailed information by running “java -jar selenium-server.jar info security”
--https-private-key
path
/path/to/key.pkcs8
Private key for https. Get more detailed information by running “java -jar selenium-server.jar info security”
--max-threads
int
24
Maximum number of listener threads. Default value is: (available processors) * 3.
--port
int
4444
Port to listen on. There is no default as this parameter is used by different components, for example, Router/Hub/Standalone will use 4444 and Node will use 5555.
SessionQueue
Option
Type
Value/Example
Description
--sessionqueue
uri
http://localhost:1237
Address of the session queue server.
-sessionqueue-host
string
localhost
Host on which the session queue server is listening.
--sessionqueue-port
int
1234
Port on which the session queue server is listening.
--session-request-timeout
int
300
Timeout in seconds. A new incoming session request is added to the queue. Requests sitting in the queue for longer than the configured time will timeout.
--session-retry-interval
int
5
Retry interval in seconds. If all slots are busy, new session request will be retried after the given interval.
--maximum-response-delay
int
8
How often, in seconds, will the the SessionQueue response in case there is no data, to reduce the http requests while polling for new session requests.
Sessions
Option
Type
Value/Example
Description
--sessions
uri
http://localhost:1234
Address of the session map server.
--sessions-host
string
localhost
Host on which the session map server is listening.
--sessions-port
int
1234
Port on which the session map server is listening.
Configuration examples
All the options mentioned above can be used when starting the Grid components. They are a good
way of exploring the Grid options, and trying out values to find a suitable configuration.
We recommend the use of Toml files to configure a Grid.
Configuration files improve readability, and you can also check them in source control.
When needed, you can combine a Toml file configuration with CLI arguments.
Command-line flags
To pass config options as command-line flags, identify the valid options for the component
and follow the template below.
java -jar selenium-server-<version>.jar <component> --<option> value
The Grid infrastructure will try to match a session request with "se:downloadsEnabled" against ONLY those nodes which were started with --enable-managed-downloads true
If a session is matched, then the Node automatically sets the required capabilities to let the browser know, as to where should a file be downloaded.
The Node now allows a user to:
List all the files that were downloaded for a specific session and
Retrieve a specific file from the list of files.
The directory into which files were downloaded for a specific session gets automatically cleaned up when the session ends (or) timesout due to inactivity.
Note: Currently this capability is ONLY supported on:
Edge
Firefox and
Chrome browser
Listing files that can be downloaded for current session:
The endpoint to GET from is /session/<sessionId>/se/files.
The session needs to be active in order for the command to work.
contents - Base64 encoded zipped contents of the file.
The file contents are Base64 encoded and they need to be unzipped.
List files that can be downloaded
The below mentioned curl example can be used to list all the files that were downloaded by the current session in the Node, and which can be retrieved locally.
curl -X GET "http://localhost:4444/session/90c0149a-2e75-424d-857a-e78734943d4c/se/files"
Below is an example in Java that does the following:
Sets the capability to indicate that the test requires automatic managing of downloaded files.
Triggers a file download via a browser.
Lists the files that are available for retrieval from the remote node (These are essentially files that were downloaded in the current session)
Picks one file and downloads the file from the remote node to the local machine.
importcom.google.common.collect.ImmutableMap;importorg.openqa.selenium.By;importorg.openqa.selenium.io.Zip;importorg.openqa.selenium.json.Json;importorg.openqa.selenium.remote.RemoteWebDriver;importorg.openqa.selenium.remote.http.HttpClient;importorg.openqa.selenium.remote.http.HttpRequest;importorg.openqa.selenium.remote.http.HttpResponse;importjava.io.File;importjava.net.URL;importjava.nio.file.Files;importjava.util.List;importjava.util.Map;importjava.util.Optional;importjava.util.concurrent.TimeUnit;import staticorg.openqa.selenium.remote.http.Contents.asJson;import staticorg.openqa.selenium.remote.http.Contents.string;import staticorg.openqa.selenium.remote.http.HttpMethod.GET;import staticorg.openqa.selenium.remote.http.HttpMethod.POST;publicclassDownloadsSample{publicstaticvoidmain(String[]args)throwsException{// Assuming the Grid is running locally.URLgridUrl=newURL("http://localhost:4444");ChromeOptionsoptions=newChromeOptions();options.setCapability("se:downloadsEnabled",true);RemoteWebDriverdriver=newRemoteWebDriver(gridUrl,options);try{demoFileDownloads(driver,gridUrl);}finally{driver.quit();}}privatestaticvoiddemoFileDownloads(RemoteWebDriverdriver,URLgridUrl)throwsException{driver.get("https://www.selenium.dev/selenium/web/downloads/download.html");// Download the two available files on the pagedriver.findElement(By.id("file-1")).click();driver.findElement(By.id("file-2")).click();// The download happens in a remote Node, which makes it difficult to know when the file// has been completely downloaded. For demonstration purposes, this example uses a// 10-second sleep which should be enough time for a file to be downloaded.// We strongly recommend to avoid hardcoded sleeps, and ideally, to modify your// application under test, so it offers a way to know when the file has been completely// downloaded.TimeUnit.SECONDS.sleep(10);//This is the endpoint which will provide us with list of files to download and also to//let us download a specific file.StringdownloadsEndpoint=String.format("/session/%s/se/files",driver.getSessionId());StringfileToDownload;try(HttpClientclient=HttpClient.Factory.createDefault().createClient(gridUrl)){// To list all files that are were downloaded on the remote node for the current session// we trigger GET request.HttpRequestrequest=newHttpRequest(GET,downloadsEndpoint);HttpResponseresponse=client.execute(request);Map<String,Object>jsonResponse=newJson().toType(string(response),Json.MAP_TYPE);@SuppressWarnings("unchecked")Map<String,Object>value=(Map<String,Object>)jsonResponse.get("value");@SuppressWarnings("unchecked")List<String>names=(List<String>)value.get("names");// Let's say there were "n" files downloaded for the current session, we would like// to retrieve ONLY the first file.fileToDownload=names.get(0);}// Now, let's download the filetry(HttpClientclient=HttpClient.Factory.createDefault().createClient(gridUrl)){// To retrieve a specific file from one or more files that were downloaded by the current session// on a remote node, we use a POST request.HttpRequestrequest=newHttpRequest(POST,downloadsEndpoint);request.setContent(asJson(ImmutableMap.of("name",fileToDownload)));HttpResponseresponse=client.execute(request);Map<String,Object>jsonResponse=newJson().toType(string(response),Json.MAP_TYPE);@SuppressWarnings("unchecked")Map<String,Object>value=(Map<String,Object>)jsonResponse.get("value");// The returned map would contain 2 keys,// filename - This represents the name of the file (same as what was provided by the test)// contents - Base64 encoded String which contains the zipped file.StringzippedContents=value.get("contents").toString();// The file contents would always be a zip file and has to be unzipped.FiledownloadDir=Zip.unzipToTempDir(zippedContents,"download","");// Read the file contentsFiledownloadedFile=Optional.ofNullable(downloadDir.listFiles()).orElse(newFile[]{})[0];StringfileContent=String.join("",Files.readAllLines(downloadedFile.toPath()));System.out.println("The file which was "+"downloaded in the node is now available in the directory: "+downloadDir.getAbsolutePath()+" and has the contents: "+fileContent);}}}
[node]detect-drivers=falsemax-sessions=2[docker]configs=["selenium/standalone-chrome:93.0","{\"browserName\": \"chrome\", \"browserVersion\": \"91\"}","selenium/standalone-firefox:92.0","{\"browserName\": \"firefox\", \"browserVersion\": \"92\"}"]#Optionally define all device files that should be mapped to docker containers#devices = [# "/dev/kvm:/dev/kvm"#]url="http://localhost:2375"video-image="selenium/video:latest"
[node]detect-drivers=false[relay]# Default Appium/Cloud server endpointurl="http://localhost:4723/wd/hub"status-endpoint="/status"# Optional, enforce a specific protocol version in HttpClient when communicating with the endpoint service status (e.g. HTTP/1.1, HTTP/2)protocol-version="HTTP/1.1"# Stereotypes supported by the service. The initial number is "max-sessions", and will allocate # that many test slots to that particular configurationconfigs=["5","{\"browserName\": \"chrome\", \"platformName\": \"android\", \"appium:platformVersion\": \"11\"}"]
The Node can be instructed to manage downloads automatically. This will cause the Node to save all files that were downloaded for a particular session into a temp directory, which can later be retrieved from the node.
To turn this capability on, use the below configuration:
Page being translated from
English to Chinese. Do you speak Chinese? Help us to translate
it by sending us pull requests!
The Grid is designed as a set of components that all fulfill a role in
maintaining the Grid. It can seem quite complicated, but hopefully
this document can help clear up any confusion.
The Key Components
The main components of the Grid are:
Event Bus
Used for sending messages which may be received asynchronously
between the other components.
New Session Queue
Maintains a list of incoming sessions which have yet to be
assigned to a Node by the Distributor.
Distributor
Responsible for maintaining a model of the available locations in
the Grid where a session may run (known as "slots") and taking any
incoming new
session requests and assigning them to a slot.
Node
Runs a WebDriver
session. Each session is assigned to a slot, and each node has
one or more slots.
Session Map
Maintains a mapping between the session
ID and the address of the Node the session is running on.
Router
Acts as the front-end of the Grid. This is the only part of the
Grid which may be exposed to the wider Web (though we strongly
caution against it). This routes incoming requests to either the
New Session Queue or the Node on which the session is running.
While discussing the Grid, there are some other useful concepts to
keep in mind:
A slot is the place where a session can run.
Each slot has a stereotype. This is the minimal set of
capabilities that a new session session request must match
before the Distributor will send that request to the Node owning
the slot.
The Grid Model is how the Distributor tracks the state of the
Grid. As the name suggests, this may sometimes fall out of sync
with reality (perhaps because the Distributor has only just
started). It is used in preference to querying each Node so that
the Distributor can quickly assign a slot to a New Session request.
Synchronous and Asynchronous Calls
There are two main communication mechanisms used within the Grid:
Synchronous “REST-ish” JSON over HTTP requests.
Asynchronous events sent to the Event Bus.
How do we pick which communication mechanism to use? After all, we
could model the entire Grid in an event-based way, and it would work
out just fine.
The answer is that if the action being performed is synchronous
(eg. most WebDriver calls), or if missing the response would be
problematic, the Grid uses a synchronous call. If, instead, we want to
broadcast information to anyone who’s interested, or if missing the
response doesn’t matter, then we prefer to use the event bus.
One interesting thing to note is that the async calls are more
decoupled from their listeners than the synchronous calls are.
Start Up Sequence and Dependencies Between Components
Although the Grid is designed to allow components to start up in any
order, conceptually the order in which components starts is:
The Event Bus and Session Map start first. These have no other
dependencies, not even on each other, and so are safe to start in
parallel.
The Session Queue starts next.
It is now possible to start the Distributor. This will periodically
connect to the Session Queue and poll for jobs, though this polling
might be initiated either by an event (that a New Session has been
added to the queue) or at regular intervals.
The Router(s) can be started. New Session requests will be directed
to the Session Queue, and the Distributor will attempt to find a
slot to run the session on.
We are now able to start a Node. See below for details about how
the Node is registered with the Grid. Once registration is
complete, the Grid is ready to serve traffic.
You can picture the dependencies between components this way, where a
“✅” indicates that there is a synchronous dependency between the
components.
Event Bus
Distributor
Node
Router
Session Map
Session Queue
Event Bus
X
Distributor
✅
X
✅
✅
Node
✅
X
Router
✅
X
✅
Session Map
X
Session Queue
✅
X
Node Registration
The process of registering a new Node to the Grid is lightweight.
When the Node starts, it should emit a “heart beat” event on a
regular basis. This heartbeat contains the node status.
The Distributor listens for the heart beat events. When it sees
one, it attempts to GET the /status endpoint of the Node. It
is from this information that the Grid is set up.
The Distributor will use the same /status endpoint to check the Node
on a regular basis, but the Node should continue sending heart beat
events even after started so that a Distributor without a persistent
store of the Grid state can be restarted and will (eventually) be up
to date and correct.
The Node Status Object
The Node Status is a JSON blob with the following fields:
Name
Type
Description
availability
string
A string which is one of up, draining, or down. The important one is draining, which indicates that no new sessions should be sent to the Node, and once the last session on it closes, the Node will exit or restart.
externalUrl
string
The URI that the other components in the Grid should connect to.
lastSessionCreated
integer
The epoch timestamp of when the last session was created on this Node. The Distributor will attempt to send new sessions to the Node that has been idle longest if all other things are equal.
maxSessionCount
integer
Although a session count can be inferred by counting the number of available slots, this integer value is used to determine the maximum number of sessions that should be running simultaneously on the Node before it is considered “full”.
nodeId
string
A UUID used to identify this instance of the Node.
osInfo
object
An object with arch, name, and version fields. This is used by the Grid UI and the GraphQL queries.
slots
array
An array of Slot objects (described below)
version
string
The version of the Node (for Selenium, this will match the Selenium version number)
It is recommended to put values in all fields.
The Slot Object
The Slot object represents a single slot within a Node. A “slot” is
where a single session may be run. It is possible that a Node will
have more slots than it can run concurrently. For example, a node may
be able to run up 10 sessions, but they could be any combination of
Chrome, Edge, or Firefox; in this case, the Node would indicate a “max
session count” of 10, and then also say it has 10 slots for Chrome, 10
for Edge, and 10 for Firefox.
Name
Type
Description
id
string
UUID to refer to the slot
lastStarted
string
When the slot last had a session started, in ISO-8601 format
stereotype
object
The minimal set of capabilities this slot will match against. A minimal example is {"browserName": "firefox"}
session
object
The Session object (see below)
The Session Object
This represents a running session within a slot
Name
Type
Description
capabilities
object
The actual capabilities provided by the session. Will match the return value from the new session command
startTime
string
The start time of the session in ISO-8601 format
stereotype
object
The minimal set of capabilities this slot will match against. A minimal example is {"browserName": "firefox"}
uri
string
The URI used by the Node to communicate with the session
4.6 - 高级功能
要获得高级功能的所有详细信息, 了解其工作原理, 以及如何设置自己的功能, 请浏览以下部分.
4.6.1 - 可观测性
Page being translated from
English to Chinese. Do you speak Chinese? Help us to translate
it by sending us pull requests!
Grid aids in scaling and distributing tests by executing tests on various browser and operating system combinations.
Observability
Observability has three pillars: traces, metrics and logs. Since Selenium Grid 4 is designed to be fully distributed, observability will make it easier to understand and debug the internals.
Distributed tracing
A single request or transaction spans multiple services and components. Tracing tracks the request lifecycle as each service executes the request. It is useful in debugging in an error scenario.
Some key terms used in tracing context are:
Trace
Tracing allows one to trace a request through multiple services, starting from its origin to its final destination. This request’s journey helps in debugging, monitoring the end-to-end flow, and identifying failures. A trace depicts the end-to-end request flow. Each trace has a unique id as its identifier.
Span
Each trace is made up of timed operations called spans. A span has a start and end time and it represents operations done by a service. The granularity of span depends on how it is instrumented. Each span has a unique identifier. All spans within a trace have the same trace id.
Span Attributes
Span attributes are key-value pairs which provide additional information about each span.
Events
Events are timed-stamped logs within a span. They provide additional context to the existing spans. Events also contain key-value pairs as event attributes.
Event logging
Logging is essential to debug an application. Logging is often done in a human-readable format. But for machines to search and analyze the logs, it has to have a well-defined format. Structured logging is a common practice of recording logs consistently in a fixed format. It commonly contains fields like:
Timestamp
Logging level
Logger class
Log message (This is further broken down into fields relevant to the operation where the log was recorded)
Logs and events are closely related. Events encapsulate all the possible information available to do a single unit of work. Logs are essentially subsets of an event. At the crux, both aid in debugging.
Refer following resources for detailed understanding:
Selenium server is instrumented with tracing using OpenTelemetry. Every request to the server is traced from start to end. Each trace consists of a series of spans as a request is executed within the server.
Most spans in the Selenium server consist of two events:
Normal event - records all information about a unit of work and marks successful completion of the work.
Error event - records all information till the error occurs and then records the error information. Marks an exception event.
All spans, events and their respective attributes are part of a trace. Tracing works while running the server in all of the above-mentioned modes.
