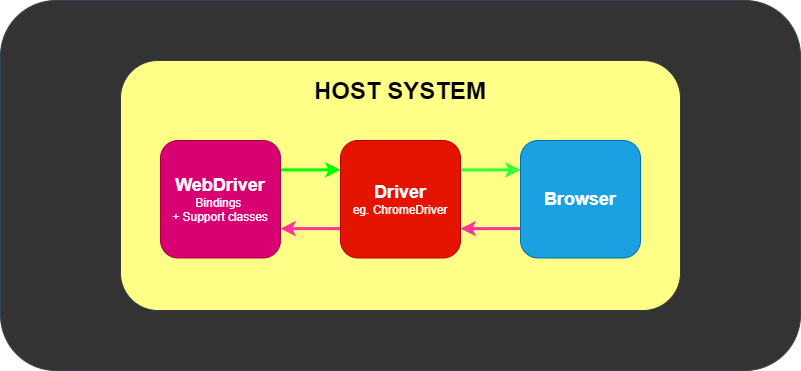
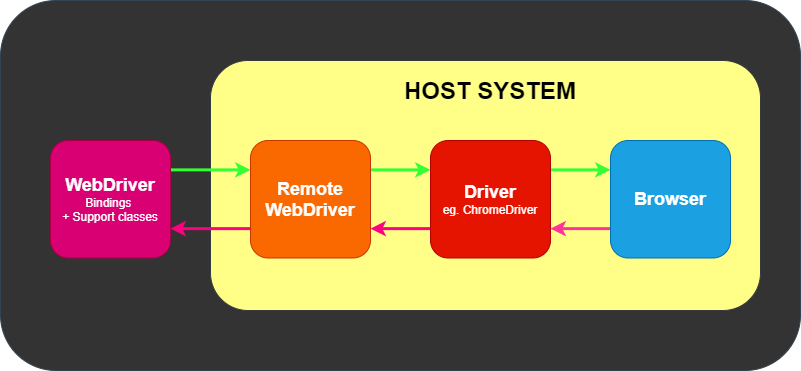
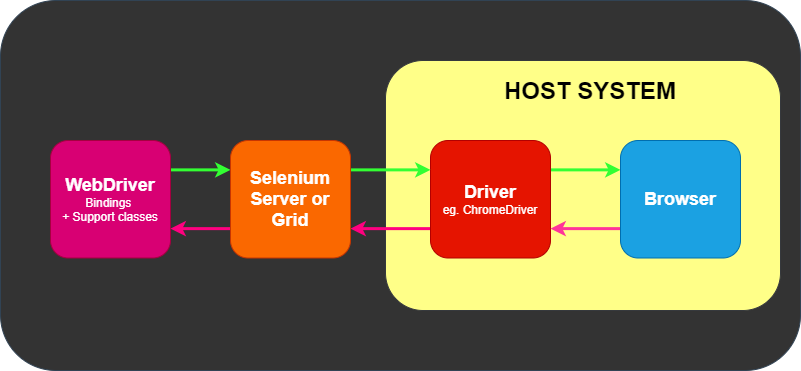
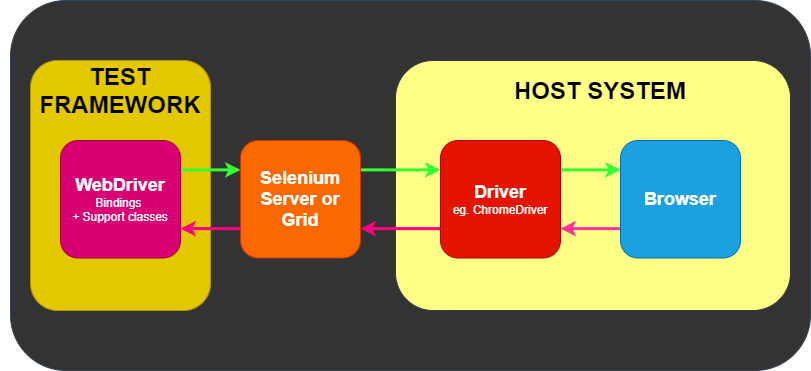
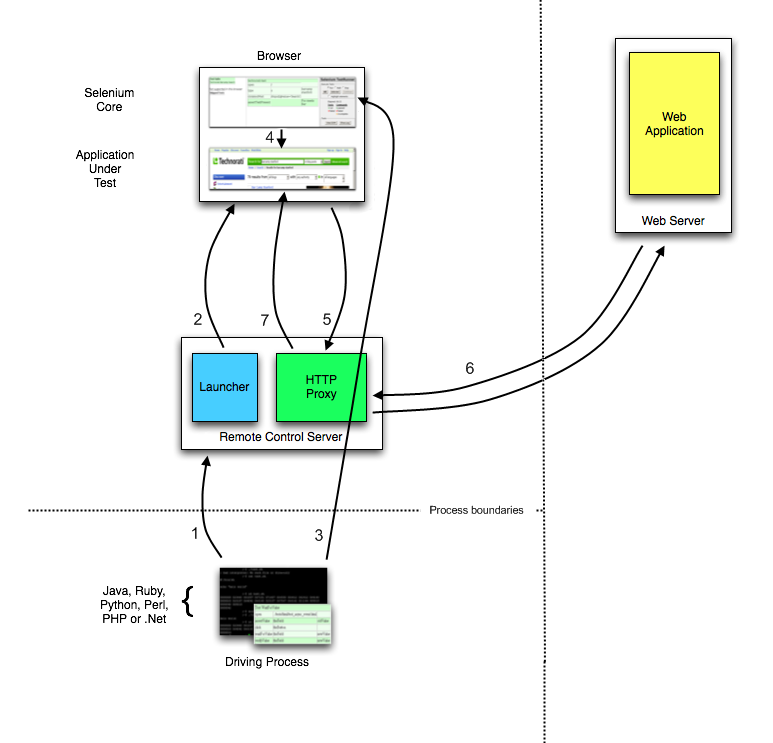
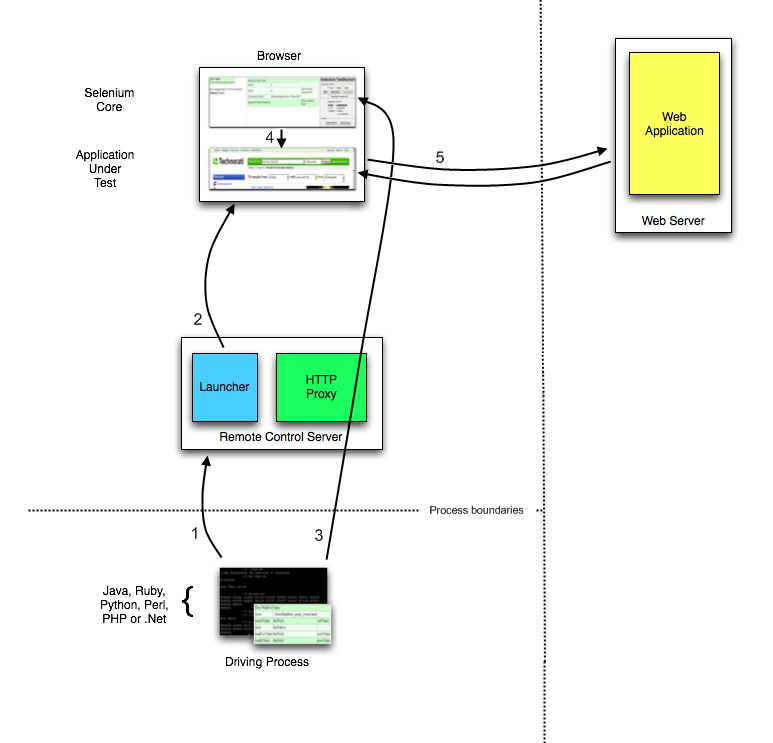
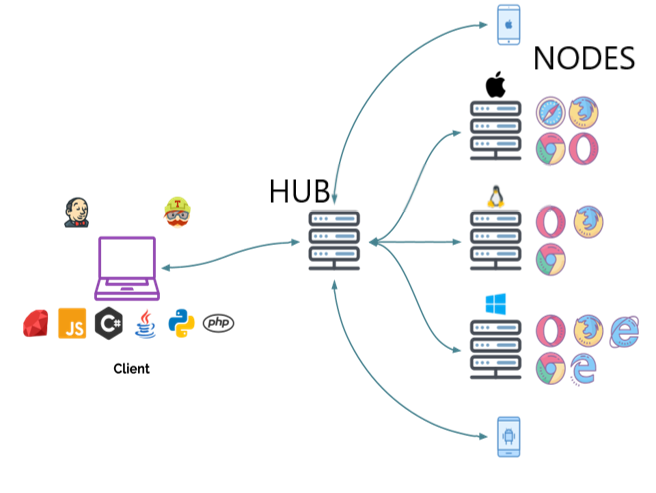
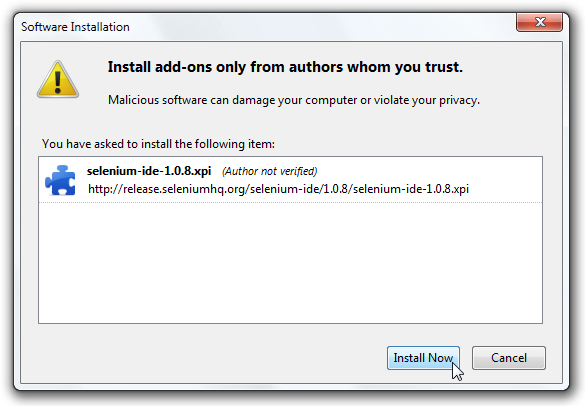
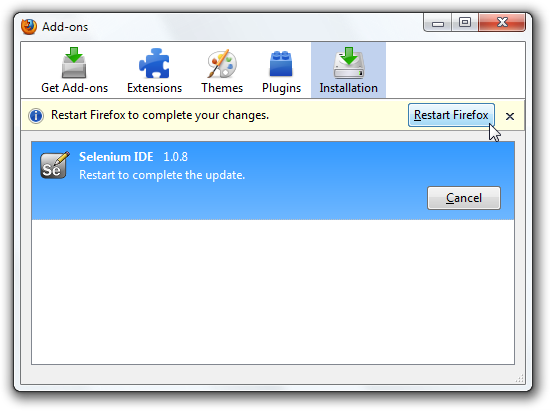
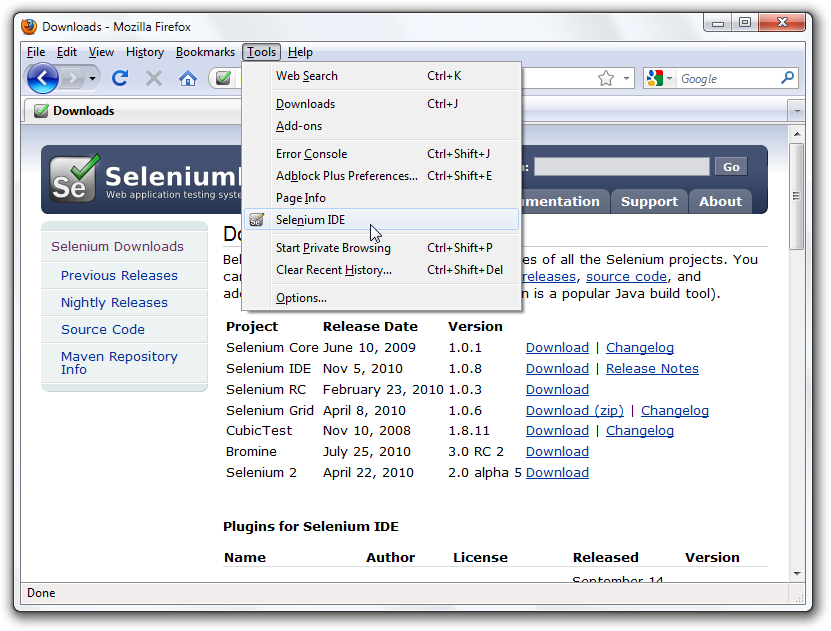
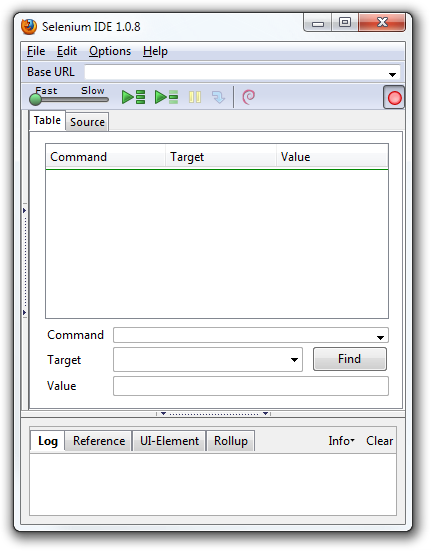
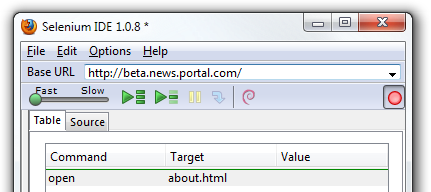
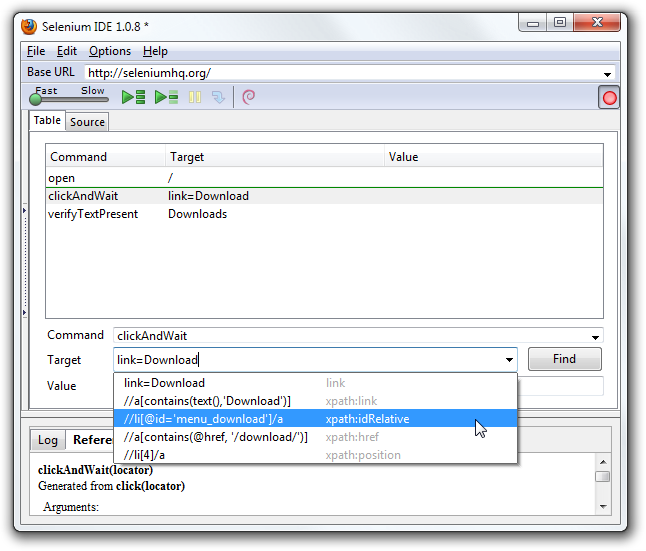
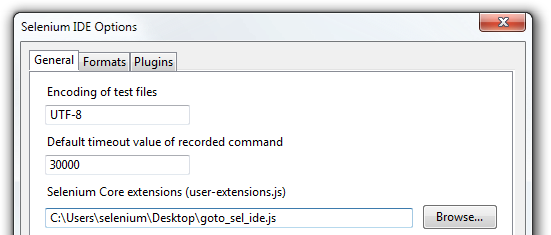
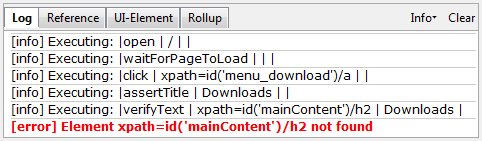
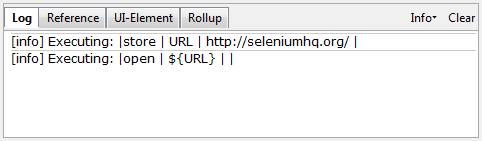
IDE (Integrated Development Environment: 統合開発環境)はSeleniumのテストケースを開発するためのツールです。
これは利用しやすいChromeとFirefoxの拡張機能であり、テストケースを開発するための一般に最も効率的なツールです。
IDEはあなたのブラウザ上で、その要素で定義されたパラメーターと共にSeleniumのコマンドを使いユーザーの動作を記録します。
これは時間の節約だけでなく、Seleniumスクリプトのシンタックスを学ぶための優れた方法です。
ドライバーは、ChromeDriver for GoogleのChrome/Chromium、MozillaのFirefox用GeckoDriverなどブラウザー固有のものです。
ドライバーはブラウザと同じシステムで動きます。これは、テスト自体を実行するところが同じシステムである場合とそうでない場合があります。
ChromiumNetworkConditionsnetworkConditions=newChromiumNetworkConditions();networkConditions.setOffline(false);networkConditions.setLatency(java.time.Duration.ofMillis(20));// 20 ms of latencynetworkConditions.setDownloadThroughput(2000*1024/8);// 2000 kbpsnetworkConditions.setUploadThroughput(2000*1024/8);// 2000 kbps((ChromeDriver)driver).setNetworkConditions(networkConditions);
network_conditions={"offline":False,"latency":20,# 20 ms of latency"download_throughput":2000*1024/8,# 2000 kbps"upload_throughput":2000*1024/8,# 2000 kbps}driver.set_network_conditions(**network_conditions)
ChromiumNetworkConditionsnetworkConditions=newChromiumNetworkConditions();networkConditions.setOffline(false);networkConditions.setLatency(java.time.Duration.ofMillis(20));// 20 ms of latencynetworkConditions.setDownloadThroughput(2000*1024/8);// 2000 kbpsnetworkConditions.setUploadThroughput(2000*1024/8);// 2000 kbps
network_conditions={"offline":False,"latency":20,# 20 ms of latency"download_throughput":2000*1024/8,# 2000 kbps"upload_throughput":2000*1024/8,# 2000 kbps}driver.set_network_conditions(**network_conditions)
const{Builder}=require("selenium-webdriver");constfirefox=require('selenium-webdriver/firefox');constoptions=newfirefox.Options();letprofile='/path to custom profile';options.setProfile(profile);constdriver=newBuilder().forBrowser('firefox').setFirefoxOptions(options).build();
Note: Whether you create an empty FirefoxProfile or point it to the directory of your own profile, Selenium
will create a temporary directory to store either the data of the new profile or a copy of your existing one. Every
time you run your program, a different temporary directory will be created. These directories are not cleaned up
explicitly by Selenium, they should eventually get removed by the operating system. However, if you want to remove
the copy manually (e.g. if your profile is large in size), the path of the copy is exposed by the FirefoxProfile
object. Check the language specific implementation to see how to retrieve that location.
If you want to use an existing Firefox profile, you can pass in the path to that profile. Please refer to the official
Firefox documentation
for instructions on how to find the directory of your profile.
Note: As of Firefox 138, geckodriver needs to be started with the argument --allow-system-access to switch the context to CHROME.
2.3.4 - IE特有の機能
これらは、Microsoft Internet Explorerブラウザに特有の機能と機能です。
As of June 2022, Selenium officially no longer supports standalone Internet Explorer.
The Internet Explorer driver still supports running Microsoft Edge in “IE Compatibility Mode.”
Special considerations
The IE Driver is the only driver maintained by the Selenium Project directly.
While binaries for both the 32-bit and 64-bit
versions of Internet Explorer are available, there are some
known limitations
with the 64-bit driver. As such it is recommended to use the 32-bit driver.
Additional information about using Internet Explorer can be found on the
IE Driver Server page
Options
Starting a Microsoft Edge browser in Internet Explorer Compatibility mode with basic defined options looks like this:
If IE is not present on the system (default in Windows 11), you do not need to
use the two parameters above. IE Driver will use Edge and will automatically locate it.
If IE and Edge are both present on the system, you only need to set attaching to Edge,
IE Driver will automatically locate Edge on your system.
<p><ahref=/documentation/about/contributing/#moving-examples><spanclass="selenium-badge-code"data-bs-toggle="tooltip"data-bs-placement="right"title="One or more of these examples need to be implemented in the examples directory; click for details in the contribution guide">MoveCode</span></a></p>valoptions=InternetExplorerOptions()valdriver=InternetExplorerDriver(options)
Here are a few common use cases with different capabilities:
Service settings common to all browsers are described on the Service page.
Log output
Getting driver logs can be helpful for debugging various issues. The Service class lets you
direct where the logs will go. Logging output is ignored unless the user directs it somewhere.
File output
To change the logging output to save to a specific file:
Note: Java also allows setting console output by System Property; Property key: InternetExplorerDriverService.IE_DRIVER_LOGFILE_PROPERTY Property value: DriverService.LOG_STDOUT or DriverService.LOG_STDERR