By default, tracing is enabled in the Selenium server. Selenium server exports the traces via two exporters:
Console - Logs all traces and their included spans at FINE level. By default, Selenium server prints logs at INFO level and above.
The log-level flag can be used to pass a logging level of choice while running the Selenium Grid jar/s.
java -jar selenium-server-4.0.0-<selenium-version>.jar standalone --log-level FINE
Jaeger UI - OpenTelemetry provides the APIs and SDKs to instrument traces in the code. Whereas Jaeger is a tracing backend, that aids in collecting the tracing telemetry data and providing querying, filtering and visualizing features for the data.
Detailed instructions of visualizing traces using Jaeger UI can be obtained by running the command :
java -jar selenium-server-4.0.0-<selenium-version>.jar info tracing
Tracing has to be enabled for event logging as well, even if one does not wish to export traces to visualize them. By default, tracing is enabled. No additional parameters need to be passed to see logs on the console.
All events within a span are logged at FINE level. Error events are logged at WARN level.
All event logs have the following fields :
Field
Field value
Description
Event time
eventId
Timestamp of the event record in epoch nanoseconds.
Trace Id
tracedId
Each trace is uniquely identified by a trace id.
Span Id
spanId
Each span within a trace is uniquely identified by a span id.
Span Kind
spanKind
Span kind is a property of span indicating the type of span. It helps in understanding the nature of the unit of work done by the Span.
Event name
eventName
This maps to the log message.
Event attributes
eventAttributes
This forms the crux of the event logs, based on the operation executed, it has JSON formatted key-value pairs. This also includes a handler class attribute, to show the logger class.
New Session Request Queue holds the new session requests.
To get the current requests in the queue, use the cURL command enlisted below.
The response returns the total number of requests in the queue and the request payloads.
新会话请求队列保存新会话请求.
要获取队列中的当前请求,
请使用下面列出的cURL命令.
响应会返回队列中的请求总数以及请求内容.
cURL --request GET 'http://localhost:4444/se/grid/newsessionqueue/queue'
在完全分布式模式下,
队列URL是新会话队列服务器的地址.
cURL --request GET 'http://localhost:4444/se/grid/newsessionqueue/queue'
4.6.4 - Customizing a Node
Page being translated from
English to Chinese. Do you speak Chinese? Help us to translate
it by sending us pull requests!
How to customize a Node
There are times when we would like a Node to be customized to our needs.
For e.g., we may like to do some additional setup before a session begins execution and some clean-up after a session runs to completion.
Following steps can be followed for this:
Create a class that extends org.openqa.selenium.grid.node.Node
Add a static method (this will be our factory method) to the newly created class whose signature looks like this:
public static Node create(Config config). Here:
Node is of type org.openqa.selenium.grid.node.Node
Config is of type org.openqa.selenium.grid.config.Config
Within this factory method, include logic for creating your new Class.
To wire in this new customized logic into the hub, start the node and pass in the fully qualified class name of the above class to the argument --node-implementation
Let’s see an example of all this:
Custom Node as an uber jar
Create a sample project using your favourite build tool (Maven|Gradle).
Note: If you are using Maven as a build tool, please prefer using maven-shade-plugin instead of maven-assembly-plugin because maven-assembly plugin seems to have issues with being able to merge multiple Service Provider Interface files (META-INF/services)
Custom Node as a regular jar
Create a sample project using your favourite build tool (Maven|Gradle).
Below is a sample that just prints some messages on to the console whenever there’s an activity of interest (session created, session deleted, a webdriver command executed etc.,) on the Node.
Sample customized node
packageorg.seleniumhq.samples;importjava.net.URI;importjava.util.UUID;importorg.openqa.selenium.Capabilities;importorg.openqa.selenium.NoSuchSessionException;importorg.openqa.selenium.WebDriverException;importorg.openqa.selenium.grid.config.Config;importorg.openqa.selenium.grid.data.CreateSessionRequest;importorg.openqa.selenium.grid.data.CreateSessionResponse;importorg.openqa.selenium.grid.data.NodeId;importorg.openqa.selenium.grid.data.NodeStatus;importorg.openqa.selenium.grid.data.Session;importorg.openqa.selenium.grid.log.LoggingOptions;importorg.openqa.selenium.grid.node.HealthCheck;importorg.openqa.selenium.grid.node.Node;importorg.openqa.selenium.grid.node.local.LocalNodeFactory;importorg.openqa.selenium.grid.security.Secret;importorg.openqa.selenium.grid.security.SecretOptions;importorg.openqa.selenium.grid.server.BaseServerOptions;importorg.openqa.selenium.internal.Either;importorg.openqa.selenium.remote.SessionId;importorg.openqa.selenium.remote.http.HttpRequest;importorg.openqa.selenium.remote.http.HttpResponse;importorg.openqa.selenium.remote.tracing.Tracer;publicclassDecoratedLoggingNodeextendsNode{privateNodenode;protectedDecoratedLoggingNode(Tracertracer,NodeIdnodeId,URIuri,SecretregistrationSecret,DurationsessionTimeout){super(tracer,nodeId,uri,registrationSecret,sessionTimeout);}publicstaticNodecreate(Configconfig){LoggingOptionsloggingOptions=newLoggingOptions(config);BaseServerOptionsserverOptions=newBaseServerOptions(config);URIuri=serverOptions.getExternalUri();SecretOptionssecretOptions=newSecretOptions(config);NodeOptionsnodeOptions=newNodeOptions(config);DurationsessionTimeout=nodeOptions.getSessionTimeout();// Refer to the foot notes for additional context on this line.Nodenode=LocalNodeFactory.create(config);DecoratedLoggingNodewrapper=newDecoratedLoggingNode(loggingOptions.getTracer(),node.getId(),uri,secretOptions.getRegistrationSecret(),sessionTimeout);wrapper.node=node;returnwrapper;}@OverridepublicEither<WebDriverException,CreateSessionResponse>newSession(CreateSessionRequestsessionRequest){System.out.println("Before newSession()");try{returnthis.node.newSession(sessionRequest);}finally{System.out.println("After newSession()");}}@OverridepublicHttpResponseexecuteWebDriverCommand(HttpRequestreq){try{System.out.println("Before executeWebDriverCommand(): "+req.getUri());returnnode.executeWebDriverCommand(req);}finally{System.out.println("After executeWebDriverCommand()");}}@OverridepublicSessiongetSession(SessionIdid)throwsNoSuchSessionException{try{System.out.println("Before getSession()");returnnode.getSession(id);}finally{System.out.println("After getSession()");}}@OverridepublicHttpResponseuploadFile(HttpRequestreq,SessionIdid){try{System.out.println("Before uploadFile()");returnnode.uploadFile(req,id);}finally{System.out.println("After uploadFile()");}}@Overridepublicvoidstop(SessionIdid)throwsNoSuchSessionException{try{System.out.println("Before stop()");node.stop(id);}finally{System.out.println("After stop()");}}@OverridepublicbooleanisSessionOwner(SessionIdid){try{System.out.println("Before isSessionOwner()");returnnode.isSessionOwner(id);}finally{System.out.println("After isSessionOwner()");}}@OverridepublicbooleanisSupporting(Capabilitiescapabilities){try{System.out.println("Before isSupporting");returnnode.isSupporting(capabilities);}finally{System.out.println("After isSupporting()");}}@OverridepublicNodeStatusgetStatus(){try{System.out.println("Before getStatus()");returnnode.getStatus();}finally{System.out.println("After getStatus()");}}@OverridepublicHealthCheckgetHealthCheck(){try{System.out.println("Before getHealthCheck()");returnnode.getHealthCheck();}finally{System.out.println("After getHealthCheck()");}}@Overridepublicvoiddrain(){try{System.out.println("Before drain()");node.drain();}finally{System.out.println("After drain()");}}@OverridepublicbooleanisReady(){try{System.out.println("Before isReady()");returnnode.isReady();}finally{System.out.println("After isReady()");}}}
Foot Notes:
In the above example, the line Node node = LocalNodeFactory.create(config); explicitly creates a LocalNode.
There are basically 2 types of user facing implementations of org.openqa.selenium.grid.node.Node available.
These classes are good starting points to learn how to build a custom Node and also to learn the internals of a Node.
org.openqa.selenium.grid.node.local.LocalNode - Used to represent a long running Node and is the default implementation that gets wired in when you start a node.
It can be created by calling LocalNodeFactory.create(config);, where:
LocalNodeFactory belongs to org.openqa.selenium.grid.node.local
Config belongs to org.openqa.selenium.grid.config
org.openqa.selenium.grid.node.k8s.OneShotNode - This is a special reference implementation wherein the Node gracefully shuts itself down after servicing one test session. This class is currently not available as part of any pre-built maven artifact.
You can refer to the source code here to understand its internals.
Selenium Grid allows you to persist information related to currently running sessions into an external data store.
The external data store could be backed by your favourite database (or) Redis Cache system.
Setup
Coursier - As a dependency resolver, so that we can download maven artifacts on the fly and make them available in our classpath
Docker - To manage our PostGreSQL/Redis docker containers.
Database backed Session Map
For the sake of this illustration, we are going to work with PostGreSQL database.
We will spin off a PostGreSQL database as a docker container using a docker compose file.
Steps
You can skip this step if you already have a PostGreSQL database instance available at your disposal.
Create a sql file named init.sql with the below contents:
We can now start our database container by running:
docker-compose up -d
Our database name is selenium_sessions with its username and password set to seluser
If you are working with an already running PostGreSQL DB instance, then you just need to create a database named selenium_sessions and the table sessions_map using the above mentioned SQL statement.
Create a Selenium Grid configuration file named sessions.toml with the below contents:
At this point the current directory should contain the following files:
docker-compose.yml
init.sql
sessions.toml
distributed.sh
You can now spawn the Grid by running distributed.sh shell script and quickly run a test. You will notice that the Grid now stores session information into the PostGreSQL database.
In the line which spawns a SessionMap on a machine:
At this point the current directory should contain the following files:
docker-compose.yml
sessions.toml
distributed.sh
You can now spawn the Grid by running distributed.sh shell script and quickly run a test. You will notice that the Grid now stores session information into the Redis instance. You can perhaps make use of a Redis GUI such as TablePlus to see them (Make sure that you have setup a debug point in your test, because the values will get deleted as soon as the test runs to completion).
In the line which spawns a SessionMap on a machine:
We use the W3C WebDriver protocol to communicate with a local instance of an HTTP server. This greatly simplifies the implementation of the language-specific code, and minimzes the number of entry points into the C++ DLL that must be called using a native-code interop technology such as JNA, ctypes, pinvoke or DL.
Memory Management
The IE driver utilizes the Active Template Library (ATL) to take advantage of its implementation of smart pointers to COM objects. This makes reference counting and cleanup of COM objects much easier.
Why Do We Require Protected Mode Settings Changes?
IE 7 on Windows Vista introduced the concept of Protected Mode, which allows for some measure of protection to the underlying Windows OS when browsing. The problem is that when you manipulate an instance of IE via COM, and you navigate to a page that would cause a transition into or out of Protected Mode, IE requires that another browser session be created. This will orphan the COM object of the previous session, not allowing you to control it any longer.
In IE 7, this will usually manifest itself as a new top-level browser window; in IE 8, a new IExplore.exe process will be created, but it will usually (not always!) seamlessly attach it to the existing IE top-level frame window. Any browser automation framework that drives IE externally (as opposed to using a WebBrowser control) will run into these problems.
In order to work around that problem, we dictate that to work with IE, all zones must have the same Protected Mode setting. As long as it’s on for all zones, or off for all zones, we can prevent the transistions to different Protected Mode zones that would invalidate our browser object. It also allows users to continue to run with UAC turned on, and to run securely in the browser if they set Protected Mode “on” for all zones.
In earlier releases of the IE driver, if the user’s Protected Mode settings were not correctly set, we would launch IE, and the process would simply hang until the HTTP request timed out. This was suboptimal, as it gave no indication what needed to be set. Erring on the side of caution, we do not modify the user’s Protected Mode settings. Current versions, however check that the Protected Mode settings are properly set, and will return an error response if they are not.
There are two ways that we could simulate keyboard and mouse input. The first way, which is used in parts of webdriver, is to synthesize events on the DOM. This has a number of drawbacks, since each browser (and version of a browser) has its own unique quirks; to model each of these is a demanding task, and impossible to get completely right (for example, it’s hard to tell what window.selection should be and this is a read-only property on some browsers) The alternative approach is to synthesize keyboard and mouse input at the OS level, ideally without stealing focus from the user (who tends to be doing other things on their computer as long-running webdriver tests run)
The code for doing this is in interactions.cpp The key thing to note here is that we use PostMessages to push window events on to the message queue of the IE instance. Typing, in particular, is interesting: we only send the “keydown” and “keyup” messages. The “keypress” event is created if necessary by IE’s internal event processing. Because the key press event is not always generated (for example, not every character is printable, and if the default event bubbling is cancelled, listeners don’t see the key press event) we send a “probe” event in after the key down. Once we see that this has been processed, we know that the key press event is on the stack of events to be processed, and that it is safe to send the key up event. If this was not done, it is possible for events to fire in the wrong order, which is definitely sub-optimal.
Working On the InternetExplorerDriver
Currently, there are tests that will run for the InternetExplorerDriver in all languages (Java, C#, Python, and Ruby), so you should be able to test your changes to the native code no matter what language you’re comfortable working in from the client side. For working on the C++ code, you’ll need Visual Studio 2010 Professional or higher. Unfortunately, the C++ code of the driver uses ATL to ease the pain of working with COM objects, and ATL is not supplied with Visual C++ 2010 Express Edition. If you’re using Eclipse, the process for making and testing modifications is:
Edit the C++ code in VS.
Build the code to ensure that it compiles
Do a complete rebuild when you are ready to run a test. This will cause the created DLL to be copied to the right place to allow its use in Eclipse
Load Eclipse (or some other IDE, such as Idea)
Edit the SingleTestSuite so that it is usingDriver(IE)
Create a JUnit run configuration that uses the “webdriver-internet-explorer” project. If you don’t do this, the test won’t work at all, and there will be a somewhat cryptic error message on the console.
Once the basic setup is done, you can start working on the code pretty quickly. You can attach to the process you execute your code from using Visual Studio (from the Debug menu, select Attach to Process…).
不管您如何回答这个问题,
解决方案是让它成为测试中“设置数据”部分的一部分 - 如果 Larry 公开了一个 API,
使您(或任何人)能够创建和更新用户帐户,
一定要用它来回答这个问题
请确保使用这个 API 来回答这个问题 — 如果可能的话,
您希望只有在您拥有一个用户之后才启动浏览器,您可以使用该用户的凭证进行登录。
如果每个工作流的每个测试都是从创建用户帐户开始的,那么每个测试的执行都会增加许多秒。
调用 API 并与数据库进行通信是快速、“无头”的操作,
不需要打开浏览器、导航到正确页面、点击并等待表单提交等昂贵的过程。
理想情况下,您可以在一行代码中处理这个设置阶段,这些代码将在任何浏览器启动之前执行:
// Create a user who has read-only permissions--they can configure a unicorn,// but they do not have payment information set up, nor do they have// administrative privileges. At the time the user is created, its email// address and password are randomly generated--you don't even need to// know them.Useruser=UserFactory.createCommonUser();//This method is defined elsewhere.// Log in as this user.// Logging in on this site takes you to your personal "My Account" page, so the// AccountPage object is returned by the loginAs method, allowing you to then// perform actions from the AccountPage.AccountPageaccountPage=loginAs(user.getEmail(),user.getPassword());
# Create a user who has read-only permissions--they can configure a unicorn,# but they do not have payment information set up, nor do they have# administrative privileges. At the time the user is created, its email# address and password are randomly generated--you don't even need to# know them.user=user_factory.create_common_user()#This method is defined elsewhere.# Log in as this user.# Logging in on this site takes you to your personal "My Account" page, so the# AccountPage object is returned by the loginAs method, allowing you to then# perform actions from the AccountPage.account_page=login_as(user.get_email(),user.get_password())
// Create a user who has read-only permissions--they can configure a unicorn,// but they do not have payment information set up, nor do they have// administrative privileges. At the time the user is created, its email// address and password are randomly generated--you don't even need to// know them.Useruser=UserFactory.CreateCommonUser();//This method is defined elsewhere.// Log in as this user.// Logging in on this site takes you to your personal "My Account" page, so the// AccountPage object is returned by the loginAs method, allowing you to then// perform actions from the AccountPage.AccountPageaccountPage=LoginAs(user.Email,user.Password);
# Create a user who has read-only permissions--they can configure a unicorn,# but they do not have payment information set up, nor do they have# administrative privileges. At the time the user is created, its email# address and password are randomly generated--you don't even need to# know them.user=UserFactory.create_common_user#This method is defined elsewhere.# Log in as this user.# Logging in on this site takes you to your personal "My Account" page, so the# AccountPage object is returned by the loginAs method, allowing you to then# perform actions from the AccountPage.account_page=login_as(user.email,user.password)
// Create a user who has read-only permissions--they can configure a unicorn,
// but they do not have payment information set up, nor do they have
// administrative privileges. At the time the user is created, its email
// address and password are randomly generated--you don't even need to
// know them.
varuser=userFactory.createCommonUser();//This method is defined elsewhere.