Note: Java also allows setting log level by System Property: Property key: InternetExplorerDriverService.IE_DRIVER_LOGLEVEL_PROPERTY Property value: String representation of InternetExplorerDriverLogLevel.DEBUG.toString() enum
Unlike Chromium and Firefox drivers, the safaridriver is installed with the Operating System.
To enable automation on Safari, run the following command from the terminal:
safaridriver --enable
Options
Capabilities common to all browsers are described on the Options page.
Those looking to automate Safari on iOS should look to the Appium project.
Service
Service settings common to all browsers are described on the Service page.
Logging
Unlike other browsers, Safari doesn’t let you choose where logs are output, or change levels. The one option
available is to turn logs off or on. If logs are toggled on, they can be found at:~/Library/Logs/com.apple.WebDriver/.
Note: Java also allows setting console output by System Property; Property key: SafariDriverService.SAFARI_DRIVER_LOGGING Property value: "true" or "false"
Perhaps the most common challenge for browser automation is ensuring
that the web application is in a state to execute a particular
Selenium command as desired. The processes often end up in
a race condition where sometimes the browser gets into the right
state first (things work as intended) and sometimes the Selenium code
executes first (things do not work as intended). This is one of the
primary causes of flaky tests.
All navigation commands wait for a specific readyState value
based on the page load strategy (the
default value to wait for is "complete") before the driver returns control to the code.
The readyState only concerns itself with loading assets defined in the HTML,
but loaded JavaScript assets often result in changes to the site,
and elements that need to be interacted with may not yet be on the page
when the code is ready to execute the next Selenium command.
Similarly, in a lot of single page applications, elements get dynamically
added to a page or change visibility based on a click.
An element must be both present and
displayed on the page
in order for Selenium to interact with it.
Take this page for example: https://www.selenium.dev/selenium/web/dynamic.html
When the “Add a box!” button is clicked, a “div” element that does not exist is created.
When the “Reveal a new input” button is clicked, a hidden text field element is displayed.
In both cases the transition takes a couple seconds.
If the Selenium code is to click one of these buttons and interact with the resulting element,
it will do so before that element is ready and fail.
The first solution many people turn to is adding a sleep statement to
pause the code execution for a set period of time.
Because the code can’t know exactly how long it needs to wait, this
can fail when it doesn’t sleep long enough. Alternately, if the value is set too high
and a sleep statement is added in every place it is needed, the duration of
the session can become prohibitive.
Selenium provides two different mechanisms for synchronization that are better.
Implicit waits
Selenium has a built-in way to automatically wait for elements called an implicit wait.
An implicit wait value can be set either with the timeouts
capability in the browser options, or with a driver method (as shown below).
This is a global setting that applies to every element location call for the entire session.
The default value is 0, which means that if the element is not found, it will
immediately return an error. If an implicit wait is set, the driver will wait for the
duration of the provided value before returning the error. Note that as soon as the
element is located, the driver will return the element reference and the code will continue executing,
so a larger implicit wait value won’t necessarily increase the duration of the session.
Warning:
Do not mix implicit and explicit waits.
Doing so can cause unpredictable wait times.
For example, setting an implicit wait of 10 seconds
and an explicit wait of 15 seconds
could cause a timeout to occur after 20 seconds.
Solving our example with an implicit wait looks like this:
Explicit waits are loops added to the code that poll the application
for a specific condition to evaluate as true before it exits the loop and
continues to the next command in the code. If the condition is not met before a designated timeout value,
the code will give a timeout error. Since there are many ways for the application not to be in the desired state,
explicit waits are a great choice to specify the exact condition to wait for
in each place it is needed.
Another nice feature is that, by default, the Selenium Wait class automatically waits for the designated element to exist.
This example shows the condition being waited for as a lambda. Java also supports
Expected Conditions
The Wait class can be instantiated with various parameters that will change how the conditions are evaluated.
This can include:
Changing how often the code is evaluated (polling interval)
Specifying which exceptions should be handled automatically
Changing the total timeout length
Customizing the timeout message
For instance, if the element not interactable error is retried by default, then we can
add an action on a method inside the code getting executed (we just need to
make sure that the code returns true when it is successful):
The easiest way to customize Waits in Java is to use the FluentWait class:
Because Selenium cannot interact with the file upload dialog, it provides a way
to upload files without opening the dialog. If the element is an input element with type file,
you can use the send keys method to send the full path to the file that will be uploaded.