// Log in as this user.
// Logging in on this site takes you to your personal "My Account" page, so the
// AccountPage object is returned by the loginAs method, allowing you to then
// perform actions from the AccountPage.
varaccountPage=loginAs(user.email,user.password);
// Create a user who has read-only permissions--they can configure a unicorn,
// but they do not have payment information set up, nor do they have
// administrative privileges. At the time the user is created, its email
// address and password are randomly generated--you don't even need to
// know them.
valuser=UserFactory.createCommonUser()//This method is defined elsewhere.
// Log in as this user.
// Logging in on this site takes you to your personal "My Account" page, so the
// AccountPage object is returned by the loginAs method, allowing you to then
// perform actions from the AccountPage.
valaccountPage=loginAs(user.getEmail(),user.getPassword())
请注意,我们在该段落中没有讨论按钮,字段,下拉菜单,单选按钮或 Web 表单。
您的测试也不应该!
您希望像尝试解决问题的用户一样编写代码。
这是一种方法(从前面的例子继续):
// The Unicorn is a top-level Object--it has attributes, which are set here.// This only stores the values; it does not fill out any web forms or interact// with the browser in any way.Unicornsparkles=newUnicorn("Sparkles",UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS);// Since we're already "on" the account page, we have to use it to get to the// actual place where you configure unicorns. Calling the "Add Unicorn" method// takes us there.AddUnicornPageaddUnicornPage=accountPage.addUnicorn();// Now that we're on the AddUnicornPage, we will pass the "sparkles" object to// its createUnicorn() method. This method will take Sparkles' attributes,// fill out the form, and click submit.UnicornConfirmationPageunicornConfirmationPage=addUnicornPage.createUnicorn(sparkles);
# The Unicorn is a top-level Object--it has attributes, which are set here.# This only stores the values; it does not fill out any web forms or interact# with the browser in any way.sparkles=Unicorn("Sparkles",UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS)# Since we're already "on" the account page, we have to use it to get to the# actual place where you configure unicorns. Calling the "Add Unicorn" method# takes us there.add_unicorn_page=account_page.add_unicorn()# Now that we're on the AddUnicornPage, we will pass the "sparkles" object to# its createUnicorn() method. This method will take Sparkles' attributes,# fill out the form, and click submit.unicorn_confirmation_page=add_unicorn_page.create_unicorn(sparkles)
// The Unicorn is a top-level Object--it has attributes, which are set here. // This only stores the values; it does not fill out any web forms or interact// with the browser in any way.Unicornsparkles=newUnicorn("Sparkles",UnicornColors.Purple,UnicornAccessories.Sunglasses,UnicornAdornments.StarTattoos);// Since we are already "on" the account page, we have to use it to get to the// actual place where you configure unicorns. Calling the "Add Unicorn" method// takes us there.AddUnicornPageaddUnicornPage=accountPage.AddUnicorn();// Now that we're on the AddUnicornPage, we will pass the "sparkles" object to// its createUnicorn() method. This method will take Sparkles' attributes,// fill out the form, and click submit.UnicornConfirmationPageunicornConfirmationPage=addUnicornPage.CreateUnicorn(sparkles);
# The Unicorn is a top-level Object--it has attributes, which are set here.# This only stores the values; it does not fill out any web forms or interact# with the browser in any way.sparkles=Unicorn.new('Sparkles',UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS)# Since we're already "on" the account page, we have to use it to get to the# actual place where you configure unicorns. Calling the "Add Unicorn" method# takes us there.add_unicorn_page=account_page.add_unicorn# Now that we're on the AddUnicornPage, we will pass the "sparkles" object to# its createUnicorn() method. This method will take Sparkles' attributes,# fill out the form, and click submit.unicorn_confirmation_page=add_unicorn_page.create_unicorn(sparkles)
// The Unicorn is a top-level Object--it has attributes, which are set here.
// This only stores the values; it does not fill out any web forms or interact
// with the browser in any way.
varsparkles=newUnicorn("Sparkles",UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS);// Since we are already "on" the account page, we have to use it to get to the
// actual place where you configure unicorns. Calling the "Add Unicorn" method
// takes us there.
varaddUnicornPage=accountPage.addUnicorn();// Now that we're on the AddUnicornPage, we will pass the "sparkles" object to
// its createUnicorn() method. This method will take Sparkles' attributes,
// fill out the form, and click submit.
varunicornConfirmationPage=addUnicornPage.createUnicorn(sparkles);
// The Unicorn is a top-level Object--it has attributes, which are set here.
// This only stores the values; it does not fill out any web forms or interact
// with the browser in any way.
valsparkles=Unicorn("Sparkles",UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS)// Since we are already "on" the account page, we have to use it to get to the
// actual place where you configure unicorns. Calling the "Add Unicorn" method
// takes us there.
valaddUnicornPage=accountPage.addUnicorn()// Now that we're on the AddUnicornPage, we will pass the "sparkles" object to
// its createUnicorn() method. This method will take Sparkles' attributes,
// fill out the form, and click submit.
unicornConfirmationPage=addUnicornPage.createUnicorn(sparkles)
既然您已经配置好了独角兽,
您需要进入第三步:确保它确实有效。
// The exists() method from UnicornConfirmationPage will take the Sparkles// object--a specification of the attributes you want to see, and compare// them with the fields on the page.Assert.assertTrue("Sparkles should have been created, with all attributes intact",unicornConfirmationPage.exists(sparkles));
# The exists() method from UnicornConfirmationPage will take the Sparkles# object--a specification of the attributes you want to see, and compare# them with the fields on the page.assertunicorn_confirmation_page.exists(sparkles),"Sparkles should have been created, with all attributes intact"
// The exists() method from UnicornConfirmationPage will take the Sparkles // object--a specification of the attributes you want to see, and compare// them with the fields on the page.Assert.True(unicornConfirmationPage.Exists(sparkles),"Sparkles should have been created, with all attributes intact");
# The exists() method from UnicornConfirmationPage will take the Sparkles# object--a specification of the attributes you want to see, and compare# them with the fields on the page.expect(unicorn_confirmation_page.exists?(sparkles)).tobe,'Sparkles should have been created, with all attributes intact'
// The exists() method from UnicornConfirmationPage will take the Sparkles
// object--a specification of the attributes you want to see, and compare
// them with the fields on the page.
assert(unicornConfirmationPage.exists(sparkles),"Sparkles should have been created, with all attributes intact");
// The exists() method from UnicornConfirmationPage will take the Sparkles
// object--a specification of the attributes you want to see, and compare
// them with the fields on the page.
assertTrue("Sparkles should have been created, with all attributes intact",unicornConfirmationPage.exists(sparkles))
Most of the documentation found in this section is still in English.
Please note we are not accepting pull requests to translate this content
as translating documentation of legacy components does not add value to
the community nor the project.
Over time, projects tend to accumulate large numbers of tests. As the total number of tests increases,
it becomes harder to make changes to the codebase — a single “simple” change may
cause numerous tests to fail, even though the application still works properly.
Sometimes these problems are unavoidable, but when they do occur you want to be
up and running again as quickly as possible. The following design patterns and
strategies have been used before with WebDriver to help to make tests easier to write and maintain. They may help you too.
DomainDrivenDesign: Express your tests in the language of the end-user of the app.
PageObjects: A simple abstraction of the UI of your web app.
LoadableComponent: Modeling PageObjects as components.
BotStyleTests: Using a command-based approach to automating tests, rather than the object-based approach that PageObjects encourage
Loadable Component
What Is It?
The LoadableComponent is a base class that aims to make writing PageObjects
less painful. It does this by providing a standard way of ensuring that pages
are loaded and providing hooks to make debugging the failure of a page to load
easier. You can use it to help reduce the amount of boilerplate code in your
tests, which in turn make maintaining your tests less tiresome.
There is currently an implementation in Java that ships as part of Selenium 2,
but the approach used is simple enough to be implemented in any language.
Simple Usage
As an example of a UI that we’d like to model, take a look at
the new issue page.
From the point of view of a test author, this offers the service of being
able to file a new issue. A basic Page Object would look like:
In order to turn this into a LoadableComponent, all we need to do is to set that as the base type:
publicclassEditIssueextendsLoadableComponent<EditIssue>{// rest of class ignored for now}
This signature looks a little unusual, but it all means is that
this class represents a LoadableComponent that loads the EditIssue page.
By extending this base class, we need to implement two new methods:
@Overrideprotectedvoidload(){driver.get("https://github.com/SeleniumHQ/selenium/issues/new?assignees=&labels=I-defect%2Cneeds-triaging&projects=&template=bug-report.yml&title=%5B%F0%9F%90%9B+Bug%5D%3A+");}@OverrideprotectedvoidisLoaded()throwsError{Stringurl=driver.getCurrentUrl();assertTrue("Not on the issue entry page: "+url,url.endsWith("/new"));}
The load method is used to navigate to the page, whilst the isLoaded method
is used to determine whether we are on the right page. Although the
method looks like it should return a boolean, instead it performs a
series of assertions using JUnit’s Assert class. There can be as
few or as many assertions as you like. By using these assertions
it’s possible to give users of the class clear information that
can be used to debug tests.
With a little rework, our PageObject looks like:
packagecom.example.webdriver;importorg.openqa.selenium.By;importorg.openqa.selenium.WebDriver;importorg.openqa.selenium.WebElement;importorg.openqa.selenium.support.FindBy;importorg.openqa.selenium.support.PageFactory;import staticjunit.framework.Assert.assertTrue;publicclassEditIssueextendsLoadableComponent<EditIssue>{privatefinalWebDriverdriver;// By default the PageFactory will locate elements with the same name or id// as the field. Since the issue_title element has an id attribute of "issue_title"// we don't need any additional annotations.privateWebElementissue_title;// But we'd prefer a different name in our code than "issue_body", so we use the// FindBy annotation to tell the PageFactory how to locate the element.@FindBy(id="issue_body")privateWebElementbody;publicEditIssue(WebDriverdriver){this.driver=driver;// This call sets the WebElement fields.PageFactory.initElements(driver,this);}@Overrideprotectedvoidload(){driver.get("https://github.com/SeleniumHQ/selenium/issues/new?assignees=&labels=I-defect%2Cneeds-triaging&projects=&template=bug-report.yml&title=%5B%F0%9F%90%9B+Bug%5D%3A+");}@OverrideprotectedvoidisLoaded()throwsError{Stringurl=driver.getCurrentUrl();assertTrue("Not on the issue entry page: "+url,url.endsWith("/new"));}publicvoidsetHowToReproduce(StringhowToReproduce){WebElementfield=driver.findElement(By.id("issue_form_repro-command"));clearAndType(field,howToReproduce);}publicvoidsetLogOutput(StringlogOutput){WebElementfield=driver.findElement(By.id("issue_form_logs"));clearAndType(field,logOutput);}publicvoidsetOperatingSystem(StringoperatingSystem){WebElementfield=driver.findElement(By.id("issue_form_operating-system"));clearAndType(field,operatingSystem);}publicvoidsetSeleniumVersion(StringseleniumVersion){WebElementfield=driver.findElement(By.id("issue_form_selenium-version"));clearAndType(field,logOutput);}publicvoidsetBrowserVersion(StringbrowserVersion){WebElementfield=driver.findElement(By.id("issue_form_browser-versions"));clearAndType(field,browserVersion);}publicvoidsetDriverVersion(StringdriverVersion){WebElementfield=driver.findElement(By.id("issue_form_browser-driver-versions"));clearAndType(field,driverVersion);}publicvoidsetUsingGrid(StringusingGrid){WebElementfield=driver.findElement(By.id("issue_form_selenium-grid-version"));clearAndType(field,usingGrid);}publicIssueListsubmit(){driver.findElement(By.cssSelector("button[type='submit']")).click();returnnewIssueList(driver);}privatevoidclearAndType(WebElementfield,Stringtext){field.clear();field.sendKeys(text);}}
That doesn’t seem to have bought us much, right? One thing it has done
is encapsulate the information about how to navigate to the page into
the page itself, meaning that this information’s not scattered through
the code base. It also means that we can do this in our tests:
EditIssuepage=newEditIssue(driver).get();
This call will cause the driver to navigate to the page if that’s necessary.
Nested Components
LoadableComponents start to become more useful when they are used in
conjunction with other LoadableComponents. Using our example, we could
view the “edit issue” page as a component within a project’s website
(after all, we access it via a tab on that site). You also need to be
logged in to file an issue. We could model this as a tree of nested components:
+ ProjectPage
+---+ SecuredPage
+---+ EditIssue
What would this look like in code? For a start, each logical component
would have its own class. The “load” method in each of them would “get”
the parent. The end result, in addition to the EditIssue class above is:
packagecom.example.webdriver;importorg.openqa.selenium.By;importorg.openqa.selenium.NoSuchElementException;importorg.openqa.selenium.WebDriver;importorg.openqa.selenium.WebElement;import staticorg.junit.Assert.fail;publicclassSecuredPageextendsLoadableComponent<SecuredPage>{privatefinalWebDriverdriver;privatefinalLoadableComponent<?>parent;privatefinalStringusername;privatefinalStringpassword;publicSecuredPage(WebDriverdriver,LoadableComponent<?>parent,Stringusername,Stringpassword){this.driver=driver;this.parent=parent;this.username=username;this.password=password;}@Overrideprotectedvoidload(){parent.get();StringoriginalUrl=driver.getCurrentUrl();// Sign indriver.get("https://www.google.com/accounts/ServiceLogin?service=code");driver.findElement(By.name("Email")).sendKeys(username);WebElementpasswordField=driver.findElement(By.name("Passwd"));passwordField.sendKeys(password);passwordField.submit();// Now return to the original URLdriver.get(originalUrl);}@OverrideprotectedvoidisLoaded()throwsError{// If you're signed in, you have the option of picking a different login.// Let's check for the presence of that.try{WebElementdiv=driver.findElement(By.id("multilogin-dropdown"));}catch(NoSuchElementExceptione){fail("Cannot locate user name link");}}}
This shows that the components are all “nested” within each other.
A call to get() in EditIssue will cause all its dependencies to load too. The example usage:
If you’re using a library such as Guiceberry in your tests,
the preamble of setting up the PageObjects can be omitted leading to nice, clear, readable tests.
Although PageObjects are a useful way of reducing duplication in your tests,
it’s not always a pattern that teams feel comfortable following.
An alternative approach is to follow a more “command-like” style of testing.
A “bot” is an action-oriented abstraction over the raw Selenium APIs.
This means that if you find that commands aren’t doing the Right Thing
for your app, it’s easy to change them. As an example:
publicclassActionBot{privatefinalWebDriverdriver;publicActionBot(WebDriverdriver){this.driver=driver;}publicvoidclick(Bylocator){driver.findElement(locator).click();}publicvoidsubmit(Bylocator){driver.findElement(locator).submit();}/**
* Type something into an input field. WebDriver doesn't normally clear these
* before typing, so this method does that first. It also sends a return key
* to move the focus out of the element.
*/publicvoidtype(Bylocator,Stringtext){WebElementelement=driver.findElement(locator);element.clear();element.sendKeys(text+"\n");}}
Once these abstractions have been built and duplication in your tests
identified, it’s possible to layer PageObjects on top of bots.
Note: this page has merged contents from multiple sources, including
the Selenium wiki
Overview
Within your web app’s UI, there are areas where your tests interact with.
A Page Object only models these as objects within the test code.
This reduces the amount of duplicated code and means that if the UI changes,
the fix needs only to be applied in one place.
Page Object is a Design Pattern that has become popular in test automation for
enhancing test maintenance and reducing code duplication. A page object is an
object-oriented class that serves as an interface to a page of your AUT. The
tests then use the methods of this page object class whenever they need to
interact with the UI of that page. The benefit is that if the UI changes for
the page, the tests themselves don’t need to change, only the code within the
page object needs to change. Subsequently, all changes to support that new UI
are located in one place.
Advantages
There is a clean separation between the test code and page-specific code, such as
locators (or their use if you’re using a UI Map) and layout.
There is a single repository for the services or operations the page offers
rather than having these services scattered throughout the tests.
In both cases, this allows any modifications required due to UI changes to all
be made in one place. Helpful information on this technique can be found on
numerous blogs as this ‘test design pattern’ is becoming widely used. We
encourage readers who wish to know more to search the internet for blogs
on this subject. Many have written on this design pattern and can provide
helpful tips beyond the scope of this user guide. To get you started,
we’ll illustrate page objects with a simple example.
Examples
First, consider an example, typical of test automation, that does not use a
page object:
/***
* Tests login feature
*/publicclassLogin{publicvoidtestLogin(){// fill login data on sign-in pagedriver.findElement(By.name("user_name")).sendKeys("userName");driver.findElement(By.name("password")).sendKeys("my supersecret password");driver.findElement(By.name("sign-in")).click();// verify h1 tag is "Hello userName" after logindriver.findElement(By.tagName("h1")).isDisplayed();assertThat(driver.findElement(By.tagName("h1")).getText(),is("Hello userName"));}}
There are two problems with this approach.
There is no separation between the test method and the AUT’s locators (IDs in
this example); both are intertwined in a single method. If the AUT’s UI changes
its identifiers, layout, or how a login is input and processed, the test itself
must change.
The ID-locators would be spread in multiple tests, in all tests that had to
use this login page.
Applying the page object techniques, this example could be rewritten like this
in the following example of a page object for a Sign-in page.
importorg.openqa.selenium.By;importorg.openqa.selenium.WebDriver;/**
* Page Object encapsulates the Sign-in page.
*/publicclassSignInPage{protectedWebDriverdriver;// <input name="user_name" type="text" value="">privateByusernameBy=By.name("user_name");// <input name="password" type="password" value="">privateBypasswordBy=By.name("password");// <input name="sign_in" type="submit" value="SignIn">privateBysigninBy=By.name("sign_in");publicSignInPage(WebDriverdriver){this.driver=driver;if(!driver.getTitle().equals("Sign In Page")){thrownewIllegalStateException("This is not Sign In Page,"+" current page is: "+driver.getCurrentUrl());}}/**
* Login as valid user
*
* @param userName
* @param password
* @return HomePage object
*/publicHomePageloginValidUser(StringuserName,Stringpassword){driver.findElement(usernameBy).sendKeys(userName);driver.findElement(passwordBy).sendKeys(password);driver.findElement(signinBy).click();returnnewHomePage(driver);}}
and page object for a Home page could look like this.
importorg.openqa.selenium.By;importorg.openqa.selenium.WebDriver;/**
* Page Object encapsulates the Home Page
*/publicclassHomePage{protectedWebDriverdriver;// <h1>Hello userName</h1>privateBymessageBy=By.tagName("h1");publicHomePage(WebDriverdriver){this.driver=driver;if(!driver.getTitle().equals("Home Page of logged in user")){thrownewIllegalStateException("This is not Home Page of logged in user,"+" current page is: "+driver.getCurrentUrl());}}/**
* Get message (h1 tag)
*
* @return String message text
*/publicStringgetMessageText(){returndriver.findElement(messageBy).getText();}publicHomePagemanageProfile(){// Page encapsulation to manage profile functionalityreturnnewHomePage(driver);}/* More methods offering the services represented by Home Page
of Logged User. These methods in turn might return more Page Objects
for example click on Compose mail button could return ComposeMail class object */}
So now, the login test would use these two page objects as follows.
There is a lot of flexibility in how the page objects may be designed, but
there are a few basic rules for getting the desired maintainability of your
test code.
Assertions in Page Objects
Page objects themselves should never make verifications or assertions. This is
part of your test and should always be within the test’s code, never in a page
object. The page object will contain the representation of the page, and the
services the page provides via methods but no code related to what is being
tested should be within the page object.
There is one, single, verification which can, and should, be within the page
object and that is to verify that the page, and possibly critical elements on
the page, were loaded correctly. This verification should be done while
instantiating the page object. In the examples above, both the SignInPage and
HomePage constructors check that the expected page is available and ready for
requests from the test.
Page Component Objects
A page object does not necessarily need to represent all the parts of a
page itself. This was noted by Martin Fowler in the early days, while first coining the term “panel objects”.
The same principles used for page objects can be used to
create “Page Component Objects”, as it was later called, that represent discrete chunks of the
page and can be included in page objects. These component objects can
provide references to the elements inside those discrete chunks, and
methods to leverage the functionality or behavior provided by them.
For example, a Products page has multiple products.
<!-- Inventory Item --><divclass="inventory_item"><divclass="inventory_item_name">Backpack</div><divclass="pricebar"><divclass="inventory_item_price">$29.99</div><buttonid="add-to-cart-backpack">Add to cart</button></div></div>
The Products page HAS-A list of products. This object relationship is called Composition. In simpler terms, something is composed of another thing.
publicabstractclassBasePage{protectedWebDriverdriver;publicBasePage(WebDriverdriver){this.driver=driver;}}// Page ObjectpublicclassProductsPageextendsBasePage{publicProductsPage(WebDriverdriver){super(driver);// No assertions, throws an exception if the element is not loadednewWebDriverWait(driver,Duration.ofSeconds(3)).until(d->d.findElement(By.className("header_container")));}// Returning a list of products is a service of the pagepublicList<Product>getProducts(){returndriver.findElements(By.className("inventory_item")).stream().map(e->newProduct(e))// Map WebElement to a product component.toList();}// Return a specific product using a boolean-valued function (predicate)// This is the behavioral Strategy Pattern from GoFpublicProductgetProduct(Predicate<Product>condition){returngetProducts().stream().filter(condition)// Filter by product name or price.findFirst().orElseThrow();}}
The Product component object is used inside the Products page object.
publicabstractclassBaseComponent{protectedWebElementroot;publicBaseComponent(WebElementroot){this.root=root;}}// Page Component ObjectpublicclassProductextendsBaseComponent{// The root element contains the entire componentpublicProduct(WebElementroot){super(root);// inventory_item}publicStringgetName(){// Locating an element begins at the root of the componentreturnroot.findElement(By.className("inventory_item_name")).getText();}publicBigDecimalgetPrice(){returnnewBigDecimal(root.findElement(By.className("inventory_item_price")).getText().replace("$","")).setScale(2,RoundingMode.UNNECESSARY);// Sanitation and formatting}publicvoidaddToCart(){root.findElement(By.id("add-to-cart-backpack")).click();}}
So now, the products test would use the page object and the page component object as follows.
publicclassProductsTest{@TestpublicvoidtestProductInventory(){varproductsPage=newProductsPage(driver);// page objectvarproducts=productsPage.getProducts();assertEquals(6,products.size());// expected, actual}@TestpublicvoidtestProductPrices(){varproductsPage=newProductsPage(driver);// Pass a lambda expression (predicate) to filter the list of products// The predicate or "strategy" is the behavior passed as parametervarbackpack=productsPage.getProduct(p->p.getName().equals("Backpack"));// page component objectvarbikeLight=productsPage.getProduct(p->p.getName().equals("Bike Light"));assertEquals(newBigDecimal("29.99"),backpack.getPrice());assertEquals(newBigDecimal("9.99"),bikeLight.getPrice());}}
The page and component are represented by their own objects. Both objects only have methods for the services they offer, which matches the real-world application in object-oriented programming.
You can even
nest component objects inside other component objects for more complex
pages. If a page in the AUT has multiple components, or common
components used throughout the site (e.g. a navigation bar), then it
may improve maintainability and reduce code duplication.
Other Design Patterns Used in Testing
There are other design patterns that also may be used in testing. Discussing all of these is
beyond the scope of this user guide. Here, we merely want to introduce the
concepts to make the reader aware of some of the things that can be done. As
was mentioned earlier, many have blogged on this topic and we encourage the
reader to search for blogs on these topics.
Implementation Notes
PageObjects can be thought of as facing in two directions simultaneously. Facing toward the developer of a test, they represent the services offered by a particular page. Facing away from the developer, they should be the only thing that has a deep knowledge of the structure of the HTML of a page (or part of a page) It’s simplest to think of the methods on a Page Object as offering the “services” that a page offers rather than exposing the details and mechanics of the page. As an example, think of the inbox of any web-based email system. Amongst the services it offers are the ability to compose a new email, choose to read a single email, and list the subject lines of the emails in the inbox. How these are implemented shouldn’t matter to the test.
Because we’re encouraging the developer of a test to try and think about the services they’re interacting with rather than the implementation, PageObjects should seldom expose the underlying WebDriver instance. To facilitate this, methods on the PageObject should return other PageObjects. This means we can effectively model the user’s journey through our application. It also means that should the way that pages relate to one another change (like when the login page asks the user to change their password the first time they log into a service when it previously didn’t do that), simply changing the appropriate method’s signature will cause the tests to fail to compile. Put another way; we can tell which tests would fail without needing to run them when we change the relationship between pages and reflect this in the PageObjects.
One consequence of this approach is that it may be necessary to model (for example) both a successful and unsuccessful login; or a click could have a different result depending on the app’s state. When this happens, it is common to have multiple methods on the PageObject:
publicclassLoginPage{publicHomePageloginAs(Stringusername,Stringpassword){// ... clever magic happens here}publicLoginPageloginAsExpectingError(Stringusername,Stringpassword){// ... failed login here, maybe because one or both of the username and password are wrong}publicStringgetErrorMessage(){// So we can verify that the correct error is shown}}
The code presented above shows an important point: the tests, not the PageObjects, should be responsible for making assertions about the state of a page. For example:
publicvoidtestMessagesAreReadOrUnread(){Inboxinbox=newInbox(driver);inbox.assertMessageWithSubjectIsUnread("I like cheese");inbox.assertMessageWithSubjectIsNotUnread("I'm not fond of tofu");}
could be re-written as:
publicvoidtestMessagesAreReadOrUnread(){Inboxinbox=newInbox(driver);assertTrue(inbox.isMessageWithSubjectIsUnread("I like cheese"));assertFalse(inbox.isMessageWithSubjectIsUnread("I'm not fond of tofu"));}
Of course, as with every guideline, there are exceptions, and one that is commonly seen with PageObjects is to check that the WebDriver is on the correct page when we instantiate the PageObject. This is done in the example below.
Finally, a PageObject need not represent an entire page. It may represent a section that appears frequently within a site or page, such as site navigation. The essential principle is that there is only one place in your test suite with knowledge of the structure of the HTML of a particular (part of a) page.
Summary
The public methods represent the services that the page offers
Try not to expose the internals of the page
Generally don’t make assertions
Methods return other PageObjects
Need not represent an entire page
Different results for the same action are modelled as different methods
Example
publicclassLoginPage{privatefinalWebDriverdriver;publicLoginPage(WebDriverdriver){this.driver=driver;// Check that we're on the right page.if(!"Login".equals(driver.getTitle())){// Alternatively, we could navigate to the login page, perhaps logging out firstthrownewIllegalStateException("This is not the login page");}}// The login page contains several HTML elements that will be represented as WebElements.// The locators for these elements should only be defined once.ByusernameLocator=By.id("username");BypasswordLocator=By.id("passwd");ByloginButtonLocator=By.id("login");// The login page allows the user to type their username into the username fieldpublicLoginPagetypeUsername(Stringusername){// This is the only place that "knows" how to enter a usernamedriver.findElement(usernameLocator).sendKeys(username);// Return the current page object as this action doesn't navigate to a page represented by another PageObjectreturnthis;}// The login page allows the user to type their password into the password fieldpublicLoginPagetypePassword(Stringpassword){// This is the only place that "knows" how to enter a passworddriver.findElement(passwordLocator).sendKeys(password);// Return the current page object as this action doesn't navigate to a page represented by another PageObjectreturnthis;}// The login page allows the user to submit the login formpublicHomePagesubmitLogin(){// This is the only place that submits the login form and expects the destination to be the home page.// A seperate method should be created for the instance of clicking login whilst expecting a login failure. driver.findElement(loginButtonLocator).submit();// Return a new page object representing the destination. Should the login page ever// go somewhere else (for example, a legal disclaimer) then changing the method signature// for this method will mean that all tests that rely on this behaviour won't compile.returnnewHomePage(driver);}// The login page allows the user to submit the login form knowing that an invalid username and / or password were enteredpublicLoginPagesubmitLoginExpectingFailure(){// This is the only place that submits the login form and expects the destination to be the login page due to login failure.driver.findElement(loginButtonLocator).submit();// Return a new page object representing the destination. Should the user ever be navigated to the home page after submiting a login with credentials // expected to fail login, the script will fail when it attempts to instantiate the LoginPage PageObject.returnnewLoginPage(driver);}// Conceptually, the login page offers the user the service of being able to "log into"// the application using a user name and password. publicHomePageloginAs(Stringusername,Stringpassword){// The PageObject methods that enter username, password & submit login have already defined and should not be repeated here.typeUsername(username);typePassword(password);returnsubmitLogin();}}
/**
* Takes a username and password, fills out the fields, and clicks "login".
* @return An instance of the AccountPage
*/publicAccountPageloginAsUser(Stringusername,Stringpassword){WebElementloginField=driver.findElement(By.id("loginField"));loginField.clear();loginField.sendKeys(username);// Fill out the password field. The locator we're using is "By.id", and we should// have it defined elsewhere in the class.WebElementpasswordField=driver.findElement(By.id("password"));passwordField.clear();passwordField.sendKeys(password);// Click the login button, which happens to have the id "submit".driver.findElement(By.id("submit")).click();// Create and return a new instance of the AccountPage (via the built-in Selenium// PageFactory).returnPageFactory.newInstance(AccountPage.class);}
publicvoidloginTest(){loginAsUser("cbrown","cl0wn3");// Now that we're logged in, do some other stuff--since we used a DSL to support// our testers, it's as easy as choosing from available methods.do.something();do.somethingElse();Assert.assertTrue("Something should have been done!",something.wasDone());// Note that we still haven't referred to a button or web control anywhere in this// script...}
If you choose pytest as your test runner, this can be
easily done by yielding your driver in a global fixture. This way each test gets its own
driver instance, and you can ensure that drivers always quit after a test is finished
(pass or fail).