To work on a web element using Selenium, we need to first locate it on the web page.
Selenium provides us above mentioned ways, using which we can locate element on the
page. To understand and create locator we will use the following HTML snippet.
<html><body><style>.information{background-color:white;color:black;padding:10px;}</style><h2>Contact Selenium</h2><form><inputtype="radio"name="gender"value="m"/>Male <inputtype="radio"name="gender"value="f"/>Female <br><br><labelfor="fname">First name:</label><br><inputclass="information"type="text"id="fname"name="fname"value="Jane"><br><br><labelfor="lname">Last name:</label><br><inputclass="information"type="text"id="lname"name="lname"value="Doe"><br><br><labelfor="newsletter">Newsletter:</label><inputtype="checkbox"name="newsletter"value="1"/><br><br><inputtype="submit"value="Submit"></form><p>To know more about Selenium, visit the official page
<ahref ="www.selenium.dev">Selenium Official Page</a></p></body></html>
class name
The HTML page web element can have attribute class. We can see an example in the
above shown HTML snippet. We can identify these elements using the class name locator
available in Selenium.
CSS is the language used to style HTML pages. We can use css selector locator strategy
to identify the element on the page. If the element has an id, we create the locator
as css = #id. Otherwise the format we follow is css =[attribute=value] .
Let us see an example from above HTML snippet. We will create locator for First Name
textbox, using css.
We can use the ID attribute available with element in a web page to locate it.
Generally the ID property should be unique for a element on the web page.
We will identify the Last Name field using it.
We can use the NAME attribute available with element in a web page to locate it.
Generally the NAME property should be unique for a element on the web page.
We will identify the Newsletter checkbox using it.
If the element we want to locate is a link, we can use the link text locator
to identify it on the web page. The link text is the text displayed of the link.
In the HTML snippet shared, we have a link available, lets see how will we locate it.
WebDriverdriver=newChromeDriver();driver.findElement(By.linkText("Selenium Official Page"));
driver=webdriver.Chrome()driver.get("https://www.selenium.dev/selenium/web/locators_tests/locators.html")element=driver.find_element(By.LINK_TEXT,"Selenium Official Page")
letdriver=awaitnewBuilder().forBrowser('chrome').build();constloc=awaitdriver.findElement(By.linkText('Selenium Official Page'));
valdriver=ChromeDriver()valloc:WebElement=driver.findElement(By.linkText("Selenium Official Page"))
partial link text
If the element we want to locate is a link, we can use the partial link text locator
to identify it on the web page. The link text is the text displayed of the link.
We can pass partial text as value.
In the HTML snippet shared, we have a link available, lets see how will we locate it.
We can use the HTML TAG itself as a locator to identify the web element on the page.
From the above HTML snippet shared, lets identify the link, using its html tag “a”.
A HTML document can be considered as a XML document, and then we can use xpath
which will be the path traversed to reach the element of interest to locate the element.
The XPath could be absolute xpath, which is created from the root of the document.
Example - /html/form/input[1]. This will return the male radio button.
Or the xpath could be relative. Example- //input[@name=‘fname’]. This will return the
first name text box. Let us create locator for female radio button using xpath.
The FindElement makes using locators a breeze! For most languages,
all you need to do is utilize webdriver.common.by.By, however in
others it’s as simple as setting a parameter in the FindElement function
The ByChained class enables you to chain two By locators together. For example, instead of having to
locate a parent element, and then a child element of that parent, you can instead combine those two FindElement
functions into one.
The ByAll class enables you to utilize two By locators at once, finding elements that mach either of your By locators.
For example, instead of having to utilize two FindElement() functions to find the username and password input fields seperately,
you can instead find them together in one clean FindElements()
Selenium 4 introduces Relative Locators (previously
called as Friendly Locators). These locators are helpful when it is not easy to construct a locator for
the desired element, but easy to describe spatially where the element is in relation to an element that does have
an easily constructed locator.
How it works
Selenium uses the JavaScript function
getBoundingClientRect()
to determine the size and position of elements on the page, and can use this information to locate neighboring elements. find the relative elements.
Relative locator methods can take as the argument for the point of origin, either a previously located element reference,
or another locator. In these examples we’ll be using locators only, but you could swap the locator in the final method with
an element object and it will work the same.
Let us consider the below example for understanding the relative locators.
Available relative locators
Above
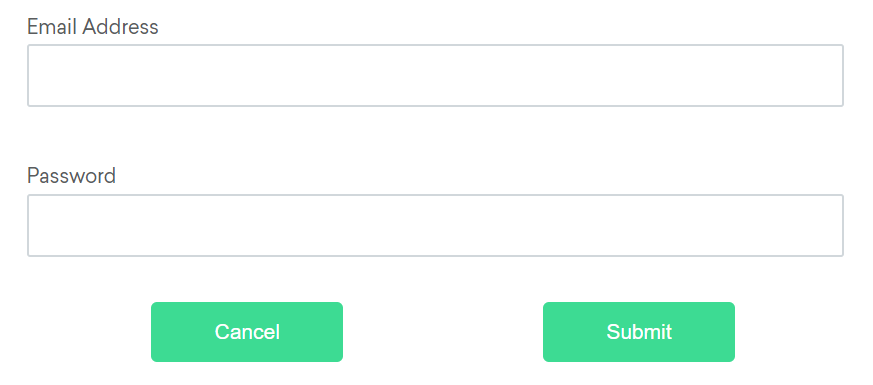
If the email text field element is not easily identifiable for some reason, but the password text field element is,
we can locate the text field element using the fact that it is an “input” element “above” the password element.
If the password text field element is not easily identifiable for some reason, but the email text field element is,
we can locate the text field element using the fact that it is an “input” element “below” the email element.
If the cancel button is not easily identifiable for some reason, but the submit button element is,
we can locate the cancel button element using the fact that it is a “button” element to the “left of” the submit element.
If the submit button is not easily identifiable for some reason, but the cancel button element is,
we can locate the submit button element using the fact that it is a “button” element “to the right of” the cancel element.
If the relative positioning is not obvious, or it varies based on window size, you can use the near method to
identify an element that is at most 50px away from the provided locator.
One great use case for this is to work with a form element that doesn’t have an easily constructed locator,
but its associated input label element does.
You can also chain locators if needed. Sometimes the element is most easily identified as being both above/below one element and right/left of another.
These methods are designed to closely emulate a user’s experience, so,
unlike the Actions API, it attempts to perform two things
before attempting the specified action.
If it determines the element is outside the viewport, it
scrolls the element into view, specifically
it will align the bottom of the element with the bottom of the viewport.
It ensures the element is interactable
before taking the action. This could mean that the scrolling was unsuccessful, or that the
element is not otherwise displayed. Determining if an element is displayed on a page was too difficult to
define directly in the webdriver specification,
so Selenium sends an execute command with a JavaScript atom that checks for things that would keep
the element from being displayed. If it determines an element is not in the viewport, not displayed, not
keyboard-interactable, or not
pointer-interactable,
it returns an element not interactable error.
driver.get("https://www.selenium.dev/selenium/web/inputs.html");// Click on the element WebElementcheckInput=driver.findElement(By.name("checkbox_input"));checkInput.click();
# Navigate to URLdriver.get("https://www.selenium.dev/selenium/web/inputs.html")# Click on the checkboxcheck_input=driver.find_element(By.NAME,"checkbox_input")check_input.click()
// Navigate to Urldriver.Navigate().GoToUrl("https://www.selenium.dev/selenium/web/inputs.html");// Click on the element IWebElementcheckInput=driver.FindElement(By.Name("checkbox_input"));checkInput.Click();
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")// Click the element
driver.findElement(By.name("color_input")).click();
Send keys
The element send keys command
types the provided keys into an editable element.
Typically, this means an element is an input element of a form with a text type or an element
with a content-editable attribute. If it is not editable,
an invalid element state error is returned.
Here is the list of
possible keystrokes that WebDriver Supports.
// Clear field to empty it from any previous dataWebElementemailInput=driver.findElement(By.name("email_input"));emailInput.clear();//Enter TextStringemail="admin@localhost.dev";emailInput.sendKeys(email);
# Handle the email input fieldemail_input=driver.find_element(By.NAME,"email_input")email_input.clear()# Clear fieldemail="admin@localhost.dev"email_input.send_keys(email)# Enter text
//SendKeys// Clear field to empty it from any previous dataIWebElementemailInput=driver.FindElement(By.Name("email_input"));emailInput.Clear();//Enter TextStringemail="admin@localhost.dev";emailInput.SendKeys(email);
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//Clear field to empty it from any previous data
driver.findElement(By.name("email_input")).clear()// Enter text
driver.findElement(By.name("email_input")).sendKeys("admin@localhost.dev")
Clear
The element clear command resets the content of an element.
This requires an element to be editable,
and resettable. Typically,
this means an element is an input element of a form with a text type or an element
with acontent-editable attribute. If these conditions are not met,
an invalid element state error is returned.
//Clear Element// Clear field to empty it from any previous dataemailInput.clear();
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//Clear field to empty it from any previous data
driver.findElement(By.name("email_input")).clear()
Submit
In Selenium 4 this is no longer implemented with a separate endpoint and functions by executing a script. As
such, it is recommended not to use this method and to click the applicable form submission button instead.
<olid="vegetables"><liclass="potatoes">…
<liclass="onions">…
<liclass="tomatoes"><span>Tomato is a Vegetable</span>…
</ol><ulid="fruits"><liclass="bananas">…
<liclass="apples">…
<liclass="tomatoes"><span>Tomato is a Fruit</span>…
</ul>
The Shadow DOM is an encapsulated DOM tree hidden inside an element.
With the release of v96 in Chromium Browsers, Selenium can now allow you to access this tree
with easy-to-use shadow root methods. NOTE: These methods require Selenium 4.0 or greater.
fromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriver=webdriver.Firefox()# Navigate to Urldriver.get("https://www.example.com")# Get all the elements available with tag name 'p'elements=driver.find_elements(By.TAG_NAME,'p')foreinelements:print(e.text)
usingOpenQA.Selenium;usingOpenQA.Selenium.Firefox;usingSystem.Collections.Generic;namespaceFindElementsExample{classFindElementsExample{publicstaticvoidMain(string[]args){IWebDriverdriver=newFirefoxDriver();try{// Navigate to Urldriver.Navigate().GoToUrl("https://example.com");// Get all the elements available with tag name 'p'IList<IWebElement>elements=driver.FindElements(By.TagName("p"));foreach(IWebElementeinelements){System.Console.WriteLine(e.Text);}}finally{driver.Quit();}}}}
const{Builder,By}=require('selenium-webdriver');(asyncfunctionexample(){letdriver=awaitnewBuilder().forBrowser('firefox').build();try{// Navigate to Url
awaitdriver.get('https://www.example.com');// Get all the elements available with tag 'p'
letelements=awaitdriver.findElements(By.css('p'));for(leteofelements){console.log(awaite.getText());}}finally{awaitdriver.quit();}})();
importorg.openqa.selenium.Byimportorg.openqa.selenium.firefox.FirefoxDriverfunmain(){valdriver=FirefoxDriver()try{driver.get("https://example.com")// Get all the elements available with tag name 'p'
valelements=driver.findElements(By.tagName("p"))for(elementinelements){println("Paragraph text:"+element.text)}}finally{driver.quit()}}
importorg.openqa.selenium.By;importorg.openqa.selenium.WebDriver;importorg.openqa.selenium.WebElement;importorg.openqa.selenium.chrome.ChromeDriver;importjava.util.List;publicclassfindElementsFromElement{publicstaticvoidmain(String[]args){WebDriverdriver=newChromeDriver();try{driver.get("https://example.com");// Get element with tag name 'div'WebElementelement=driver.findElement(By.tagName("div"));// Get all the elements available with tag name 'p'List<WebElement>elements=element.findElements(By.tagName("p"));for(WebElemente:elements){System.out.println(e.getText());}}finally{driver.quit();}}}
fromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriver=webdriver.Chrome()driver.get("https://www.example.com")##get elements from parent element using TAG_NAME# Get element with tag name 'div'element=driver.find_element(By.TAG_NAME,'div')# Get all the elements available with tag name 'p'elements=element.find_elements(By.TAG_NAME,'p')foreinelements:print(e.text)##get elements from parent element using XPATH##NOTE: in order to utilize XPATH from current element, you must add "." to beginning of path# Get first element of tag 'ul'element=driver.find_element(By.XPATH,'//ul')# get children of tag 'ul' with tag 'li'elements=driver.find_elements(By.XPATH,'.//li')foreinelements:print(e.text)
usingOpenQA.Selenium;usingOpenQA.Selenium.Chrome;usingSystem.Collections.Generic;namespaceFindElementsFromElement{classFindElementsFromElement{publicstaticvoidMain(string[]args){IWebDriverdriver=newChromeDriver();try{driver.Navigate().GoToUrl("https://example.com");// Get element with tag name 'div'IWebElementelement=driver.FindElement(By.TagName("div"));// Get all the elements available with tag name 'p'IList<IWebElement>elements=element.FindElements(By.TagName("p"));foreach(IWebElementeinelements){System.Console.WriteLine(e.Text);}}finally{driver.Quit();}}}}
const{Builder,By}=require('selenium-webdriver');(asyncfunctionexample(){letdriver=newBuilder().forBrowser('chrome').build();awaitdriver.get('https://www.example.com');// Get element with tag name 'div'
letelement=driver.findElement(By.css("div"));// Get all the elements available with tag name 'p'
letelements=awaitelement.findElements(By.css("p"));for(leteofelements){console.log(awaite.getText());}})();
importorg.openqa.selenium.Byimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")// Get element with tag name 'div'
valelement=driver.findElement(By.tagName("div"))// Get all the elements available with tag name 'p'
valelements=element.findElements(By.tagName("p"))for(einelements){println(e.text)}}finally{driver.quit()}}
importorg.openqa.selenium.*;importorg.openqa.selenium.chrome.ChromeDriver;publicclassactiveElementTest{publicstaticvoidmain(String[]args){WebDriverdriver=newChromeDriver();try{driver.get("http://www.google.com");driver.findElement(By.cssSelector("[name='q']")).sendKeys("webElement");// Get attribute of current active elementStringattr=driver.switchTo().activeElement().getAttribute("title");System.out.println(attr);}finally{driver.quit();}}}
fromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriver=webdriver.Chrome()driver.get("https://www.google.com")driver.find_element(By.CSS_SELECTOR,'[name="q"]').send_keys("webElement")# Get attribute of current active elementattr=driver.switch_to.active_element.get_attribute("title")print(attr)
usingOpenQA.Selenium;usingOpenQA.Selenium.Chrome;namespaceActiveElement{classActiveElement{publicstaticvoidMain(string[]args){IWebDriverdriver=newChromeDriver();try{// Navigate to Urldriver.Navigate().GoToUrl("https://www.google.com");driver.FindElement(By.CssSelector("[name='q']")).SendKeys("webElement");// Get attribute of current active elementstringattr=driver.SwitchTo().ActiveElement().GetAttribute("title");System.Console.WriteLine(attr);}finally{driver.Quit();}}}}
const{Builder,By}=require('selenium-webdriver');(asyncfunctionexample(){letdriver=awaitnewBuilder().forBrowser('chrome').build();awaitdriver.get('https://www.google.com');awaitdriver.findElement(By.css('[name="q"]')).sendKeys("webElement");// Get attribute of current active element
letattr=awaitdriver.switchTo().activeElement().getAttribute("title");console.log(`${attr}`)})();
importorg.openqa.selenium.Byimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://www.google.com")driver.findElement(By.cssSelector("[name='q']")).sendKeys("webElement")// Get attribute of current active element
valattr=driver.switchTo().activeElement().getAttribute("title")print(attr)}finally{driver.quit()}}
2.5.5 - Web要素に関する情報
要素について学ぶことができること。
特定の要素についてクエリできる詳細情報がいくつかあります。
表示されているかどうか
This method is used to check if the connected Element is
displayed on a webpage. Returns a Boolean value,
True if the connected element is displayed in the current
browsing context else returns false.
This functionality is mentioned in, but not defined by
the w3c specification due to the
impossibility of covering all potential conditions.
As such, Selenium cannot expect drivers to implement
this functionality directly, and now relies on
executing a large JavaScript function directly.
This function makes many approximations about an element’s
nature and relationship in the tree to return a value.
driver.get("https://www.selenium.dev/selenium/web/inputs.html");// isDisplayed // Get boolean value for is element displaybooleanisEmailVisible=driver.findElement(By.name("email_input")).isDisplayed();
// Navigate to Urldriver.Url="https://www.selenium.dev/selenium/web/inputs.html";// isDisplayed // Get boolean value for is element displayboolisEmailVisible=driver.FindElement(By.Name("email_input")).Displayed;
//navigates to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//returns true if element is displayed else returns false
valflag=driver.findElement(By.name("email_input")).isDisplayed()
//navigates to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//returns true if element is enabled else returns false
valattr=driver.findElement(By.name("button_input")).isEnabled()
// isSelected// returns true if element is checked else returns falsebooleanisSelectedCheck=driver.findElement(By.name("checkbox_input")).isSelected();
//navigates to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//returns true if element is checked else returns false
valattr=driver.findElement(By.name("checkbox_input")).isSelected()
//navigates to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//returns TagName of the element
valattr=driver.findElement(By.name("email_input")).getTagName()
要素矩形を取得
参照される要素の寸法と座標を取得するために使います。
取得データのbodyには、次の詳細が含まれます。
要素の左上隅からのx軸の位置
要素の左上隅からのy軸の位置
要素の高さ
要素の幅
// GetRect// Returns height, width, x and y coordinates referenced elementRectangleres=driver.findElement(By.name("range_input")).getRect();
// Navigate to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")// Returns height, width, x and y coordinates referenced element
valres=driver.findElement(By.name("range_input")).rect// Rectangle class provides getX,getY, getWidth, getHeight methods
println(res.getX())
要素のCSSの値を取得
現在のブラウジングコンテキスト内の要素の指定された計算したスタイル属性の値を取得します。
// Retrieves the computed style property 'font-size' of fieldStringcssValue=driver.findElement(By.name("color_input")).getCssValue("font-size");
awaitdriver.get('https://www.selenium.dev/selenium/web/colorPage.html');// Returns background color of the element
letvalue=awaitdriver.findElement(By.id('namedColor')).getCssValue('background-color');
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/colorPage.html")// Retrieves the computed style property 'color' of linktext
valcssValue=driver.findElement(By.id("namedColor")).getCssValue("background-color")
要素テキストを取得
指定された要素のレンダリングされたテキストを取得します。
// GetText// Retrieves the text of the elementStringtext=driver.findElement(By.tagName("h1")).getText();
awaitdriver.get('https://www.selenium.dev/selenium/web/linked_image.html');// Returns text of the element
lettext=awaitdriver.findElement(By.id('justanotherLink')).getText();
// Navigate to URL
driver.get("https://www.selenium.dev/selenium/web/linked_image.html")// retrieves the text of the element
valtext=driver.findElement(By.id("justanotherlink")).getText()
Fetching Attributes or Properties
Fetches the run time value associated with a
DOM attribute. It returns the data associated
with the DOM attribute or property of the element.
// FetchAttributes// identify the email text boxWebElementemailTxt=driver.findElement(By.name(("email_input")));// fetch the value property associated with the textboxStringvalueInfo=emailTxt.getAttribute("value");
// FetchAttributes// identify the email text boxIWebElementemailTxt=driver.FindElement(By.Name("email_input"));// fetch the value property associated with the textboxstringvalueInfo=emailTxt.GetAttribute("value");
// identify the email text box
constemailElement=awaitdriver.findElement(By.xpath('//input[@name="email_input"]'));//fetch the attribute "name" associated with the textbox
constnameAttribute=awaitemailElement.getAttribute("name");
// Navigate to URL
driver.get("https://www.selenium.dev/selenium/web/inputs.html")//fetch the value property associated with the textbox
valattr=driver.findElement(By.name("email_input")).getAttribute("value")
wait.until(ExpectedConditions.alertIsPresent());Alertalert=driver.switchTo().alert();//Store the alert text in a variable and verify itStringtext=alert.getText();assertEquals(text,"Sample Alert");//PresstheOKbutton
element=driver.find_element(By.LINK_TEXT,"See an example alert")element.click()wait=WebDriverWait(driver,timeout=2)alert=wait.until(lambdad:d.switch_to.alert)text=alert.textalert.accept()
//Click the link to activate the alertdriver.FindElement(By.LinkText("See an example alert")).Click();//Wait for the alert to be displayed and store it in a variableIAlertalert=wait.Until(ExpectedConditions.AlertIsPresent());//Store the alert text in a variablestringtext=alert.Text;//Press the OK buttonalert.Accept();
# Store the alert reference in a variablealert=driver.switch_to.alert# Get the text of the alertalert.text# Press on Cancel buttonalert.dismiss
//Click the link to activate the alert
driver.findElement(By.linkText("See an example alert")).click()//Wait for the alert to be displayed and store it in a variable
valalert=wait.until(ExpectedConditions.alertIsPresent())//Store the alert text in a variable
valtext=alert.getText()//Press the OK button
alert.accept()
alert=driver.switchTo().alert();//Store the alert text in a variable and verify ittext=alert.getText();assertEquals(text,"Are you sure?");//PresstheCancelbutton
element=driver.find_element(By.LINK_TEXT,"See a sample confirm")driver.execute_script("arguments[0].click();",element)wait=WebDriverWait(driver,timeout=2)alert=wait.until(lambdad:d.switch_to.alert)text=alert.textalert.dismiss()
//Click the link to activate the alertdriver.FindElement(By.LinkText("See a sample confirm")).Click();//Wait for the alert to be displayedwait.Until(ExpectedConditions.AlertIsPresent());//Store the alert in a variableIAlertalert=driver.SwitchTo().Alert();//Store the alert in a variable for reusestringtext=alert.Text;//Press the Cancel buttonalert.Dismiss();
# Store the alert reference in a variablealert=driver.switch_to.alert# Get the text of the alertalert.text# Press on Cancel buttonalert.dismiss
//Click the link to activate the alert
driver.findElement(By.linkText("See a sample confirm")).click()//Wait for the alert to be displayed
wait.until(ExpectedConditions.alertIsPresent())//Store the alert in a variable
valalert=driver.switchTo().alert()//Store the alert in a variable for reuse
valtext=alert.text//Press the Cancel button
alert.dismiss()