publicabstractclassBasePage{protectedWebDriverdriver;publicBasePage(WebDriverdriver){this.driver=driver;}}publicclassGoogleSearchPageextendsBasePage{publicGoogleSearchPage(WebDriverdriver){super(driver);// Generally do not assert within pages or components.// Effectively throws an exception if the lambda condition is not met.newWebDriverWait(driver,Duration.ofSeconds(3)).until(d->d.findElement(By.id("logo")));}publicGoogleSearchPagesetSearchString(Stringsstr){driver.findElement(By.id("gbqfq")).sendKeys(sstr);returnthis;}publicvoidclickSearchButton(){driver.findElement(By.id("gbqfb")).click();}}
验证码 (CAPTCHA), 是 全自动区分计算机和人类的图灵测试(Completely Automated Public Turing test to tell Computers and Humans Apart) 的简称,
是被明确地设计用于阻止自动化的, 所以不要尝试! 规避验证码的检查, 主要有两个策略:
usingSystem;usingSystem.Text;usingSystem.Text.RegularExpressions;usingSystem.Threading;usingNUnit.Framework;usingSelenium;namespaceSeleniumTests{ [TestFixture]publicclassNewTest{privateISeleniumselenium;privateStringBuilderverificationErrors; [SetUp]publicvoidSetupTest(){selenium=newDefaultSelenium("localhost",4444,"*firefox","http://www.google.com/");selenium.Start();verificationErrors=newStringBuilder();} [TearDown]publicvoidTeardownTest(){try{selenium.Stop();}catch(Exception){// Ignore errors if unable to close the browser}Assert.AreEqual("",verificationErrors.ToString());} [Test]publicvoidTheNewTest(){selenium.Open("/");selenium.Type("q","selenium rc");selenium.Click("btnG");selenium.WaitForPageToLoad("30000");Assert.AreEqual("selenium rc - Google Search",selenium.GetTitle());}}}
Java
/** Add JUnit framework to your classpath if not already there
* for this example to work
*/packagecom.example.tests;importcom.thoughtworks.selenium.*;importjava.util.regex.Pattern;publicclassNewTestextendsSeleneseTestCase{publicvoidsetUp()throwsException{setUp("http://www.google.com/","*firefox");}publicvoidtestNew()throwsException{selenium.open("/");selenium.type("q","selenium rc");selenium.click("btnG");selenium.waitForPageToLoad("30000");assertTrue(selenium.isTextPresent("Results * for selenium rc"));}}
Php
<?phprequire_once'PHPUnit/Extensions/SeleniumTestCase.php';classExampleextendsPHPUnit_Extensions_SeleniumTestCase{functionsetUp(){$this->setBrowser("*firefox");$this->setBrowserUrl("http://www.google.com/");}functiontestMyTestCase(){$this->open("/");$this->type("q","selenium rc");$this->click("btnG");$this->waitForPageToLoad("30000");$this->assertTrue($this->isTextPresent("Results * for selenium rc"));}}?>
Python
fromseleniumimportseleniumimportunittest,time,reclassNewTest(unittest.TestCase):defsetUp(self):self.verificationErrors=[]self.selenium=selenium("localhost",4444,"*firefox","http://www.google.com/")self.selenium.start()deftest_new(self):sel=self.seleniumsel.open("/")sel.type("q","selenium rc")sel.click("btnG")sel.wait_for_page_to_load("30000")self.failUnless(sel.is_text_present("Results * for selenium rc"))deftearDown(self):self.selenium.stop()self.assertEqual([],self.verificationErrors)
Ruby
require"selenium/client"require"test/unit"classNewTest<Test::Unit::TestCasedefsetup@verification_errors=[]if$selenium@selenium=$seleniumelse@selenium=Selenium::Client::Driver.new("localhost",4444,"*firefox","http://www.google.com/",60);@selenium.startend@selenium.set_context("test_new")enddefteardown@selenium.stopunless$seleniumassert_equal[],@verification_errorsenddeftest_new@selenium.open"/"@selenium.type"q","selenium rc"@selenium.click"btnG"@selenium.wait_for_page_to_load"30000"assert@selenium.is_text_present("Results * for selenium rc")endend
packagecom.example.tests;// We specify the package of our testsimportcom.thoughtworks.selenium.*;// This is the driver's import. You'll use this for instantiating a// browser and making it do what you need.importjava.util.regex.Pattern;// Selenium-IDE add the Pattern module because it's sometimes used for // regex validations. You can remove the module if it's not used in your // script.publicclassNewTestextendsSeleneseTestCase{// We create our Selenium test casepublicvoidsetUp()throwsException{setUp("http://www.google.com/","*firefox");// We instantiate and start the browser}publicvoidtestNew()throwsException{selenium.open("/");selenium.type("q","selenium rc");selenium.click("btnG");selenium.waitForPageToLoad("30000");assertTrue(selenium.isTextPresent("Results * for selenium rc"));// These are the real test steps}}
C#
.NET客户端驱动程序可与Microsoft.NET一起使用.
它可以与任何.NET测试框架(
如NUnit或Visual Studio 2005 Team System)一起使用.
usingSystem;usingSystem.Text;usingSystem.Text.RegularExpressions;usingSystem.Threading;usingNUnit.Framework;usingSelenium;namespaceSeleniumTests{ [TestFixture]publicclassNewTest{privateISeleniumselenium;privateStringBuilderverificationErrors; [SetUp]publicvoidSetupTest(){selenium=newDefaultSelenium("localhost",4444,"*iehta","http://www.google.com/");selenium.Start();verificationErrors=newStringBuilder();} [TearDown]publicvoidTeardownTest(){try{selenium.Stop();}catch(Exception){// Ignore errors if unable to close the browser}Assert.AreEqual("",verificationErrors.ToString());} [Test]publicvoidTheNewTest(){// Open Google search engine. selenium.Open("http://www.google.com/");// Assert Title of page.Assert.AreEqual("Google",selenium.GetTitle());// Provide search term as "Selenium OpenQA"selenium.Type("q","Selenium OpenQA");// Read the keyed search term and assert it.Assert.AreEqual("Selenium OpenQA",selenium.GetValue("q"));// Click on Search button.selenium.Click("btnG");// Wait for page to load.selenium.WaitForPageToLoad("5000");// Assert that "www.openqa.org" is available in search results.Assert.IsTrue(selenium.IsTextPresent("www.openqa.org"));// Assert that page title is - "Selenium OpenQA - Google Search"Assert.AreEqual("Selenium OpenQA - Google Search",selenium.GetTitle());}}}
fromseleniumimportselenium# This is the driver's import. You'll use this class for instantiating a# browser and making it do what you need.importunittest,time,re# This are the basic imports added by Selenium-IDE by default.# You can remove the modules if they are not used in your script.classNewTest(unittest.TestCase):# We create our unittest test casedefsetUp(self):self.verificationErrors=[]# This is an empty array where we will store any verification errors# we find in our testsself.selenium=selenium("localhost",4444,"*firefox","http://www.google.com/")self.selenium.start()# We instantiate and start the browserdeftest_new(self):# This is the test code. Here you should put the actions you need# the browser to do during your test.sel=self.selenium# We assign the browser to the variable "sel" (just to save us from # typing "self.selenium" each time we want to call the browser).sel.open("/")sel.type("q","selenium rc")sel.click("btnG")sel.wait_for_page_to_load("30000")self.failUnless(sel.is_text_present("Results * for selenium rc"))# These are the real test stepsdeftearDown(self):self.selenium.stop()# we close the browser (I'd recommend you to comment this line while# you are creating and debugging your tests)self.assertEqual([],self.verificationErrors)# And make the test fail if we found that any verification errors# were found
# load the Selenium-Client gemrequire"selenium/client"# Load Test::Unit, Ruby's default test framework.# If you prefer RSpec, see the examples in the Selenium-Client# documentation.require"test/unit"classUntitled<Test::Unit::TestCase# The setup method is called before each test.defsetup# This array is used to capture errors and display them at the# end of the test run.@verification_errors=[]# Create a new instance of the Selenium-Client driver.@selenium=Selenium::Client::Driver.new\:host=>"localhost",:port=>4444,:browser=>"*chrome",:url=>"http://www.google.com/",:timeout_in_second=>60# Start the browser session@selenium.start# Print a message in the browser-side log and status bar# (optional).@selenium.set_context("test_untitled")end# The teardown method is called after each test.defteardown# Stop the browser session.@selenium.stop# Print the array of error messages, if any.assert_equal[],@verification_errorsend# This is the main body of your test.deftest_untitled# Open the root of the site we specified when we created the# new driver instance, above.@selenium.open"/"# Type 'selenium rc' into the field named 'q'@selenium.type"q","selenium rc"# Click the button named "btnG"@selenium.click"btnG"# Wait for the search results page to load.# Note that we don't need to set a timeout here, because that# was specified when we created the new driver instance, above.@selenium.wait_for_page_to_loadbegin# Test whether the search results contain the expected text.# Notice that the star (*) is a wildcard that matches any# number of characters.assert@selenium.is_text_present("Results * for selenium rc")rescueTest::Unit::AssertionFailedError# If the assertion fails, push it onto the array of errors.@verification_errors<<$!endendend
// Collection of String values.String[]arr={"ide","rc","grid"};// Execute loop for each String in array 'arr'.foreach(Stringsinarr){sel.open("/");sel.type("q","selenium "+s);sel.click("btnG");sel.waitForPageToLoad("30000");assertTrue("Expected text: "+s+" is missing on page.",sel.isTextPresent("Results * for selenium "+s));}
// If element is available on page then perform type operation.if(selenium.isElementPresent("q")){selenium.type("q","Selenium rc");}else{System.out.printf("Element: "+q+" is not available on page.")}
publicstaticString[]getAllCheckboxIds(){Stringscript="var inputId = new Array();";// Create array in java script.script+="var cnt = 0;";// Counter for check box ids. script+="var inputFields = new Array();";// Create array in java script.script+="inputFields = window.document.getElementsByTagName('input');";// Collect input elements.script+="for(var i=0; i<inputFields.length; i++) {";// Loop through the collected elements.script+="if(inputFields[i].id !=null "+"&& inputFields[i].id !='undefined' "+"&& inputFields[i].getAttribute('type') == 'checkbox') {";// If input field is of type check box and input id is not null.script+="inputId[cnt]=inputFields[i].id ;"+// Save check box id to inputId array."cnt++;"+// increment the counter."}"+// end of if."}";// end of for.script+="inputId.toString();";// Convert array in to string. String[]checkboxIds=selenium.getEval(script).split(",");// Split the string.returncheckboxIds;}
"Unable to connect to remote server (Inner Exception Message:
No connection could be made because the target machine actively
refused it )"(using .NET and XP Service Pack 2)
Most of the documentation found in this section is still in English.
Please note we are not accepting pull requests to translate this content
as translating documentation of legacy components does not add value to
the community nor the project.
{"_comment":"Configuration for Hub - hubConfig.json","host":ip,"maxSession":5,"port":4444,"cleanupCycle":5000,"timeout":300000,"newSessionWaitTimeout":-1,"servlets":[],"prioritizer":null,"capabilityMatcher":"org.openqa.grid.internal.utils.DefaultCapabilityMatcher","throwOnCapabilityNotPresent":true,"nodePolling":180000,"platform":"WINDOWS"}
Most of the documentation found in this section is still in English.
Please note we are not accepting pull requests to translate this content
as translating documentation of legacy components does not add value to
the community nor the project.
Introduction
The Selenium-IDE (Integrated Development Environment) is the tool you use to
develop your Selenium test cases. It’s an easy-to-use Firefox plug-in and is
generally the most efficient way to develop test cases. It also contains a
context menu that allows you to first select a UI element from the browser’s
currently displayed page and then select from a list of Selenium commands with
parameters pre-defined according to the context of the selected UI element.
This is not only a time-saver, but also an excellent way of learning Selenium
script syntax.
This chapter is all about the Selenium IDE and how to use it effectively.
Installing the IDE
Using Firefox, first, download the IDE from the SeleniumHQ downloads page
Firefox will protect you from installing addons from unfamiliar locations, so
you will need to click ‘Allow’ to proceed with the installation, as shown in
the following screenshot.
When downloading from Firefox, you’ll be presented with the following window.
Select Install Now. The Firefox Add-ons window pops up, first showing a progress bar,
and when the download is complete, displays the following.
Restart Firefox. After Firefox reboots you will find the Selenium-IDE listed under
the Firefox Tools menu.
Opening the IDE
To run the Selenium-IDE, simply select it from the Firefox Tools menu. It opens
as follows with an empty script-editing window and a menu for loading, or
creating new test cases.
IDE Features
Menu Bar
The File menu has options for Test Case and Test Suite (suite of Test Cases).
Using these you can add a new Test Case, open a Test Case, save a Test Case,
export Test Case in a language of your choice. You can also open the recent
Test Case. All these options are also available for Test Suite.
The Edit menu allows copy, paste, delete, undo, and select all operations for
editing the commands in your test case. The Options menu allows the changing of
settings. You can set the timeout value for certain commands, add user-defined
user extensions to the base set of Selenium commands, and specify the format
(language) used when saving your test cases. The Help menu is the standard
Firefox Help menu; only one item on this menu–UI-Element Documentation–pertains
to Selenium-IDE.
Toolbar
The toolbar contains buttons for controlling the execution of your test cases,
including a step feature for debugging your test cases. The right-most button,
the one with the red-dot, is the record button.
Speed Control: controls how fast your test case runs.
Run All: Runs the entire test suite when a test suite with multiple test cases is loaded.
Run: Runs the currently selected test. When only a single test is loaded
this button and the Run All button have the same effect.
Pause/Resume: Allows stopping and re-starting of a running test case.
Step: Allows you to “step” through a test case by running it one command at a time.
Use for debugging test cases.
TestRunner Mode: Allows you to run the test case in a browser loaded with the
Selenium-Core TestRunner. The TestRunner is not commonly used now and is likely
to be deprecated. This button is for evaluating test cases for backwards
compatibility with the TestRunner. Most users will probably not need this
button.
Apply Rollup Rules: This advanced feature allows repetitive sequences of
Selenium commands to be grouped into a single action. Detailed documentation on
rollup rules can be found in the UI-Element Documentation on the Help menu.
Test Case Pane
Your script is displayed in the test case pane. It has two tabs, one for
displaying the command and their parameters in a readable “table” format.
The other tab - Source displays the test case in the native format in which the
file will be stored. By default, this is HTML although it can be changed to a
programming language such as Java or C#, or a scripting language like Python.
See the Options menu for details. The Source view also allows one to edit the
test case in its raw form, including copy, cut and paste operations.
The Command, Target, and Value entry fields display the currently selected
command along with its parameters. These are entry fields where you can modify
the currently selected command. The first parameter specified for a command in
the Reference tab of the bottom pane always goes in the Target field. If a
second parameter is specified by the Reference tab, it always goes in the Value
field.
If you start typing in the Command field, a drop-down list will be populated
based on the first characters you type; you can then select your desired
command from the drop-down.
Log/Reference/UI-Element/Rollup Pane
The bottom pane is used for four different functions–Log, Reference,
UI-Element, and Rollup–depending on which tab is selected.
Log
When you run your test case, error messages and information messages showing
the progress are displayed in this pane automatically, even if you do not first
select the Log tab. These messages are often useful for test case debugging.
Notice the Clear button for clearing the Log. Also notice the Info button is a
drop-down allowing selection of different levels of information to log.
Reference
The Reference tab is the default selection whenever you are entering or
modifying Selenese commands and parameters in Table mode. In Table mode, the
Reference pane will display documentation on the current command. When entering
or modifying commands, whether from Table or Source mode, it is critically
important to ensure that the parameters specified in the Target and Value
fields match those specified in the parameter list in the Reference pane. The
number of parameters provided must match the number specified, the order of
parameters provided must match the order specified, and the type of parameters
provided must match the type specified. If there is a mismatch in any of these
three areas, the command will not run correctly.
While the Reference tab is invaluable as a quick reference, it is still often
necessary to consult the Selenium Reference document.
UI-Element and Rollup
Detailed information on these two panes (which cover advanced features) can be
found in the UI-Element Documentation on the Help menu of Selenium-IDE.
Building Test Cases
There are three primary methods for developing test cases. Frequently, a test
developer will require all three techniques.
Recording
Many first-time users begin by recording a test case from their interactions
with a website. When Selenium-IDE is first opened, the record button is ON by
default. If you do not want Selenium-IDE to begin recording automatically you
can turn this off by going under Options > Options… and deselecting “Start
recording immediately on open.”
During recording, Selenium-IDE will automatically insert commands into your
test case based on your actions. Typically, this will include:
clicking a link - click or clickAndWait commands
entering values - type command
selecting options from a drop-down listbox - select command
clicking checkboxes or radio buttons - click command
Here are some “gotchas” to be aware of:
The type command may require clicking on some other area of the web page for it
to record.
Following a link usually records a click command. You will often need to change
this to clickAndWait to ensure your test case pauses until the new page is
completely loaded. Otherwise, your test case will continue running commands
before the page has loaded all its UI elements. This will cause unexpected test
case failures.
Adding Verifications and Asserts With the Context Menu
Your test cases will also need to check the properties of a web-page. This
requires assert and verify commands. We won’t describe the specifics of these
commands here; that is in the chapter on Selenium Commands – “Selenese”. Here
we’ll simply describe how to add them to your test case.
With Selenium-IDE recording, go to the browser displaying your test application
and right click anywhere on the page. You will see a context menu showing
verify and/or assert commands.
The first time you use Selenium, there may only be one Selenium command listed.
As you use the IDE however, you will find additional commands will quickly be
added to this menu. Selenium-IDE will attempt to predict what command, along
with the parameters, you will need for a selected UI element on the current
web-page.
Let’s see how this works. Open a web-page of your choosing and select a block
of text on the page. A paragraph or a heading will work fine. Now, right-click
the selected text. The context menu should give you a verifyTextPresent command
and the suggested parameter should be the text itself.