wait.until(ExpectedConditions.alertIsPresent());alert=driver.switchTo().alert();//Store the alert text in a variable and verify ittext=alert.getText();assertEquals(text,"What is your name?");//Type your messagealert.sendKeys("Selenium");//PresstheOKbutton
element=driver.find_element(By.LINK_TEXT,"See a sample prompt")driver.execute_script("arguments[0].click();",element)wait=WebDriverWait(driver,timeout=2)alert=wait.until(lambdad:d.switch_to.alert)alert.send_keys("Selenium")text=alert.textalert.accept()
//Click the link to activate the alertdriver.FindElement(By.LinkText("See a sample prompt")).Click();//Wait for the alert to be displayed and store it in a variableIAlertalert=wait.Until(ExpectedConditions.AlertIsPresent());//Type your messagealert.SendKeys("Selenium");//Press the OK buttonalert.Accept();
# Store the alert reference in a variablealert=driver.switch_to.alert# Type a messagealert.send_keys('selenium')# Press on Ok buttonalert.accept
//Click the link to activate the alert
driver.findElement(By.linkText("See a sample prompt")).click()//Wait for the alert to be displayed and store it in a variable
valalert=wait.until(ExpectedConditions.alertIsPresent())//Type your message
alert.sendKeys("Selenium")//Press the OK button
alert.accept()
driver.get("https://www.selenium.dev/selenium/web/blank.html");// Add cookie into current browser contextdriver.manage().addCookie(newCookie("key","value"));
driver=webdriver.Chrome()driver.get("http://www.example.com")# Adds the cookie into current browser contextdriver.add_cookie({"name":"key","value":"value"})
driver.Url="https://www.selenium.dev/selenium/web/blank.html";// Add cookie into current browser contextdriver.Manage().Cookies.AddCookie(newCookie("key","value"));
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'# Adds the cookie into current browser contextdriver.manage.add_cookie(name:"key",value:"value")ensuredriver.quitend
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")// Adds the cookie into current browser context
driver.manage().addCookie(Cookie("key","value"))}finally{driver.quit()}}
driver.get("https://www.selenium.dev/selenium/web/blank.html");// Add cookie into current browser contextdriver.manage().addCookie(newCookie("foo","bar"));// Get cookie details with named cookie 'foo'Cookiecookie=driver.manage().getCookieNamed("foo");
driver=webdriver.Chrome()driver.get("http://www.example.com")# Adds the cookie into current browser contextdriver.add_cookie({"name":"foo","value":"bar"})# Get cookie details with named cookie 'foo'print(driver.get_cookie("foo"))
driver.Url="https://www.selenium.dev/selenium/web/blank.html";// Add cookie into current browser contextdriver.Manage().Cookies.AddCookie(newCookie("foo","bar"));// Get cookie details with named cookie 'foo'Cookiecookie=driver.Manage().Cookies.GetCookieNamed("foo");
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'driver.manage.add_cookie(name:"foo",value:"bar")# Get cookie details with named cookie 'foo'putsdriver.manage.cookie_named('foo')ensuredriver.quitend
awaitdriver.manage().addCookie({name:'foo',value:'bar'});// Get cookie details with named cookie 'foo'
awaitdriver.manage().getCookie('foo').then(function(cookie){
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")driver.manage().addCookie(Cookie("foo","bar"))// Get cookie details with named cookie 'foo'
valcookie=driver.manage().getCookieNamed("foo")println(cookie)}finally{driver.quit()}}
driver.get("https://www.selenium.dev/selenium/web/blank.html");// Add cookies into current browser contextdriver.manage().addCookie(newCookie("test1","cookie1"));driver.manage().addCookie(newCookie("test2","cookie2"));// Get cookiesSet<Cookie>cookies=driver.manage().getCookies();for(Cookiecookie:cookies){if(cookie.getName().equals("test1")){Assertions.assertEquals(cookie.getValue(),"cookie1");}if(cookie.getName().equals("test2")){Assertions.assertEquals(cookie.getValue(),"cookie2");}}
driver=webdriver.Chrome()driver.get("http://www.example.com")driver.add_cookie({"name":"test1","value":"cookie1"})driver.add_cookie({"name":"test2","value":"cookie2"})# Get all available cookiesprint(driver.get_cookies())
driver.Url="https://www.selenium.dev/selenium/web/blank.html";// Add cookies into current browser contextdriver.Manage().Cookies.AddCookie(newCookie("test1","cookie1"));driver.Manage().Cookies.AddCookie(newCookie("test2","cookie2"));// Get cookiesvarcookies=driver.Manage().Cookies.AllCookies;foreach(varcookieincookies){if(cookie.Name.Equals("test1")){Assert.AreEqual("cookie1",cookie.Value);}if(cookie.Name.Equals("test2")){Assert.AreEqual("cookie2",cookie.Value);}}
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'driver.manage.add_cookie(name:"test1",value:"cookie1")driver.manage.add_cookie(name:"test2",value:"cookie2")# Get all available cookiesputsdriver.manage.all_cookiesensuredriver.quitend
// Get all Available cookies
awaitdriver.manage().getCookies().then(function(cookies){
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")driver.manage().addCookie(Cookie("test1","cookie1"))driver.manage().addCookie(Cookie("test2","cookie2"))// Get All available cookies
valcookies=driver.manage().cookiesprintln(cookies)}finally{driver.quit()}}
driver=webdriver.Chrome()driver.get("http://www.example.com")driver.add_cookie({"name":"test1","value":"cookie1"})driver.add_cookie({"name":"test2","value":"cookie2"})# Delete cookie with name 'test1'driver.delete_cookie("test1")
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'driver.manage.add_cookie(name:"test1",value:"cookie1")driver.manage.add_cookie(name:"test2",value:"cookie2")# delete a cookie with name 'test1'driver.manage.delete_cookie('test1')ensuredriver.quitend
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")driver.manage().addCookie(Cookie("test1","cookie1"))valcookie1=Cookie("test2","cookie2")driver.manage().addCookie(cookie1)// delete a cookie with name 'test1'
driver.manage().deleteCookieNamed("test1")// delete cookie by passing cookie object of current browsing context.
driver.manage().deleteCookie(cookie1)}finally{driver.quit()}}
全てのクッキーの削除
現在のブラウジングコンテキストの全てのCookieを削除します。
driver.get("https://www.selenium.dev/selenium/web/blank.html");// Add cookies into current browser contextdriver.manage().addCookie(newCookie("test1","cookie1"));driver.manage().addCookie(newCookie("test2","cookie2"));// Delete All cookiesdriver.manage().deleteAllCookies();
driver=webdriver.Chrome()driver.get("http://www.example.com")driver.add_cookie({"name":"test1","value":"cookie1"})driver.add_cookie({"name":"test2","value":"cookie2"})# Delete all cookiesdriver.delete_all_cookies()
driver.Url="https://www.selenium.dev/selenium/web/blank.html";// Add cookies into current browser contextdriver.Manage().Cookies.AddCookie(newCookie("test1","cookie1"));driver.Manage().Cookies.AddCookie(newCookie("test2","cookie2"));// Delete All cookiesdriver.Manage().Cookies.DeleteAllCookies();
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'driver.manage.add_cookie(name:"test1",value:"cookie1")driver.manage.add_cookie(name:"test2",value:"cookie2")# deletes all cookiesdriver.manage.delete_all_cookiesensuredriver.quitend
importorg.openqa.selenium.Cookieimportorg.openqa.selenium.chrome.ChromeDriverfunmain(){valdriver=ChromeDriver()try{driver.get("https://example.com")driver.manage().addCookie(Cookie("test1","cookie1"))driver.manage().addCookie(Cookie("test2","cookie2"))// deletes all cookies
driver.manage().deleteAllCookies()}finally{driver.quit()}}
driver=webdriver.Chrome()driver.get("http://www.example.com")# Adds the cookie into current browser context with sameSite 'Strict' (or) 'Lax'driver.add_cookie({"name":"foo","value":"value","sameSite":"Strict"})driver.add_cookie({"name":"foo1","value":"value","sameSite":"Lax"})cookie1=driver.get_cookie("foo")cookie2=driver.get_cookie("foo1")print(cookie1)print(cookie2)
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://www.example.com'# Adds the cookie into current browser context with sameSite 'Strict' (or) 'Lax'driver.manage.add_cookie(name:"foo",value:"bar",same_site:"Strict")driver.manage.add_cookie(name:"foo1",value:"bar",same_site:"Lax")putsdriver.manage.cookie_named('foo')putsdriver.manage.cookie_named('foo1')ensuredriver.quitend
awaitdriver.get('https://www.selenium.dev/selenium/web/blank.html');// set a cookie on the current domain with sameSite 'Strict' (or) 'Lax'
//switch To IFrame using Web ElementWebElementiframe=driver.findElement(By.id("iframe1"));//Switch to the framedriver.switchTo().frame(iframe);assertEquals(true,driver.getPageSource().contains("We Leave From Here"));//Now we can type text into email fieldWebElementemailE=driver.findElement(By.id("email"));emailE.sendKeys("admin@selenium.dev");emailE.clear();
# --- Switch to iframe using WebElement ---iframe=driver.find_element(By.ID,"iframe1")driver.switch_to.frame(iframe)assert"We Leave From Here"indriver.page_sourceemail_element=driver.find_element(By.ID,"email")email_element.send_keys("admin@selenium.dev")email_element.clear()driver.switch_to.default_content()
//switch To IFrame using Web ElementIWebElementiframe=driver.FindElement(By.Id("iframe1"));//Switch to the framedriver.SwitchTo().Frame(iframe);Assert.AreEqual(true,driver.PageSource.Contains("We Leave From Here"));//Now we can type text into email fieldIWebElementemailE=driver.FindElement(By.Id("email"));emailE.SendKeys("admin@selenium.dev");emailE.Clear();
# Store iframe web elementiframe=driver.find_element(:css,'#modal > iframe')# Switch to the framedriver.switch_to.frameiframe# Now, Click on the buttondriver.find_element(:tag_name,'button').click
// Store the web element
constiframe=driver.findElement(By.css('#modal > iframe'));// Switch to the frame
awaitdriver.switchTo().frame(iframe);// Now we can click the button
awaitdriver.findElement(By.css('button')).click();
//Store the web element
valiframe=driver.findElement(By.cssSelector("#modal>iframe"))//Switch to the frame
driver.switchTo().frame(iframe)//Now we can click the button
driver.findElement(By.tagName("button")).click()
//switch To IFrame using name or iddriver.findElement(By.name("iframe1-name"));//Switch to the framedriver.switchTo().frame(iframe);assertEquals(true,driver.getPageSource().contains("We Leave From Here"));WebElementemail=driver.findElement(By.id("email"));//Now we can type text into email fieldemail.sendKeys("admin@selenium.dev");email.clear();
# --- Switch to iframe using name or ID ---iframe1=driver.find_element(By.NAME,"iframe1-name")# (This line doesn't switch, just locates)driver.switch_to.frame(iframe)assert"We Leave From Here"indriver.page_sourceemail=driver.find_element(By.ID,"email")email.send_keys("admin@selenium.dev")email.clear()driver.switch_to.default_content()
//switch To IFrame using name or iddriver.FindElement(By.Name("iframe1-name"));//Switch to the framedriver.SwitchTo().Frame(iframe);Assert.AreEqual(true,driver.PageSource.Contains("We Leave From Here"));IWebElementemail=driver.FindElement(By.Id("email"));//Now we can type text into email fieldemail.SendKeys("admin@selenium.dev");email.Clear();
// Using the ID
awaitdriver.switchTo().frame('buttonframe');// Or using the name instead
awaitdriver.switchTo().frame('myframe');// Now we can click the button
awaitdriver.findElement(By.css('button')).click();
//Using the ID
driver.switchTo().frame("buttonframe")//Or using the name instead
driver.switchTo().frame("myframe")//Now we can click the button
driver.findElement(By.tagName("button")).click()
# Return to the top leveldriver.switch_to.default_content
// Return to the top level
awaitdriver.switchTo().defaultContent();
// Return to the top level
driver.switchTo().defaultContent()
2.6.5 - Print Page
Printing a webpage is a common task, whether for sharing information or maintaining archives.
Selenium simplifies this process through its PrintOptions, PrintsPage, and browsingContext
classes, which provide a flexible and intuitive interface for automating the printing of web pages.
These classes enable you to configure printing preferences, such as page layout, margins, and scaling,
ensuring that the output meets your specific requirements.
Configuring
Orientation
Using the getOrientation() and setOrientation() methods, you can get/set the page orientation — either PORTRAIT or LANDSCAPE.
publicvoidTestRange(){IWebDriverdriver=newChromeDriver();driver.Navigate().GoToUrl("https://selenium.dev");PrintOptionsprintOptions=newPrintOptions();printOptions.AddPageRangeToPrint("1-3");// add range of pagesprintOptions.AddPageToPrint(5);// add individual page}
Using the getPageSize() and setPageSize() methods, you can get/set the paper size to print — e.g. “A0”, “A6”, “Legal”, “Tabloid”, etc.
driver.get("https://www.selenium.dev/");PrintOptionsprintOptions=newPrintOptions();printOptions.setPageSize(newPageSize(27.94,21.59));// A4 size in cmdoublecurrentHeight=printOptions.getPageSize().getHeight();//usegetWidth()toretrievewidth
Using the getPageMargin() and setPageMargin() methods, you can set the margin sizes of the page you wish to print — i.e. top, bottom, left, and right margins.
Once you’ve configured your PrintOptions, you’re ready to print the page. To do this,
you can invoke the print function, which generates a PDF representation of the web page.
The resulting PDF can be saved to your local storage for further use or distribution.
Using PrintsPage(), the print command will return the PDF data in base64-encoded format, which can be decoded
and written to a file in your desired location, and using BrowsingContext() will return a String.
There may currently be multiple implementations depending on your language of choice. For example, with Java you
have the ability to print using either BrowingContext() or PrintsPage(). Both take PrintOptions() objects as a
parameter.
Note: BrowsingContext() is part of Selenium’s BiDi implementation. To enable BiDi see Enabling Bidi
// Navigate to Urldriver.get("https://www.selenium.dev/selenium/web/window_switching_tests/page_with_frame.html");//fetch handle of thisStringcurrHandle=driver.getWindowHandle();assertNotNull(currHandle);
// Navigate to Urldriver.Url="https://www.selenium.dev/selenium/web/window_switching_tests/page_with_frame.html";//fetch handle of thisStringcurrHandle=driver.CurrentWindowHandle;Assert.IsNotNull(currHandle);
//click on link to open a new windowdriver.findElement(By.linkText("Open new window")).click();//fetch handles of all windows, there will be two, [0]- default, [1] - new windowObject[]windowHandles=driver.getWindowHandles().toArray();driver.switchTo().window((String)windowHandles[1]);//assert on title of new windowStringtitle=driver.getTitle();assertEquals("Simple Page",title);
fromseleniumimportwebdriverfromselenium.webdriver.support.uiimportWebDriverWaitfromselenium.webdriver.supportimportexpected_conditionsasEC# Start the driverwithwebdriver.Firefox()asdriver:# Open URLdriver.get("https://seleniumhq.github.io")# Setup wait for laterwait=WebDriverWait(driver,10)# Store the ID of the original windoworiginal_window=driver.current_window_handle# Check we don't have other windows open alreadyassertlen(driver.window_handles)==1# Click the link which opens in a new windowdriver.find_element(By.LINK_TEXT,"new window").click()# Wait for the new window or tabwait.until(EC.number_of_windows_to_be(2))# Loop through until we find a new window handleforwindow_handleindriver.window_handles:ifwindow_handle!=original_window:driver.switch_to.window(window_handle)break# Wait for the new tab to finish loading contentwait.until(EC.title_is("SeleniumHQ Browser Automation"))
//click on link to open a new windowdriver.FindElement(By.LinkText("Open new window")).Click();//fetch handles of all windows, there will be two, [0]- default, [1] - new windowIList<string>windowHandles=newList<string>(driver.WindowHandles);driver.SwitchTo().Window(windowHandles[1]);//assert on title of new windowStringtitle=driver.Title;Assert.AreEqual("Simple Page",title);
#Store the ID of the original windoworiginal_window=driver.window_handle#Check we don't have other windows open alreadyassert(driver.window_handles.length==1,'Expected one window')#Click the link which opens in a new windowdriver.find_element(link:'new window').click#Wait for the new window or tabwait.until{driver.window_handles.length==2}#Loop through until we find a new window handledriver.window_handles.eachdo|handle|ifhandle!=original_windowdriver.switch_to.windowhandlebreakendend#Wait for the new tab to finish loading contentwait.until{driver.title=='Selenium documentation'}
//Store the ID of the original window
constoriginalWindow=awaitdriver.getWindowHandle();//Check we don't have other windows open already
assert((awaitdriver.getAllWindowHandles()).length===1);//Click the link which opens in a new window
awaitdriver.findElement(By.linkText('new window')).click();//Wait for the new window or tab
awaitdriver.wait(async()=>(awaitdriver.getAllWindowHandles()).length===2,10000);//Loop through until we find a new window handle
constwindows=awaitdriver.getAllWindowHandles();windows.forEach(asynchandle=>{if(handle!==originalWindow){awaitdriver.switchTo().window(handle);}});//Wait for the new tab to finish loading content
awaitdriver.wait(until.titleIs('Selenium documentation'),10000);
//Store the ID of the original window
valoriginalWindow=driver.getWindowHandle()//Check we don't have other windows open already
assert(driver.getWindowHandles().size()===1)//Click the link which opens in a new window
driver.findElement(By.linkText("new window")).click()//Wait for the new window or tab
wait.until(numberOfWindowsToBe(2))//Loop through until we find a new window handle
for(windowHandleindriver.getWindowHandles()){if(!originalWindow.contentEquals(windowHandle)){driver.switchTo().window(windowHandle)break}}//Wait for the new tab to finish loading content
wait.until(titleIs("Selenium documentation"))
//Opens a new tab and switches to new tabdriver.switchTo().newWindow(WindowType.TAB);assertEquals("",driver.getTitle());//Opens a new window and switches to new windowdriver.switchTo().newWindow(WindowType.WINDOW);assertEquals("",driver.getTitle());
# Opens a new tab and switches to new tabdriver.switch_to.new_window('tab')# Opens a new window and switches to new windowdriver.switch_to.new_window('window')
//Opens a new tab and switches to new tabdriver.SwitchTo().NewWindow(WindowType.Tab);Assert.AreEqual("",driver.Title);//Opens a new window and switches to new windowdriver.SwitchTo().NewWindow(WindowType.Window);Assert.AreEqual("",driver.Title);
// Opens a new tab and switches to new tab
driver.switchTo().newWindow(WindowType.TAB)// Opens a new window and switches to new window
driver.switchTo().newWindow(WindowType.WINDOW)
/**
* Example using JUnit
* https://junit.org/junit5/docs/current/api/org/junit/jupiter/api/AfterAll.html
*/@AfterAllpublicstaticvoidtearDown(){driver.quit();}
/*
Example using Visual Studio's UnitTesting
https://msdn.microsoft.com/en-us/library/microsoft.visualstudio.testtools.unittesting.aspx
*/[TestCleanup]publicvoidTearDown(){driver.Quit();}
//Access each dimension individuallyintwidth=driver.manage().window().getSize().getWidth();intheight=driver.manage().window().getSize().getHeight();//Or store the dimensions and query them laterDimensionsize=driver.manage().window().getSize();intwidth1=size.getWidth();intheight1=size.getHeight();
# Access each dimension individuallywidth=driver.get_window_size().get("width")height=driver.get_window_size().get("height")# Or store the dimensions and query them latersize=driver.get_window_size()width1=size.get("width")height1=size.get("height")
//Access each dimension individuallyintwidth=driver.Manage().Window.Size.Width;intheight=driver.Manage().Window.Size.Height;//Or store the dimensions and query them laterSystem.Drawing.Sizesize=driver.Manage().Window.Size;intwidth1=size.Width;intheight1=size.Height;
# Access each dimension individuallywidth=driver.manage.window.size.widthheight=driver.manage.window.size.height# Or store the dimensions and query them latersize=driver.manage.window.sizewidth1=size.widthheight1=size.height
//Access each dimension individually
valwidth=driver.manage().window().size.widthvalheight=driver.manage().window().size.height//Or store the dimensions and query them later
valsize=driver.manage().window().sizevalwidth1=size.widthvalheight1=size.height
// Access each dimension individuallyintx=driver.manage().window().getPosition().getX();inty=driver.manage().window().getPosition().getY();// Or store the dimensions and query them laterPointposition=driver.manage().window().getPosition();intx1=position.getX();inty1=position.getY();
# Access each dimension individuallyx=driver.get_window_position().get('x')y=driver.get_window_position().get('y')# Or store the dimensions and query them laterposition=driver.get_window_position()x1=position.get('x')y1=position.get('y')
//Access each dimension individuallyintx=driver.Manage().Window.Position.X;inty=driver.Manage().Window.Position.Y;//Or store the dimensions and query them laterPointposition=driver.Manage().Window.Position;intx1=position.X;inty1=position.Y;
#Access each dimension individuallyx=driver.manage.window.position.xy=driver.manage.window.position.y# Or store the dimensions and query them laterrect=driver.manage.window.rectx1=rect.xy1=rect.y
// Access each dimension individually
valx=driver.manage().window().position.xvaly=driver.manage().window().position.y// Or store the dimensions and query them later
valposition=driver.manage().window().positionvalx1=position.xvaly1=position.y
## ウィンドウの位置設定
選択した位置にウィンドウを移動します。
// Move the window to the top left of the primary monitordriver.manage().window().setPosition(newPoint(0,0));
# Move the window to the top left of the primary monitordriver.set_window_position(0,0)
// Move the window to the top left of the primary monitordriver.Manage().Window.Position=newPoint(0,0);
driver.manage.window.move_to(0,0)
// Move the window to the top left of the primary monitor
awaitdriver.manage().window().setRect({x:0,y:0});
// Move the window to the top left of the primary monitor
driver.manage().window().position=Point(0,0)
fromseleniumimportwebdriverdriver=webdriver.Chrome()# Navigate to urldriver.get("http://www.example.com")# Returns and base64 encoded string into imagedriver.save_screenshot('./image.png')driver.quit()
usingOpenQA.Selenium;usingOpenQA.Selenium.Chrome;usingOpenQA.Selenium.Support.UI;vardriver=newChromeDriver();driver.Navigate().GoToUrl("http://www.example.com");Screenshotscreenshot=(driverasITakesScreenshot).GetScreenshot();screenshot.SaveAsFile("screenshot.png",ScreenshotImageFormat.Png);// Format values are Bmp, Gif, Jpeg, Png, Tiff
require'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://example.com/'# Takes and Stores the screenshot in specified pathdriver.save_screenshot('./image.png')end
// Captures the screenshot
letencodedString=awaitdriver.takeScreenshot();// save screenshot as below
// await fs.writeFileSync('./image.png', encodedString, 'base64');
fromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriver=webdriver.Chrome()# Navigate to urldriver.get("http://www.example.com")ele=driver.find_element(By.CSS_SELECTOR,'h1')# Returns and base64 encoded string into imageele.screenshot('./image.png')driver.quit()
usingOpenQA.Selenium;usingOpenQA.Selenium.Chrome;usingOpenQA.Selenium.Support.UI;// Webdrivervardriver=newChromeDriver();driver.Navigate().GoToUrl("http://www.example.com");// Fetch element using FindElementvarwebElement=driver.FindElement(By.CssSelector("h1"));// Screenshot for the elementvarelementScreenshot=(webElementasITakesScreenshot).GetScreenshot();elementScreenshot.SaveAsFile("screenshot_of_element.png");
# Works with Selenium4-alpha7 Ruby bindings and aboverequire'selenium-webdriver'driver=Selenium::WebDriver.for:chromebegindriver.get'https://example.com/'ele=driver.find_element(:css,'h1')# Takes and Stores the element screenshot in specified pathele.save_screenshot('./image.jpg')end
letheader=awaitdriver.findElement(By.css('h1'));// Captures the element screenshot
letencodedString=awaitheader.takeScreenshot(true);// save screenshot as below
// await fs.writeFileSync('./image.png', encodedString, 'base64');
//Creating the JavascriptExecutor interface object by Type castingJavascriptExecutorjs=(JavascriptExecutor)driver;//Button ElementWebElementbutton=driver.findElement(By.name("btnLogin"));//Executing JavaScript to click on elementjs.executeScript("arguments[0].click();",button);//Get return value from scriptStringtext=(String)js.executeScript("return arguments[0].innerText",button);//Executing JavaScript directlyjs.executeScript("console.log('hello world')");
# Stores the header elementheader=driver.find_element(By.CSS_SELECTOR,"h1")# Executing JavaScript to capture innerText of header elementdriver.execute_script('return arguments[0].innerText',header)
//creating Chromedriver instanceIWebDriverdriver=newChromeDriver();//Creating the JavascriptExecutor interface object by Type castingIJavaScriptExecutorjs=(IJavaScriptExecutor)driver;//Button ElementIWebElementbutton=driver.FindElement(By.Name("btnLogin"));//Executing JavaScript to click on elementjs.ExecuteScript("arguments[0].click();",button);//Get return value from scriptStringtext=(String)js.ExecuteScript("return arguments[0].innerText",button);//Executing JavaScript directlyjs.ExecuteScript("console.log('hello world')");
# Stores the header elementheader=driver.find_element(css:'h1')# Get return value from scriptresult=driver.execute_script("return arguments[0].innerText",header)# Executing JavaScript directlydriver.execute_script("alert('hello world')")
// Stores the header element
letheader=awaitdriver.findElement(By.css('h1'));// Executing JavaScript to capture innerText of header element
lettext=awaitdriver.executeScript('return arguments[0].innerText',header);
// Stores the header element
valheader=driver.findElement(By.cssSelector("h1"))// Get return value from script
valresult=driver.executeScript("return arguments[0].innerText",header)// Executing JavaScript directly
driver.executeScript("alert('hello world')")
awaitdriver.get('https://www.selenium.dev/selenium/web/alerts.html');letbase64=awaitdriver.printPage({pageRanges:["1-2"]});// page can be saved as a PDF as below
// await fs.writeFileSync('./test.pdf', base64, 'base64');
Page being translated from English to Japanese.