Also, notice the Show All Available Commands menu option. This shows many, many
more commands, again, along with suggested parameters, for testing your
currently selected UI element.
Try a few more UI elements. Try right-clicking an image, or a user control like
a button or a checkbox. You may need to use Show All Available Commands to see
options other than verifyTextPresent. Once you select these other options, the
more commonly used ones will show up on the primary context menu. For example,
selecting verifyElementPresent for an image should later cause that command to
be available on the primary context menu the next time you select an image and
right-click.
Again, these commands will be explained in detail in the chapter on Selenium
commands. For now though, feel free to use the IDE to record and select
commands into a test case and then run it. You can learn a lot about the
Selenium commands simply by experimenting with the IDE.
Editing
Insert Command
Table View
Select the point in your test case where you want to insert the command. To do
this, in the Test Case Pane, left-click on the line where you want to insert a
new command. Right-click and select Insert Command; the IDE will add a blank
line just ahead of the line you selected. Now use the command editing text
fields to enter your new command and its parameters.
Source View
Select the point in your test case where you want to insert the command. To do
this, in the Test Case Pane, left-click between the commands where you want to
insert a new command, and enter the HTML tags needed to create a 3-column row
containing the Command, first parameter (if one is required by the Command),
and second parameter (again, if one is required to locate an element) and third
parameter(again, if one is required to have a value). Example:
Comments may be added to make your test case more readable. These comments are
ignored when the test case is run.
Comments may also be used to add vertical white space (one or more blank lines)
in your tests; just create empty comments. An empty command will cause an error
during execution; an empty comment won’t.
Table View
Select the line in your test case where you want to insert the comment.
Right-click and select Insert Comment. Now use the Command field to enter the
comment. Your comment will appear in purple text.
Source View
Select the point in your test case where you want to insert the comment. Add an
HTML-style comment, i.e., <!-- your comment here -->.
Edit a Command or Comment
Table View
Simply select the line to be changed and edit it using the Command, Target,
and Value fields.
Source View
Since Source view provides the equivalent of a WYSIWYG (What You See is What
You Get) editor, simply modify which line you wish–command, parameter, or comment.
Opening and Saving a Test Case
Like most programs, there are Save and Open commands under the File menu.
However, Selenium distinguishes between test cases and test suites. To save
your Selenium-IDE tests for later use you can either save the individual test
cases, or save the test suite. If the test cases of your test suite have not
been saved, you’ll be prompted to save them before saving the test suite.
When you open an existing test case or suite, Selenium-IDE displays its
Selenium commands in the Test Case Pane.
Running Test Cases
The IDE allows many options for running your test case. You can run a test case
all at once, stop and start it, run it one line at a time, run a single command
you are currently developing, and you can do a batch run of an entire test
suite. Execution of test cases is very flexible in the IDE.
Run a Test Case
Click the Run button to run the currently displayed test case.
Run a Test Suite
Click the Run All button to run all the test cases in the currently loaded test
suite.
Stop and Start
The Pause button can be used to stop the test case while it is running. The
icon of this button then changes to indicate the Resume button. To continue
click Resume.
Stop in the Middle
You can set a breakpoint in the test case to cause it to stop on a particular
command. This is useful for debugging your test case. To set a breakpoint,
select a command, right-click, and from the context menu select Toggle
Breakpoint.
Start from the Middle
You can tell the IDE to begin running from a specific command in the middle of
the test case. This also is used for debugging. To set a startpoint, select a
command, right-click, and from the context menu select Set/Clear Start Point.
Run Any Single Command
Double-click any single command to run it by itself. This is useful when
writing a single command. It lets you immediately test a command you are
constructing, when you are not sure if it is correct. You can double-click it
to see if it runs correctly. This is also available from the context menu.
Using Base URL to Run Test Cases in Different Domains
The Base URL field at the top of the Selenium-IDE window is very useful for
allowing test cases to be run across different domains. Suppose that a site
named http://news.portal.com had an in-house beta site named
http://beta.news.portal.com. Any test cases for these sites that begin with an
open statement should specify a relative URL as the argument to open rather
than an absolute URL (one starting with a protocol such as http: or https:).
Selenium-IDE will then create an absolute URL by appending the open command’s
argument onto the end of the value of Base URL. For example, the test case
below would be run against http://news.portal.com/about.html:
Selenium commands, often called selenese, are the set of commands that run your
tests. A sequence of these commands is a test script. Here we explain those
commands in detail, and we present the many choices you have in testing your
web application when using Selenium.
Selenium provides a rich set of commands for fully testing your web-app in
virtually any way you can imagine. The command set is often called selenese.
These commands essentially create a testing language.
In selenese, one can test the existence of UI elements based on their HTML
tags, test for specific content, test for broken links, input fields, selection
list options, submitting forms, and table data among other things. In addition
Selenium commands support testing of window size, mouse position, alerts, Ajax
functionality, pop up windows, event handling, and many other web-application
features. The Command Reference lists all the available commands.
A command tells Selenium what to do. Selenium commands come in three “flavors”:
Actions, Accessors, and Assertions.
Actions are commands that generally manipulate the state of the application.
They do things like “click this link” and “select that option”. If an Action
fails, or has an error, the execution of the current test is stopped.
Many Actions can be called with the “AndWait” suffix, e.g. “clickAndWait”. This
suffix tells Selenium that the action will cause the browser to make a call to
the server, and that Selenium should wait for a new page to load.
Accessors examine the state of the application and store the results in
variables, e.g. “storeTitle”. They are also used to automatically generate
Assertions.
Assertions are like Accessors, but they verify that the state of the
application conforms to what is expected. Examples include “make sure the page
title is X” and “verify that this checkbox is checked”.
All Selenium Assertions can be used in 3 modes: “assert”, “verify”, and ”
waitFor”. For example, you can “assertText”, “verifyText” and “waitForText”.
When an “assert” fails, the test is aborted. When a “verify” fails, the test
will continue execution, logging the failure. This allows a single “assert” to
ensure that the application is on the correct page, followed by a bunch of
“verify” assertions to test form field values, labels, etc.
“waitFor” commands wait for some condition to become true (which can be useful
for testing Ajax applications). They will succeed immediately if the condition
is already true. However, they will fail and halt the test if the condition
does not become true within the current timeout setting (see the setTimeout
action below).
Script Syntax
Selenium commands are simple, they consist of the command and two parameters.
For example:
verifyText
//div//a[2]
Login
The parameters are not always required; it depends on the command. In some
cases both are required, in others one parameter is required, and in still
others the command may take no parameters at all. Here are a couple more
examples:
goBackAndWait
verifyTextPresent
Welcome to My Home Page
type
id=phone
(555) 666-7066
type
id=address1
${myVariableAddress}
The command reference describes the parameter requirements for each command.
Parameters vary, however they are typically:
a locator for identifying a UI element within a page.
a text pattern for verifying or asserting expected page content
a text pattern or a Selenium variable for entering text in an input field or
for selecting an option from an option list.
Locators, text patterns, Selenium variables, and the commands themselves are
described in considerable detail in the section on Selenium Commands.
Selenium scripts that will be run from Selenium-IDE will be stored in an HTML
text file format. This consists of an HTML table with three columns. The first
column identifies the Selenium command, the second is a target, and the final
column contains a value. The second and third columns may not require values
depending on the chosen Selenium command, but they should be present. Each
table row represents a new Selenium command. Here is an example of a test that
opens a page, asserts the page title and then verifies some content on the page:
Rendered as a table in a browser this would look like the following:
open
/download/
assertTitle
Downloads
verifyText
//h2
Downloads
The Selenese HTML syntax can be used to write and run tests without requiring
knowledge of a programming language. With a basic knowledge of selenese and
Selenium-IDE you can quickly produce and run testcases.
Test Suites
A test suite is a collection of tests. Often one will run all the tests in a
test suite as one continuous batch-job.
When using Selenium-IDE, test suites also can be defined using a simple HTML
file. The syntax again is simple. An HTML table defines a list of tests where
each row defines the filesystem path to each test. An example tells it all.
<html><head><title>Test Suite Function Tests - Priority 1</title></head><body><table><tr><td><b>Suite Of Tests</b></td></tr><tr><td><ahref="./Login.html">Login</a></td></tr><tr><td><ahref="./SearchValues.html">Test Searching for Values</a></td></tr><tr><td><ahref="./SaveValues.html">Test Save</a></td></tr></table></body></html>
A file similar to this would allow running the tests all at once, one after
another, from the Selenium-IDE.
Test suites can also be maintained when using Selenium-RC. This is done via
programming and can be done a number of ways. Commonly Junit is used to
maintain a test suite if one is using Selenium-RC with Java. Additionally, if
C# is the chosen language, Nunit could be employed. If using an interpreted
language like Python with Selenium-RC then some simple programming would be
involved in setting up a test suite. Since the whole reason for using
Selenium-RC is to make use of programming logic for your testing this usually
isn’t a problem.
Commonly Used Selenium Commands
To conclude our introduction of Selenium, we’ll show you a few typical Selenium
commands. These are probably the most commonly used commands for building
tests.
open
opens a page using a URL.
click/clickAndWait
performs a click operation, and optionally waits for a new page to load.
verifyTitle/assertTitle
verifies an expected page title.
verifyTextPresent
verifies expected text is somewhere on the page.
verifyElementPresent
verifies an expected UI element, as defined by its HTML tag, is present on the
page.
verifyText
verifies expected text and its corresponding HTML tag are present on the page.
verifyTable
verifies a table’s expected contents.
waitForPageToLoad
pauses execution until an expected new page loads. Called automatically when
clickAndWait is used.
waitForElementPresent
pauses execution until an expected UI element, as defined by its HTML tag, is
present on the page.
Verifying Page Elements
Verifying UI elements on a web page is probably the most common feature of your
automated tests. Selenese allows multiple ways of checking for UI elements. It
is important that you understand these different methods because these methods
define what you are actually testing.
For example, will you test that…
an element is present somewhere on the page?
specific text is somewhere on the page?
specific text is at a specific location on the page?
For example, if you are testing a text heading, the text and its position at
the top of the page are probably relevant for your test. If, however, you are
testing for the existence of an image on the home page, and the web designers
frequently change the specific image file along with its position on the page,
then you only want to test that an image (as opposed to the specific image
file) exists somewhere on the page.
Assertion or Verification?
Choosing between “assert” and “verify” comes down to convenience and management
of failures. There’s very little point checking that the first paragraph on the
page is the correct one if your test has already failed when checking that the
browser is displaying the expected page. If you’re not on the correct page,
you’ll probably want to abort your test case so that you can investigate the
cause and fix the issue(s) promptly. On the other hand, you may want to check
many attributes of a page without aborting the test case on the first failure
as this will allow you to review all failures on the page and take the
appropriate action. Effectively an “assert” will fail the test and abort the
current test case, whereas a “verify” will fail the test and continue to run
the test case.
The best use of this feature is to logically group your test commands, and
start each group with an “assert” followed by one or more “verify” test
commands. An example follows:
Command
Target
Value
open
/download/
assertTitle
Downloads
verifyText
//h2
Downloads
assertTable
1.2.1
Selenium IDE
verifyTable
1.2.2
June 3, 2008
verifyTable
1.2.3
1.0 beta 2
The above example first opens a page and then “asserts” that the correct page
is loaded by comparing the title with the expected value. Only if this passes
will the following command run and “verify” that the text is present in the
expected location. The test case then “asserts” the first column in the second
row of the first table contains the expected value, and only if this passed
will the remaining cells in that row be “verified”.
verifyTextPresent
The command verifyTextPresent is used to verify specific text exists somewhere
on the page. It takes a single argument–the text pattern to be verified. For
example:
Command
Target
Value
verifyTextPresent
Marketing Analysis
This would cause Selenium to search for, and verify, that the text string
“Marketing Analysis” appears somewhere on the page currently being tested. Use
verifyTextPresent when you are interested in only the text itself being present
on the page. Do not use this when you also need to test where the text occurs
on the page.
verifyElementPresent
Use this command when you must test for the presence of a specific UI element,
rather than its content. This verification does not check the text, only the
HTML tag. One common use is to check for the presence of an image.
Command
Target
Value
verifyElementPresent
//div/p/img
This command verifies that an image, specified by the existence of an
HTML tag, is present on the page, and that it follows a
tag and a
tag. The first (and only) parameter is a locator for telling the Selenese
command how to find the element. Locators are explained in the next section.
verifyElementPresent can be used to check the existence of any HTML tag within
the page. You can check the existence of links, paragraphs, divisions
,
etc. Here are a few more examples.
Command
Target
Value
verifyElementPresent
//div/p
verifyElementPresent
//div/a
verifyElementPresent
id=Login
verifyElementPresent
link=Go to Marketing Research
verifyElementPresent
//a[2]
verifyElementPresent
//head/title
These examples illustrate the variety of ways a UI element may be tested. Again,
locators are explained in the next section.
verifyText
Use verifyText when both the text and its UI element must be tested. verifyText
must use a locator. If you choose an XPath or DOM locator, you can verify that
specific text appears at a specific location on the page relative to other UI
components on the page.
Command
Target
Value
verifyText
//table/tr/td/div/p
This is my text and it occurs right after the div inside the table.
Locating Elements
For many Selenium commands, a target is required. This target identifies an
element in the content of the web application, and consists of the location
strategy followed by the location in the format locatorType=location. The
locator type can be omitted in many cases. The various locator types are
explained below with examples for each.
Locating by Identifier
This is probably the most common method of locating elements and is the
catch-all default when no recognized locator type is used. With this strategy,
the first element with the id attribute value matching the location will be used. If
no element has a matching id attribute, then the first element with a name
attribute matching the location will be used.
For instance, your page source could have id and name attributes
as follows:
The name locator type will locate the first element with a matching name
attribute. If multiple elements have the same value for a name attribute, then
you can use filters to further refine your location strategy. The default
filter type is value (matching the value attribute).
Note: Unlike some types of XPath and DOM locators, the three
types of locators above allow Selenium to test a UI element independent
of its location on
the page. So if the page structure and organization is altered, the test
will still pass. You may or may not want to also test whether the page
structure changes. In the case where web designers frequently alter the
page, but its functionality must be regression tested, testing via id and
name attributes, or really via any HTML property, becomes very important.
Locating by XPath
XPath is the language used for locating nodes in an XML document. As HTML can
be an implementation of XML (XHTML), Selenium users can leverage this powerful
language to target elements in their web applications. XPath extends beyond (as
well as supporting) the simple methods of locating by id or name
attributes, and opens up all sorts of new possibilities such as locating the
third checkbox on the page.
One of the main reasons for using XPath is when you don’t have a suitable id
or name attribute for the element you wish to locate. You can use XPath to
either locate the element in absolute terms (not advised), or relative to an
element that does have an id or name attribute. XPath locators can also be
used to specify elements via attributes other than id and name.
Absolute XPaths contain the location of all elements from the root (html) and
as a result are likely to fail with only the slightest adjustment to the
application. By finding a nearby element with an id or name attribute (ideally
a parent element) you can locate your target element based on the relationship.
This is much less likely to change and can make your tests more robust.
Since only xpath locators start with “//”, it is not necessary to include
the xpath= label when specifying an XPath locator.
xpath=/html/body/form[1] (3) - Absolute path (would break if the HTML was
changed only slightly)
//form[1] (3) - First form element in the HTML
xpath=//form[@id='loginForm'] (3) - The form element with attribute named ‘id’ and the value ’loginForm’
xpath=//form[input/@name='username'] (3) - First form element with an input child
element with attribute named ’name’ and the value ‘username’
//input[@name='username'] (4) - First input element with attribute named ’name’ and the value
‘username’
//form[@id='loginForm']/input[1] (4) - First input child element of the
form element with attribute named ‘id’ and the value ’loginForm’
//input[@name='continue'][@type='button'] (7) - Input with attribute named ’name’ and the value ‘continue’
and attribute named ’type’ and the value ‘button’
//form[@id='loginForm']/input[4] (7) - Fourth input child element of the
form element with attribute named ‘id’ and value ’loginForm’
These examples cover some basics, but in order to learn more, the
following references are recommended:
This is a simple method of locating a hyperlink in your web page by using the
text of the link. If two links with the same text are present, then the first
match will be used.
<html><body><p>Are you sure you want to do this?</p><ahref="continue.html">Continue</a><ahref="cancel.html">Cancel</a></body><html>
link=Continue (4)
link=Cancel (5)
Locating by DOM
The Document Object Model represents an HTML document and can be accessed
using JavaScript. This location strategy takes JavaScript that evaluates to
an element on the page, which can be simply the element’s location using the
hierarchical dotted notation.