Do you speak Japanese? Help us to translate
it by sending us pull requests!
Web applications can enable a public key-based authentication mechanism known as Web Authentication to authenticate users in a passwordless manner.
Web Authentication defines APIs that allows a user to create a public-key credential and register it with an authenticator.
An authenticator can be a hardware device or a software entity that stores user’s public-key credentials and retrieves them on request.
As the name suggests, Virtual Authenticator emulates such authenticators for testing.
Virtual Authenticator Options
A Virtual Authenticatior has a set of properties.
These properties are mapped as VirtualAuthenticatorOptions in the Selenium bindings.
options=VirtualAuthenticatorOptions()options.protocol=VirtualAuthenticatorOptions.Protocol.U2Foptions.has_resident_key=False# Register a virtual authenticatordriver.add_virtual_authenticator(options)
# parameters for Resident Credentialcredential_id=bytearray({1,2,3,4})rp_id="localhost"user_handle=bytearray({1})privatekey=urlsafe_b64decode(BASE64__ENCODED_PK)sign_count=0# create a resident credential using above parametersresident_credential=Credential.create_resident_credential(credential_id,rp_id,user_handle,privatekey,sign_count)
# parameters for Non Resident Credentialcredential_id=bytearray({1,2,3,4})rp_id="localhost"privatekey=urlsafe_b64decode(BASE64__ENCODED_PK)sign_count=0# create a non resident credential using above parameterscredential=Credential.create_non_resident_credential(credential_id,rp_id,privatekey,sign_count)
仮想化されたデバイス入力アクションを Web ブラウザーに提供するための低レベルのインターフェイス。
In addition to the high-level element interactions,
the Actions API provides granular control over
exactly what designated input devices can do. Selenium provides an interface for 3 kinds of input sources:
a key input for keyboard devices, a pointer input for a mouse, pen or touch devices,
and wheel inputs for scroll wheel devices (introduced in Selenium 4.2).
Selenium allows you to construct individual action commands assigned to specific
inputs and chain them together and call the associated perform method to execute them all at once.
Action Builder
In the move from the legacy JSON Wire Protocol to the new W3C WebDriver Protocol,
the low level building blocks of actions became especially detailed. It is extremely
powerful, but each input device has a number of ways to use it and if you need to
manage more than one device, you are responsible for ensuring proper synchronization between them.
Thankfully, you likely do not need to learn how to use the low level commands directly, since
almost everything you might want to do has been given a convenience method that combines the
lower level commands for you. These are all documented in
keyboard, mouse, pen, and wheel pages.
Pause
Pointer movements and Wheel scrolling allow the user to set a duration for the action, but sometimes you just need
to wait a beat between actions for things to work correctly.
An important thing to note is that the driver remembers the state of all the input
items throughout a session. Even if you create a new instance of an actions class, the depressed keys and
the location of the pointer will be in whatever state a previously performed action left them.
There is a special method to release all currently depressed keys and pointer buttons.
This method is implemented differently in each of the languages because
it does not get executed with the perform method.
A representation of any key input device for interacting with a web page.
There are only 2 actions that can be accomplished with a keyboard:
pressing down on a key, and releasing a pressed key.
In addition to supporting ASCII characters, each keyboard key has
a representation that can be pressed or released in designated sequences.
Keys
In addition to the keys represented by regular unicode,
unicode values have been assigned to other keyboard keys for use with Selenium.
Each language has its own way to reference these keys; the full list can be found
here.
Use the [Java Keys enum](https://github.com/SeleniumHQ/selenium/blob/selenium-4.2.0/java/src/org/openqa/selenium/Keys.java#L28)
Use the [Python Keys class](https://github.com/SeleniumHQ/selenium/blob/selenium-4.2.0/py/selenium/webdriver/common/keys.py#L23)
Use the [.NET static Keys class](https://github.com/SeleniumHQ/selenium/blob/selenium-4.2.0/dotnet/src/webdriver/Keys.cs#L28)
Use the [Ruby KEYS constant](https://github.com/SeleniumHQ/selenium/blob/selenium-4.2.0/rb/lib/selenium/webdriver/common/keys.rb#L28)
Use the [JavaScript KEYS constant](https://github.com/SeleniumHQ/selenium/blob/selenium-4.2.0/javascript/node/selenium-webdriver/lib/input.js#L44)
Use the [Java Keys enum](https://github.com/SeleniumHQ/selenium/blob/selenium-4.2.0/java/src/org/openqa/selenium/Keys.java#L28)
This is a convenience method in the Actions API that combines keyDown and keyUp commands in one action.
Executing this command differs slightly from using the element method, but
primarily this gets used when needing to type multiple characters in the middle of other actions.
Here’s an example of using all of the above methods to conduct a copy / paste action.
Note that the key to use for this operation will be different depending on if it is a Mac OS or not.
This code will end up with the text: SeleniumSelenium!
A representation of any pointer device for interacting with a web page.
There are only 3 actions that can be accomplished with a mouse:
pressing down on a button, releasing a pressed button, and moving the mouse.
Selenium provides convenience methods that combine these actions in the most common ways.
Click and hold
This method combines moving the mouse to the center of an element with pressing the left mouse button.
This is useful for focusing a specific element:
There are a total of 5 defined buttons for a Mouse:
0 — Left Button (the default)
1 — Middle Button (currently unsupported)
2 — Right Button
3 — X1 (Back) Button
4 — X2 (Forward) Button
Context Click
This method combines moving to the center of an element with pressing and releasing the right mouse button (button 2).
This is otherwise known as “right-clicking”:
This method moves the mouse to the in-view center point of the element.
This is otherwise known as “hovering.”
Note that the element must be in the viewport or else the command will error.
These methods first move the mouse to the designated origin and then
by the number of pixels in the provided offset.
Note that the position of the mouse must be in the viewport or else the command will error.
Offset from Element
This method moves the mouse to the in-view center point of the element,
then moves by the provided offset.
This method moves the mouse from its current position by the offset provided by the user.
If the mouse has not previously been moved, the position will be in the upper left
corner of the viewport.
Note that the pointer position does not change when the page is scrolled.
Note that the first argument X specifies to move right when positive, while the second argument
Y specifies to move down when positive. So moveByOffset(30, -10) moves right 30 and up 10 from
the current mouse position.
A Pen is a type of pointer input that has most of the same behavior as a mouse, but can
also have event properties unique to a stylus. Additionally, while a mouse
has 5 buttons, a pen has 3 equivalent button states:
0 — Touch Contact (the default; equivalent to a left click)
2 — Barrel Button (equivalent to a right click)
5 — Eraser Button (currently unsupported by drivers)
This is the most common scenario. Unlike traditional click and send keys methods,
the actions class does not automatically scroll the target element into view,
so this method will need to be used if elements are not already inside the viewport.
This method takes a web element as the sole argument.
Regardless of whether the element is above or below the current viewscreen,
the viewport will be scrolled so the bottom of the element is at the bottom of the screen.
This is the second most common scenario for scrolling. Pass in an delta x and a delta y value for how much to scroll
in the right and down directions. Negative values represent left and up, respectively.
This scenario is effectively a combination of the above two methods.
To execute this use the “Scroll From” method, which takes 3 arguments.
The first represents the origination point, which we designate as the element,
and the second two are the delta x and delta y values.
If the element is out of the viewport,
it will be scrolled to the bottom of the screen, then the page will be scrolled by the provided
delta x and delta y values.
This scenario is used when you need to scroll only a portion of the screen, and it is outside the viewport.
Or is inside the viewport and the portion of the screen that must be scrolled
is a known offset away from a specific element.
This uses the “Scroll From” method again, and in addition to specifying the element,
an offset is specified to indicate the origin point of the scroll. The offset is
calculated from the center of the provided element.
If the element is out of the viewport,
it first will be scrolled to the bottom of the screen, then the origin of the scroll will be determined
by adding the offset to the coordinates of the center of the element, and finally
the page will be scrolled by the provided delta x and delta y values.
Note that if the offset from the center of the element falls outside of the viewport,
it will result in an exception.
Scroll from a offset of origin (element) by given amount
The final scenario is used when you need to scroll only a portion of the screen,
and it is already inside the viewport.
This uses the “Scroll From” method again, but the viewport is designated instead
of an element. An offset is specified from the upper left corner of the
current viewport. After the origin point is determined,
the page will be scrolled by the provided delta x and delta y values.
Note that if the offset from the upper left corner of the viewport falls outside of the screen,
it will result in an exception.
BiDirectional means that communication is happening in two directions simultaneously.
The traditional WebDriver model involves strict request/response commands which only allows for communication to
happen in one direction at any given time. In most cases this is what you want; it ensures that the browser is
doing the expected things in the right order, but there are a number of interesting things that can be done with
asynchronous interactions.
This functionality is currently available in a limited fashion with the [Chrome DevTools Protocol] (CDP),
but to address some of its drawbacks, the Selenium team, along with the major
browser vendors, have worked to create the new WebDriver BiDi Protocol.
This specification aims to create a stable, cross-browser API that leverages bidirectional
communication for enhanced browser automation and testing functionality,
including streaming events from the user agent to the controlling software via WebSockets.
Users will be able to listen for and record or manipulate events as they happen during the course of a Selenium session.
Enabling BiDi in Selenium
In order to use WebDriver BiDi, setting the capability in the browser options will enable the required functionality:
options.setCapability("webSocketUrl",true);
options.enable_bidi=True
UseWebSocketUrl=true,
options.web_socket_url=true
Options().enableBidi();
options.setCapability("webSocketUrl",true);
This enables the WebSocket connection for bidirectional communication,
unlocking the full potential of the WebDriver BiDi protocol.
Note that Selenium is updating its entire implementation from WebDriver Classic to WebDriver BiDi (while
maintaining backwards compatibility as much as possible), but this section of documentation focuses on the new
functionality that bidirectional communication allows.
The low-level BiDi domains will be accessible in the code to the end user, but the goal is to provide
high-level APIs that are straightforward methods of real-world use cases. As such, the low-level
components will not be documented, and this section will focus only on the user-friendly
features that we encourage users to take advantage of.
If there is additional functionality you’d like to see, please raise a
feature request.
2.8.1 - WebDriver BiDi Logging Features
These features are related to logging. Because “logging” can refer to so many different things, these methods are made available via a “script” namespace.
Remember that to use WebDriver BiDi, you must enable it in Options.
For more details, see Enabling BiDi
These features are related to networking, and are made available via a “network” namespace.
The implementation of these features is being tracked here: #13993
Remember that to use WebDriver BiDi, you must enable it in Options.
For more details, see Enabling BiDi
Authentication Handlers
Request Handlers
Response Handlers
2.8.3 - WebDriver BiDi Script Features
These features are related to scripts, and are made available via a “script” namespace.
The implementation of these features is being tracked here: #13992
Remember that to use WebDriver BiDi, you must enable it in Options.
For more details, see Enabling BiDi
Script Pinning
Execute Script
DOM Mutation Handlers
2.8.4 - Chrome DevTools Protocol
Examples of working with Chrome DevTools Protocol in Selenium. CDP support is temporary until WebDriver BiDi has been implemented.
Page being translated from English to Japanese.
Do you speak Japanese? Help us to translate
it by sending us pull requests!