Since only dom locators start with “document”, it is not necessary to include
the dom= label when specifying a DOM locator.
You can use Selenium itself as well as other sites and extensions to explore
the DOM of your web application. A good reference exists on W3Schools.
Locating by CSS
CSS (Cascading Style Sheets) is a language for describing the rendering of HTML
and XML documents. CSS uses Selectors for binding style properties to elements
in the document. These Selectors can be used by Selenium as another locating
strategy.
For more information about CSS Selectors, the best place to go is the W3C
publication. You’ll find additional
references there.
Implicit Locators
You can choose to omit the locator type in the following situations:
Locators without an explicitly defined locator strategy will default
to using the identifier locator strategy. See Locating by Identifier_.
Locators starting with “//” will use the XPath locator strategy.
See Locating by XPath_.
Locators starting with “document” will use the DOM locator strategy.
See Locating by DOM_
Matching Text Patterns
Like locators, patterns are a type of parameter frequently required by Selenese
commands. Examples of commands which require patterns are verifyTextPresent,
verifyTitle, verifyAlert, assertConfirmation, verifyText, and
verifyPrompt. And as has been mentioned above, link locators can utilize
a pattern. Patterns allow you to describe, via the use of special characters,
what text is expected rather than having to specify that text exactly.
There are three types of patterns: globbing, regular expressions, and exact.
Globbing Patterns
Most people are familiar with globbing as it is utilized in
filename expansion at a DOS or Unix/Linux command line such as ls *.c.
In this case, globbing is used to display all the files ending with a .c
extension that exist in the current directory. Globbing is fairly limited. Only two special characters are supported in the Selenium implementation:
* which translates to “match anything,” i.e., nothing, a single character, or many characters.
[ ] (character class) which translates to “match any single character
found inside the square brackets.” A dash (hyphen) can be used as a shorthand
to specify a range of characters (which are contiguous in the ASCII character
set). A few examples will make the functionality of a character class clear:
[aeiou] matches any lowercase vowel
[0-9] matches any digit
[a-zA-Z0-9] matches any alphanumeric character
In most other contexts, globbing includes a third special character, the ?.
However, Selenium globbing patterns only support the asterisk and character
class.
To specify a globbing pattern parameter for a Selenese command, you can
prefix the pattern with a glob: label. However, because globbing
patterns are the default, you can also omit the label and specify just the
pattern itself.
Below is an example of two commands that use globbing patterns. The
actual link text on the page being tested
was “Film/Television Department”; by using a pattern
rather than the exact text, the click command will work even if the
link text is changed to “Film & Television Department” or “Film and Television
Department”. The glob pattern’s asterisk will match “anything or nothing”
between the word “Film” and the word “Television”.
Command
Target
Value
click
link=glob:Film*Television Department
verifyTitle
glob:*Film*Television*
The actual title of the page reached by clicking on the link was “De Anza Film And
Television Department - Menu”. By using a pattern rather than the exact
text, the verifyTitle will pass as long as the two words “Film” and “Television” appear
(in that order) anywhere in the page’s title. For example, if
the page’s owner should shorten
the title to just “Film & Television Department,” the test would still pass.
Using a pattern for both a link and a simple test that the link worked (such as
the verifyTitle above does) can greatly reduce the maintenance for such
test cases.
Regular Expression Patterns
Regular expression patterns are the most powerful of the three types
of patterns that Selenese supports. Regular expressions
are also supported by most high-level programming languages, many text
editors, and a host of tools, including the Linux/Unix command-line
utilities grep, sed, and awk. In Selenese, regular
expression patterns allow a user to perform many tasks that would
be very difficult otherwise. For example, suppose your test needed
to ensure that a particular table cell contained nothing but a number.
regexp: [0-9]+ is a simple pattern that will match a decimal number of any length.
Whereas Selenese globbing patterns support only the *
and [ ] (character
class) features, Selenese regular expression patterns offer the same
wide array of special characters that exist in JavaScript. Below
are a subset of those special characters:
PATTERN
MATCH
.
any single character
[ ]
character class: any single character that appears inside the brackets
*
quantifier: 0 or more of the preceding character (or group)
+
quantifier: 1 or more of the preceding character (or group)
?
quantifier: 0 or 1 of the preceding character (or group)
{1,5}
quantifier: 1 through 5 of the preceding character (or group)
|
alternation: the character/group on the left or the character/group on the right
( )
grouping: often used with alternation and/or quantifier
Regular expression patterns in Selenese need to be prefixed with
either regexp: or regexpi:. The former is case-sensitive; the
latter is case-insensitive.
A few examples will help clarify how regular expression patterns can
be used with Selenese commands. The first one uses what is probably
the most commonly used regular expression pattern–.* (“dot star”). This
two-character sequence can be translated as “0 or more occurrences of
any character” or more simply, “anything or nothing.” It is the
equivalent of the one-character globbing pattern * (a single asterisk).
Command
Target
Value
click
link=glob:Film*Television Department
verifyTitle
regexp:.*Film.*Television.*
The example above is functionally equivalent to the earlier example
that used globbing patterns for this same test. The only differences
are the prefix (regexp: instead of glob:) and the “anything
or nothing” pattern (.* instead of just *).
The more complex example below tests that the Yahoo!
Weather page for Anchorage, Alaska contains info on the sunrise time:
Let’s examine the regular expression above one part at a time:
Sunrise: *
The string Sunrise: followed by 0 or more spaces
[0-9]{1,2}
1 or 2 digits (for the hour of the day)
:
The character : (no special characters involved)
[0-9]{2}
2 digits (for the minutes) followed by a space
[ap]m
“a” or “p” followed by “m” (am or pm)
Exact Patterns
The exact type of Selenium pattern is of marginal usefulness.
It uses no special characters at all. So, if you needed to look for
an actual asterisk character (which is special for both globbing and
regular expression patterns), the exact pattern would be one way
to do that. For example, if you wanted to select an item labeled
“Real *” from a dropdown, the following code might work or it might not.
The asterisk in the glob:Real * pattern will match anything or nothing.
So, if there was an earlier select option labeled “Real Numbers,” it would
be the option selected rather than the “Real *” option.
Command
Target
Value
select
//select
glob:Real *
In order to ensure that the “Real *” item would be selected, the exact:
prefix could be used to create an exact pattern as shown below:
Command
Target
Value
select
//select
exact:Real *
But the same effect could be achieved via escaping the asterisk in a
regular expression pattern:
Command
Target
Value
select
//select
regexp:Real \*
It’s rather unlikely that most testers will ever need to look for
an asterisk or a set of square brackets with characters inside them (the
character class for globbing patterns). Thus, globbing patterns and
regular expression patterns are sufficient for the vast majority of us.
The “AndWait” Commands
The difference between a command and its AndWait
alternative is that the regular command (e.g. click) will do the action and
continue with the following command as fast as it can, while the AndWait
alternative (e.g. clickAndWait) tells Selenium to wait for the page to
load after the action has been done.
The AndWait alternative is always used when the action causes the browser to
navigate to another page or reload the present one.
Be aware, if you use an AndWait command for an action that
does not trigger a navigation/refresh, your test will fail. This happens
because Selenium will reach the AndWait’s timeout without seeing any
navigation or refresh being made, causing Selenium to raise a timeout
exception.
The waitFor Commands in AJAX applications
In AJAX driven web applications, data is retrieved from server without
refreshing the page. Using andWait commands will not work as the page is not
actually refreshed. Pausing the test execution for a certain period of time is
also not a good approach as web element might appear later or earlier than the
stipulated period depending on the system’s responsiveness, load or other
uncontrolled factors of the moment, leading to test failures. The best approach
would be to wait for the needed element in a dynamic period and then continue
the execution as soon as the element is found.
This is done using waitFor commands, as waitForElementPresent or
waitForVisible, which wait dynamically, checking for the desired condition
every second and continuing to the next command in the script as soon as the
condition is met.
Sequence of Evaluation and Flow Control
When a script runs, it simply runs in sequence, one command after another.
Selenese, by itself, does not support condition statements (if-else, etc.) or
iteration (for, while, etc.). Many useful tests can be conducted without flow
control. However, for a functional test of dynamic content, possibly involving
multiple pages, programming logic is often needed.
When flow control is needed, there are three options:
a) Run the script using Selenium-RC and a client library such as Java or
PHP to utilize the programming language’s flow control features.
b) Run a small JavaScript snippet from within the script using the storeEval command.
c) Install the goto_sel_ide.js extension.
Most testers will export the test script into a programming language file that uses the
Selenium-RC API (see the Selenium-IDE chapter). However, some organizations prefer
to run their scripts from Selenium-IDE whenever possible (for instance, when they have
many junior-level people running tests for them, or when programming skills are
lacking). If this is your case, consider a JavaScript snippet or the goto_sel_ide.js extension.
Store Commands and Selenium Variables
You can use Selenium variables to store constants at the
beginning of a script. Also, when combined with a data-driven test design
(discussed in a later section), Selenium variables can be used to store values
passed to your test program from the command-line, from another program, or from
a file.
The plain store command is the most basic of the many store commands and can be used
to simply store a constant value in a Selenium variable. It takes two
parameters, the text value to be stored and a Selenium variable. Use the
standard variable naming conventions of only alphanumeric characters when
choosing a name for your variable.
Later in your script, you’ll want to use the stored value of your
variable. To access the value of a variable, enclose the variable in
curly brackets ({}) and precede it with a dollar sign like this.
Command
Target
Value
verifyText
//div/p
\${userName}
A common use of variables is for storing input for an input field.
Command
Target
Value
type
id=login
\${userName}
Selenium variables can be used in either the first or second parameter and
are interpreted by Selenium prior to any other operations performed by the
command. A Selenium variable may also be used within a locator expression.
An equivalent store command exists for each verify and assert command. Here
are a couple more commonly used store commands.
storeElementPresent
This corresponds to verifyElementPresent. It simply stores a boolean value–“true”
or “false”–depending on whether the UI element is found.
storeText
StoreText corresponds to verifyText. It uses a locator to identify specific
page text. The text, if found, is stored in the variable. StoreText can be
used to extract text from the page being tested.
storeEval
This command takes a script as its
first parameter. Embedding JavaScript within Selenese is covered in the next section.
StoreEval allows the test to store the result of running the script in a variable.
JavaScript and Selenese Parameters
JavaScript can be used with two types of Selenese parameters: script
and non-script (usually expressions). In most cases, you’ll want to access
and/or manipulate a test case variable inside the JavaScript snippet used as
a Selenese parameter. All variables created in your test case are stored in
a JavaScript associative array. An associative array has string indexes
rather than sequential numeric indexes. The associative array containing
your test case’s variables is named storedVars. Whenever you wish to
access or manipulate a variable within a JavaScript snippet, you must refer
to it as storedVars[‘yourVariableName’].
JavaScript Usage with Script Parameters
Several Selenese commands specify a script parameter including
assertEval, verifyEval, storeEval, and waitForEval.
These parameters require no special syntax. A Selenium-IDE
user would simply place a snippet of JavaScript code into
the appropriate field, normally the Target field (because
a script parameter is normally the first or only parameter).
The example below illustrates how a JavaScript snippet
can be used to perform a simple numerical calculation:
Command
Target
Value
store
10
hits
storeXpathCount
//blockquote
blockquotes
storeEval
storedVars[‘hits’].storedVars[‘blockquotes’]
paragraphs
This next example illustrates how a JavaScript snippet can include calls to
methods, in this case the JavaScript String object’s toUpperCase method
and toLowerCase method.
Command
Target
Value
store
Edith Wharton
name
storeEval
storedVars[’name’].toUpperCase()
uc
storeEval
storedVars[’name’].toUpperCase()
lc
JavaScript Usage with Non-Script Parameters
JavaScript can also be used to help generate values for parameters, even
when the parameter is not specified to be of type script. However, in this case, special syntax is required–the entire parameter
value must be prefixed by javascript{ with a trailing }, which encloses the JavaScript
snippet, as in javascript{*yourCodeHere*}.
Below is an example in which the type command’s second parameter
value is generated via JavaScript code using this special syntax:
Selenese has a simple command that allows you to print text to your test’s
output. This is useful for providing informational progress notes in your
test which display on the console as your test is running. These notes also can be
used to provide context within your test result reports, which can be useful
for finding where a defect exists on a page in the event your test finds a
problem. Finally, echo statements can be used to print the contents of
Selenium variables.
Command
Target
Value
echo
Testing page footer now.
echo
Username is \${userName}
Alerts, Popups, and Multiple Windows
Suppose that you are testing a page that looks like this.
<!DOCTYPE HTML><html><head><scripttype="text/javascript">functionoutput(resultText){document.getElementById('output').childNodes[0].nodeValue=resultText;}functionshow_confirm(){varconfirmation=confirm("Chose an option.");if(confirmation==true){output("Confirmed.");}else{output("Rejected!");}}functionshow_alert(){alert("I'm blocking!");output("Alert is gone.");}functionshow_prompt(){varresponse=prompt("What's the best web QA tool?","Selenium");output(response);}functionopen_window(windowName){window.open("newWindow.html",windowName);}</script></head><body><inputtype="button"id="btnConfirm"onclick="show_confirm()"value="Show confirm box"/><inputtype="button"id="btnAlert"onclick="show_alert()"value="Show alert"/><inputtype="button"id="btnPrompt"onclick="show_prompt()"value="Show prompt"/><ahref="newWindow.html"id="lnkNewWindow"target="_blank">New Window Link</a><inputtype="button"id="btnNewNamelessWindow"onclick="open_window()"value="Open Nameless Window"/><inputtype="button"id="btnNewNamedWindow"onclick="open_window('Mike')"value="Open Named Window"/><br/><spanid="output"></span></body></html>
The user must respond to alert/confirm boxes, as well as moving focus to newly
opened popup windows. Fortunately, Selenium can cover JavaScript pop-ups.
But before we begin covering alerts/confirms/prompts in individual detail, it is
helpful to understand the commonality between them. Alerts, confirmation boxes
and prompts all have variations of the following
Command
Description
assertFoo(pattern)
throws error if pattern doesn’t match the text of the pop-up
assertFooPresent
throws error if pop-up is not available
assertFooNotPresent
throws error if any pop-up is present
storeFoo(variable)
stores the text of the pop-up in a variable
storeFooPresent(variable)
stores the text of the pop-up in a variable and returns true or false
When running under Selenium, JavaScript pop-ups will not appear. This is because
the function calls are actually being overridden at runtime by Selenium’s own
JavaScript. However, just because you cannot see the pop-up doesn’t mean you don’t
have to deal with it. To handle a pop-up, you must call its assertFoo(pattern)
function. If you fail to assert the presence of a pop-up your next command will be
blocked and you will get an error similar to the following [error] Error: There was an unexpected Confirmation! [Chose an option.]
Alerts
Let’s start with alerts because they are the simplest pop-up to handle. To begin,
open the HTML sample above in a browser and click on the “Show alert” button. You’ll
notice that after you close the alert the text “Alert is gone.” is displayed on the
page. Now run through the same steps with Selenium IDE recording, and verify
the text is added after you close the alert. Your test will look something like
this:
Command
Target
Value
open
/
click
btnAlert
assertAlert
I’m blocking!
verifyTextPresent
Alert is gone.
You may be thinking “That’s odd, I never tried to assert that alert.” But this is
Selenium-IDE handling and closing the alert for you. If you remove that step and replay
the test you will get the following error [error] Error: There was an unexpected Alert! [I'm blocking!]. You must include an assertion of the alert to acknowledge
its presence.
If you just want to assert that an alert is present but either don’t know or don’t care
what text it contains, you can use assertAlertPresent. This will return true or false,
with false halting the test.
Confirmations
Confirmations behave in much the same way as alerts, with assertConfirmation and
assertConfirmationPresent offering the same characteristics as their alert counterparts.
However, by default Selenium will select OK when a confirmation pops up. Try recording
clicking on the “Show confirm box” button in the sample page, but click on the “Cancel” button
in the popup, then assert the output text. Your test may look something like this:
Command
Target
Value
open
/
click
btnConfirm
chooseCancelOnNextConfirmation
assertConfirmation
Choose an option.
verifyTextPresent
Rejected
The chooseCancelOnNextConfirmation function tells Selenium that all following
confirmation should return false. It can be reset by calling chooseOkOnNextConfirmation.
You may notice that you cannot replay this test, because Selenium complains that there
is an unhandled confirmation. This is because the order of events Selenium-IDE records
causes the click and chooseCancelOnNextConfirmation to be put in the wrong order (it makes sense
if you think about it, Selenium can’t know that you’re cancelling before you open a confirmation)
Simply switch these two commands and your test will run fine.
Prompts
Prompts behave in much the same way as alerts, with assertPrompt and assertPromptPresent
offering the same characteristics as their alert counterparts. By default, Selenium will wait for
you to input data when the prompt pops up. Try recording clicking on the “Show prompt” button in
the sample page and enter “Selenium” into the prompt. Your test may look something like this:
Command
Target
Value
open
/
answerOnNextPrompt
Selenium!
click
id=btnPrompt
assertPrompt
What’s the best web QA tool?
verifyTextPresent
Selenium!
If you choose cancel on the prompt, you may notice that answerOnNextPrompt will simply show a
target of blank. Selenium treats cancel and a blank entry on the prompt basically as the same thing.
Debugging
Debugging means finding and fixing errors in your test case. This is a normal
part of test case development.
We won’t teach debugging here as most new users to Selenium will already have
some basic experience with debugging. If this is new to you, we recommend
you ask one of the developers in your organization.
Breakpoints and Startpoints
The Sel-IDE supports the setting of breakpoints and the ability to start and
stop the running of a test case, from any point within the test case. That is, one
can run up to a specific command in the middle of the test case and inspect how
the test case behaves at that point. To do this, set a breakpoint on the
command just before the one to be examined.
To set a breakpoint, select a command, right-click, and from the context menu
select Toggle Breakpoint. Then click the Run button to run your test case from
the beginning up to the breakpoint.
It is also sometimes useful to run a test case from somewhere in the middle to
the end of the test case or up to a breakpoint that follows the starting point. For example, suppose your test case first logs into the website and then
performs a series of tests and you are trying to debug one of those tests. However, you only need to login once, but you need to keep rerunning your
tests as you are developing them. You can login once, then run your test case
from a startpoint placed after the login portion of your test case. That will
prevent you from having to manually logout each time you rerun your test case.
To set a startpoint, select a command, right-click, and from the context
menu select Set/Clear Start Point. Then click the Run button to execute the
test case beginning at that startpoint.
Stepping Through a Testcase
To execute a test case one command at a time (“step through” it), follow these
steps:
Start the test case running with the Run button from the toolbar.
Immediately pause the executing test case with the Pause button.
Repeatedly select the Step button.
Find Button
The Find button is used to see which UI element on the currently displayed
webpage (in the browser) is used in the currently selected Selenium command. This is useful when building a locator for a command’s first parameter (see the
section on :ref:locators <locators-section> in the Selenium Commands chapter).
It can be used with any command that identifies a UI element on a webpage,
i.e. click, clickAndWait, type, and certain assert and verify commands,
among others.
From Table view, select any command that has a locator parameter.
Click the Find button. Now look on the webpage: There should be a bright green rectangle
enclosing the element specified by the locator parameter.
Page Source for Debugging
Often, when debugging a test case, you simply must look at the page source (the
HTML for the webpage you’re trying to test) to determine a problem. Firefox
makes this easy. Simply right-click the webpage and select ‘View->Page Source. The HTML opens in a separate window. Use its Search feature (Edit=>Find)
to search for a keyword to find the HTML for the UI element you’re trying
to test.
Alternatively, select just that portion of the webpage for which you want to
see the source. Then right-click the webpage and select View Selection
Source. In this case, the separate HTML window will contain just a small
amount of source, with highlighting on the portion representing your
selection.
Locator Assistance
Whenever Selenium-IDE records a locator-type argument, it stores
additional information which allows the user to view other possible
locator-type arguments that could be used instead. This feature can be
very useful for learning more about locators, and is often needed to help
one build a different type of locator than the type that was recorded.
This locator assistance is presented on the Selenium-IDE window as a drop-down
list accessible at the right end of the Target field
(only when the Target field contains a recorded locator-type argument). Below is a snapshot showing the
contents of this drop-down for one command. Note that the first column of
the drop-down provides alternative locators, whereas the second column
indicates the type of each alternative.
Writing a Test Suite
A test suite is a collection of test cases which is displayed in the leftmost
pane in the IDE. The test suite pane can be manually opened or closed via selecting a small dot
halfway down the right edge of the pane (which is the left edge of the
entire Selenium-IDE window if the pane is closed).
The test suite pane will be automatically opened when an existing test suite
is opened or when the user selects the New Test Case item from the
File menu. In the latter case, the new test case will appear immediately
below the previous test case.
Selenium-IDE also supports loading pre-existing test cases by using the File
-> Add Test Case menu option. This allows you to add existing test cases to
a new test suite.
A test suite file is an HTML file containing a one-column table. Each
cell of each row in the
section contains a link to a test case.
The example below is of a test suite containing four test cases:
<html><head><metahttp-equiv="Content-Type"content="text/html; charset=UTF-8"><title>Sample Selenium Test Suite</title></head><body><tablecellpadding="1"cellspacing="1"border="1"><thead><tr><td>Test Cases for De Anza A-Z Directory Links</td></tr></thead><tbody><tr><td><ahref="./a.html">A Links</a></td></tr><tr><td><ahref="./b.html">B Links</a></td></tr><tr><td><ahref="./c.html">C Links</a></td></tr><tr><td><ahref="./d.html">D Links</a></td></tr></tbody></table></body></html>
Note: Test case files should not have to be co-located with the test suite file
that invokes them. And on Mac OS and Linux systems, that is indeed the
case. However, at the time of this writing, a bug prevents Windows users
from being able to place the test cases elsewhere than with the test suite
that invokes them.
User Extensions
User extensions are JavaScript files that allow one to create his or her own
customizations and features to add additional functionality. Often this is in
the form of customized commands although this extensibility is not limited to
additional commands.
There are a number of useful extensions_ created by users.
IMPORTANT: THIS SECTION IS OUT OF DATE–WE WILL BE REVISING THIS SOON.
Perhaps the most popular of all Selenium-IDE extensions
is one which provides flow control in the form of while loops and primitive
conditionals. This extension is the goto_sel_ide.js_. For an example
of how to use the functionality provided by this extension, look at the
page_ created by its author.
To install this extension, put the pathname to its location on your
computer in the Selenium Core extensions field of Selenium-IDE’s
Options=>Options=>General tab.
After selecting the OK button, you must close and reopen Selenium-IDE
in order for the extensions file to be read. Any change you make to an
extension will also require you to close and reopen Selenium-IDE.
Information on writing your own extensions can be found near the
bottom of the Selenium Reference_ document.
Sometimes it can prove very useful to debug step by step Selenium IDE and your
User Extension. The only debugger that appears able to debug
XUL/Chrome based extensions is Venkman which is supported in Firefox until version 32 included.
The step by step debug has been verified to work with Firefox 32 and Selenium IDE 2.9.0.
Format
Format, under the Options menu, allows you to select a language for saving
and displaying the test case. The default is HTML.
If you will be using Selenium-RC to run your test cases, this feature is used
to translate your test case into a programming language. Select the
language, e.g. Java, PHP, you will be using with Selenium-RC for developing
your test programs. Then simply save the test case using File=>Export Test Case As.
Your test case will be translated into a series of functions in the language you
choose. Essentially, program code supporting your test is generated for you
by Selenium-IDE.
Also, note that if the generated code does not suit your needs, you can alter
it by editing a configuration file which defines the generation process. Each supported language has configuration settings which are editable. This
is under the Options=>Options=>Formats tab.
Executing Selenium-IDE Tests on Different Browsers
While Selenium-IDE can only run tests against Firefox, tests
developed with Selenium-IDE can be run against other browsers, using a
simple command-line interface that invokes the Selenium-RC server. This topic
is covered in the :ref:Run Selenese tests <html-suite> section on Selenium-RC
chapter. The -htmlSuite command-line option is the particular feature of interest.
Troubleshooting
Below is a list of image/explanation pairs which describe frequent
sources of problems with Selenium-IDE:
Table view is not available with this format.
This message can be occasionally displayed in the Table tab when Selenium IDE is
launched. The workaround is to close and reopen Selenium IDE. See
issue 1008.
for more information. If you are able to reproduce this reliably then please
provide details so that we can work on a fix.
error loading test case: no command found
You’ve used File=>Open to try to open a test suite file. Use File=>Open
Test Suite instead.
An enhancement request has been raised to improve this error message. See
issue 1010.
This type of error may indicate a timing problem, i.e., the element
specified by a locator in your command wasn’t fully loaded when the command
was executed. Try putting a pause 5000 before the command to determine
whether the problem is indeed related to timing. If so, investigate using an
appropriate waitFor* or *AndWait command before the failing command.
Whenever your attempt to use variable substitution fails as is the
case for the open command above, it indicates
that you haven’t actually created the variable whose value you’re
trying to access. This is
sometimes due to putting the variable in the Value field when it
should be in the Target field or vice versa. In the example above,
the two parameters for the store command have been erroneously
placed in the reverse order of what is required.
For any Selenese command, the first required parameter must go
in the Target field, and the second required parameter (if one exists)
must go in the Value field.
error loading test case: [Exception… “Component returned failure code:
0x80520012 (NS_ERROR_FILE_NOT_FOUND) [nsIFileInputStream.init]” nresult:
“0x80520012 (NS_ERROR_FILE_NOT_FOUND)” location: “JS frame ::
chrome://selenium-ide/content/file-utils.js :: anonymous :: line 48” data: no]
One of the test cases in your test suite cannot be found. Make sure that the
test case is indeed located where the test suite indicates it is located. Also,
make sure that your actual test case files have the .html extension both in
their filenames, and in the test suite file where they are referenced.
An enhancement request has been raised to improve this error message. See
issue 1011.
Your extension file’s contents have not been read by Selenium-IDE. Be
sure you have specified the proper pathname to the extensions file via
Options=>Options=>General in the Selenium Core extensions field.
Also, Selenium-IDE must be restarted after any change to either an
extensions file or to the contents of the Selenium Core extensions
field.
8.4.1 - HTML runner
Execute HTML Selenium IDE exports from command line
Selenium HTML-runner 允许您从命令行运行 Test Suites。
Test Suites 是从 Selenium IDE 或兼容工具导出的 HTML。
[user@localhost ~]$ xvfb-run java -Dwebdriver.gecko.driver=/home/mmasek/geckodriver.0.18.0 -jar selenium-html-runner-3.7.1.jar -htmlSuite "*firefox""https://YOUR-BASE-URL""$(pwd)/testsuite.html""results.html"; grep result: -A1 results.html/firefox.results.html
Multi-window mode is longer used as an option and will be ignored.
1510061109691 geckodriver INFO geckodriver 0.18.0
1510061109708 geckodriver INFO Listening on 127.0.0.1:2885
1510061110162 geckodriver::marionette INFO Starting browser /usr/bin/firefox with args ["-marionette"]1510061111084 Marionette INFO Listening on port 432291510061111187 Marionette WARN TLS certificate errors will be ignored for this session
Nov 07, 2017 1:25:12 PM org.openqa.selenium.remote.ProtocolHandshake createSession
INFO: Detected dialect: W3C
2017-11-07 13:25:12.714:INFO::main: Logging initialized @3915ms to org.seleniumhq.jetty9.util.log.StdErrLog
2017-11-07 13:25:12.804:INFO:osjs.Server:main: jetty-9.4.z-SNAPSHOT
2017-11-07 13:25:12.822:INFO:osjsh.ContextHandler:main: Started o.s.j.s.h.ContextHandler@87a85e1{/tests,null,AVAILABLE}2017-11-07 13:25:12.843:INFO:osjs.AbstractConnector:main: Started ServerConnector@52102734{HTTP/1.1,[http/1.1]}{0.0.0.0:31892}2017-11-07 13:25:12.843:INFO:osjs.Server:main: Started @4045ms
Nov 07, 2017 1:25:13 PM org.openqa.selenium.server.htmlrunner.CoreTestCase run
INFO: |open | /auth_mellon.php ||Nov 07, 2017 1:25:14 PM org.openqa.selenium.server.htmlrunner.CoreTestCase run
INFO: |waitForPageToLoad |3000||.
.
.etc
<td>result:</td>
<td>PASS</td>
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
We want to be able to run all of our code examples in the CI to ensure that people can copy and paste and
execute everything on the site. So we put the code where it belongs in the
examples directory.
Each page in the documentation correlates to a test file in each of the languages, and should follow naming conventions.
For instance examples for this page https://www.selenium.dev/documentation/webdriver/browsers/chrome/ get added in these
files:
Each example should get its own test. Ideally each test has an assertion that verifies the code works as intended.
Once the code is copied to its own test in the proper file, it needs to be referenced in the markdown file.
For example, the tab in Ruby would look like this:
The line numbers at the end represent only the line or lines of code that actually represent the item being displayed.
If a user wants more context, they can click the link to the GitHub page that will show the full context.
Make sure that if you add a test to the page that all the other line numbers in the markdown file are still
correct. Adding a test at the top of a page means updating every single reference in the documentation that has a line
number for that file.
Everything from the Creating Examples section applies, with one addition.
Make sure the tab includes text=true. By default, the tabs get formatted
for code, so to use markdown or other shortcode statements (like gh-codeblock) it needs to be declared as text.
For most examples, the tabpane declares the text=true, but if some of the tabs have code examples, the tabpane
cannot specify it, and it must be specified in the tabs that do not need automatic code formatting.
explain commit normatively in one line
Body of commit message is a few lines of text, explaining things
in more detail, possibly giving some background about the issue
being fixed, etc.
The body of the commit message can be several paragraphs, and
please do proper word-wrap and keep columns shorter than about
72 characters or so. That way `git log` will show things
nicely even when it is indented.
Fixes #141
Our documentation uses Title Capitalization for linkTitle which should be short
and Sentence capitalization for title which can be longer and more descriptive.
For example, a linkTitle of Special Heading might have a title of
The importance of a special heading in documentation
Line length
When editing the documentation’s source,
which is written in plain HTML,
limit your line lengths to around 100 characters.
Some of us take this one step further
and use what is called
semantic linefeeds,
which is a technique whereby the HTML source lines,
which are not read by the public,
are split at ‘natural breaks’ in the prose.
In other words, sentences are split
at natural breaks between clauses.
Instead of fussing with the lines of each paragraph
so that they all end near the right margin,
linefeeds can be added anywhere
that there is a break between ideas.
This can make diffs very easy to read
when collaborating through git,
but it is not something we enforce contributors to use.
Translations
Selenium now has official translators for each of the supported languages.
If you add a code example to the important_documentation.en.md file,
also add it to important_documentation.ja.md, important_documentation.pt-br.md,
important_documentation.zh-cn.md.
If you make text changes in the English version, just make a Pull Request.
The new process is for issues to be created and tagged as needs translation based on
changes made in a given PR.
Code examples
All references to code should be language independent,
and the code itself should be placed inside code tabs.
To generate the above tabs, this is what you need to write.
Note that the tabpane includes langEqualsHeader=true.
This auto-formats the code in each tab to match the header name,
and ensures that all tabs on the page with a language are set to the same thing.
To ensure that all code is kept up to date, our goal is to write the code in the repo where it
can be executed when Selenium versions are updated to ensure that everything is correct.
This code can be automatically displayed in the documentation using the gh-codeblock shortcode.
The shortcode automatically generates its own html, so we do not want it to auto-format with the language header.
If all tabs are using this shortcode, set text=true in the tabpane and remove langEqualsHeader=true.
If only some tabs are using this shortcode, keep langEqualsHeader=true in the tabpane and add text=true
to the tab. Note that the gh-codeblock line can not be indented at all.
One great thing about using gh-codeblock is that it adds a link to the full example.
This means you don’t have to include any additional context code, just the line(s) that
are needed, and the user can navigate to the repo to see how to use it.
If you want your example to include something other than code (default) or html (from gh-codeblock),
you need to first set text=true,
then change the Hugo syntax for the tabto use % instead of < and > with curly braces:
This is preferred to writing code comments because those will not be translated.
Only include the code that is needed for the documentation, and avoid over-explaining.
Finally, remember not to indent plain text or it will rendered as a codeblock.