Many browsers provide “DevTools” – a set of tools that are integrated with the browser that
developers can use to debug web apps and explore the performance of their pages. Google Chrome’s
DevTools make use of a protocol called the Chrome DevTools Protocol (or “CDP” for short).
As the name suggests, this is not designed for testing, nor to have a stable API, so functionality
is highly dependent on the version of the browser.
Selenium is working to implement a standards-based, cross-browser, stable alternative to CDP called
[WebDriver BiDi]. Until the support for this new protocol has finished, Selenium plans to provide access
to CDP features where applicable.
Using Chrome DevTools Protocol with Selenium
Chrome and Edge have a method to send basic CDP commands.
This does not work for features that require bidirectional communication, and you need to know what domains to enable when
and the exact names and types of domains/methods/parameters.
To make working with CDP easier, and to provide access to the more advanced features, Selenium bindings
automatically generate classes and methods for the most common domains.
CDP methods and implementations can change from version to version, though, so you want to keep the
version of Chrome and the version of DevTools matching. Selenium supports the 3 most
recent versions of Chrome at any given time,
and tries to time releases to ensure that access to the latest versions are available.
This limitation provides additional challenges for several bindings, where dynamically
generated CDP support requires users to regularly update their code to reference the proper version of CDP.
In some cases an idealized implementation has been created that should work for any version of CDP without the
user needing to change their code, but that is not always available.
Examples of how to use CDP in your Selenium tests can be found on the following pages, but
we want to call out a couple commonly cited examples that are of limited practical value.
Geo Location — almost all sites use the IP address to determine physical location,
so setting an emulated geolocation rarely has the desired effect.
Overriding Device Metrics — Chrome provides a great API for setting Mobile Emulation
in the Options classes, which is generally superior to attempting to do this with CDP.
2.8.4.1 - Chrome DevTools Logging Features
Logging features using CDP.
Page being translated from English to Japanese.
Do you speak Japanese? Help us to translate
it by sending us pull requests!
While Selenium 4 provides direct access to the Chrome DevTools Protocol, these
methods will eventually be removed when WebDriver BiDi implemented.
Page being translated from English to Japanese.
Do you speak Japanese? Help us to translate
it by sending us pull requests!
While Selenium 4 provides direct access to the Chrome DevTools Protocol, these
methods will eventually be removed when WebDriver BiDi implemented.
Basic authentication
Some applications make use of browser authentication to secure pages.
It used to be common to handle them in the URL, but browsers stopped supporting this.
With this code you can insert the credentials into the header when necessary
Page being translated from English to Japanese.
Do you speak Japanese? Help us to translate
it by sending us pull requests!
The following list of APIs will be growing as the WebDriver BiDirectional Protocol grows
and browser vendors implement the same.
Additionally, Selenium will try to support real-world use cases that internally use a combination of W3C BiDi protocol APIs.
If there is additional functionality you’d like to see, please raise a
feature request.
2.8.5.1 - Browsing Context
Page being translated from
English to Japanese. Do you speak Japanese? Help us to translate
it by sending us pull requests!
Commands
This section contains the APIs related to browsing context commands.
A reference browsing context is a top-level browsing context.
The API allows to pass the reference browsing context, which is used to create a new window. The implementation is operating system specific.
A reference browsing context is a top-level browsing context.
The API allows to pass the reference browsing context, which is used to create a new tab. The implementation is operating system specific.
Provides a tree of all browsing contexts descending from the parent browsing context, including the parent browsing context upto the depth value passed.
voidtestGetTreeWithDepth(){StringreferenceContextId=driver.getWindowHandle();BrowsingContextparentWindow=newBrowsingContext(driver,referenceContextId);parentWindow.navigate("https://www.selenium.dev/selenium/web/iframes.html",ReadinessState.COMPLETE);List<BrowsingContextInfo>contextInfoList=parentWindow.getTree(0);Assertions.assertEquals(1,contextInfoList.size());BrowsingContextInfoinfo=contextInfoList.get(0);Assertions.assertNull(info.getChildren());// since depth is 0Assertions.assertEquals(referenceContextId,info.getId());}
try(Networknetwork=newNetwork(driver)){network.addIntercept(newAddInterceptParameters(InterceptPhase.AUTH_REQUIRED));network.onAuthRequired(responseDetails->// Does not handle the alertnetwork.continueWithAuthNoCredentials(responseDetails.getRequest().getRequestId()));driver.get("https://the-internet.herokuapp.com/basic_auth");
try(Networknetwork=newNetwork(driver)){network.addIntercept(newAddInterceptParameters(InterceptPhase.AUTH_REQUIRED));network.onAuthRequired(responseDetails->// Does not handle the alertnetwork.cancelAuth(responseDetails.getRequest().getRequestId()));driver.get("https://the-internet.herokuapp.com/basic_auth");
constinspector=awaitLogInspector(driver)awaitinspector.onJavascriptException(function(log){logEntry=log})awaitdriver.get('https://www.selenium.dev/selenium/web/bidi/logEntryAdded.html')awaitdriver.findElement({id:'jsException'}).click()assert.equal(logEntry.text,'Error: Not working')assert.equal(logEntry.type,'javascript')assert.equal(logEntry.level,'error')
The core libraries of Selenium try to be low level and non-opinionated.
The Support classes in each language provide opinionated wrappers for common interactions
that may be used to simplify some behaviors.
2.9.1 - Waiting with Expected Conditions
These are classes used to describe what needs to be waited for.
Expected Conditions are used with Explicit Waits.
Instead of defining the block of code to be executed with a lambda, an expected
conditions method can be created to represent common things that get waited on. Some
methods take locators as arguments, others take elements as arguments.
The Select object will now give you a series of commands
that allow you to interact with a <select> element.
If you are using Java or .NET make sure that you’ve properly required the support package
in your code. See the full code from GitHub in any of the examples below.
Note that this class only works for HTML elements select and option.
It is possible to design drop-downs with JavaScript overlays using div or li,
and this class will not work for those.
Types
Select methods may behave differently depending on which type of <select> element is being worked with.
Single select
This is the standard drop-down object where one and only one option may be selected.
<selectname="selectomatic"><optionselected="selected"id="non_multi_option"value="one">One</option><optionvalue="two">Two</option><optionvalue="four">Four</option><optionvalue="still learning how to count, apparently">Still learning how to count, apparently</option></select>
Multiple select
This select list allows selecting and deselecting more than one option at a time.
This only applies to <select> elements with the multiple attribute.
First locate a <select> element, then use it to initialize a Select object.
Note that as of Selenium 4.5, you can’t create a Select object if the <select> element is disabled.
Get a list of selected options in the <select> element. For a standard select list
this will only be a list with one element, for a multiple select list it can contain
zero or many elements.
The Select class provides three ways to select an option.
Note that for multiple select type Select lists, you can repeat these methods
for each element you want to select.
publicclassDriverClash{//thread main (id 1) created this driverprivateWebDriverprotectedDriver=ThreadGuard.protect(newChromeDriver());static{System.setProperty("webdriver.chrome.driver","<Set path to your Chromedriver>");}//Thread-1 (id 24) is calling the same driver causing the clash to happenRunnabler1=()->{protectedDriver.get("https://selenium.dev");};Threadthr1=newThread(r1);voidrunThreads(){thr1.start();}publicstaticvoidmain(String[]args){newDriverClash().runThreads();}}
結果は以下のとおりです。
Exception in thread "Thread-1" org.openqa.selenium.WebDriverException:
Thread safety error; this instance of WebDriver was constructed
on thread main (id 1)and is being accessed by thread Thread-1 (id 24)
This is not permitted and *will* cause undefined behaviour
It is not always obvious the root cause of errors in Selenium.
The most common Selenium-related error is a result of poor synchronization.
Read about Waiting Strategies. If you aren’t sure if it
is a synchronization strategy you can try temporarily hard coding a large sleep
where you see the issue, and you’ll know if adding an explicit wait can help.
Note that many errors that get reported to the project are actually caused by
issues in the underlying drivers that Selenium sends the commands to. You can rule
out a driver problem by executing the command in multiple browsers.
If you have questions about how to do things, check out the Support options
for ways get assistance.
If you think you’ve found a problem with Selenium code, go ahead and file a
Bug Report
on GitHub.
2.10.1 - Understanding Common Errors
How to solve various problems in your Selenium code.
InvalidSelectorException
CSS and XPath Selectors are sometimes difficult to get correct.
Likely Cause
The CSS or XPath selector you are trying to use has invalid characters or an invalid query.
An element goes stale when it was previously located, but can not be currently accessed.
Elements do not get relocated automatically; the driver creates a reference ID for the element and
has a particular place it expects to find it in the DOM. If it can not find the element
in the current DOM, any action using that element will result in this exception.
Likely Cause
This can happen when:
You have refreshed the page, or the DOM of the page has dynamically changed.
You have navigated to a different page.
You have switched to another window or into or out of a frame or iframe.
Possible Solutions
The DOM has changed
When the page is refreshed or items on the page have moved around, there is still
an element with the desired locator on the page, it is just no longer accessible
by the element object being used, and the element must be relocated before it can be used again.
This is often done in one of two ways:
Always relocate the element every time you go to use it. The likelihood of
the element going stale in the microseconds between locating and using the element
is small, though possible. The downside is that this is not the most efficient approach,
especially when running on a remote grid.
Wrap the Web Element with another object that stores the locator, and caches the
located Selenium element. When taking actions with this wrapped object, you can
attempt to use the cached object if previously located, and if it is stale, exception
can be caught, the element relocated with the stored locator, and the method re-tried.
This is more efficient, but it can cause problems if the locator you’re using
references a different element (and not the one you want) after the page has changed.
The Context has changed
Element objects are stored for a given context, so if you move to a different context —
like a different window or a different frame or iframe — the element reference will
still be valid, but will be temporarily inaccessible. In this scenario, it won’t
help to relocate the element, because it doesn’t exist in the current context.
To fix this, you need to make sure to switch back to the correct context before using the element.
The Page has changed
This scenario is when you haven’t just changed contexts, you have navigated to another page
and have destroyed the context in which the element was located.
You can’t just relocate it from the current context,
and you can’t switch back to an active context where it is valid. If this is the reason
for your error, you must both navigate back to the correct location and relocate it.
ElementClickInterceptedException
This exception occurs when Selenium tries to click an element, but the click would instead
be received by a different element. Before Selenium will click an element, it checks if the
element is visible, unobscured by any other elements, and enabled - if the element is obscured,
it will raise this exception.
Likely Cause
UI Elements Overlapping
Elements on the UI are typically placed next to each other, but occasionally elements may overlap.
For example, a navbar always staying at the top of your window as you scroll a page. If that navbar
happens to be covering an element we are trying to click, Selenium might believe it to be visible
and enabled, but when you try to click it will throw this exception. Pop-ups and Modals are also
common offenders here.
Animations
Elements with animations have the potential to cause this exception as well - it is recommended to
wait for animations to cease before attempting to click an element.
Possible Solutions
Use Explicit Waits
Explicit Waits will likely be your best friend in these instances.
A great way is to use ExpectedCondition.ToBeClickable() with WebDriverWait to wait until the right moment.
Scroll the Element into View
In instances where the element is out of view, but Selenium still registers the element as visible
(e.g. navbars overlapping a section at the top of your screen), you can use the WebDriver.executeScript()
method to execute a javascript function to scroll (e.g. WebDriver.executeScript('window.scrollBy(0,-250)'))
or you can utilize the Actions class with Actions.moveToElement(element).
InvalidSessionIdException
Sometimes the session you’re trying to access is different than what’s currently available
Likely Cause
This usually occurs when the session has been deleted (e.g. driver.quit()) or if the session has changed,
like when the last tab/browser has closed (e.g. driver.close())
Possible Solutions
Check your script for instances of driver.close() and driver.quit(), and any other possible causes of closed
tabs/browsers. It could be that you are locating an element before you should/can.
SessionNotCreatedException
This exception occurs when the WebDriver is unable to create a new session for the browser. This often happens due to version mismatches, system-level restrictions, or configuration issues.
Likely Cause
The browser version and WebDriver version are incompatible (e.g., ChromeDriver v113 with Chrome v115).
macOS privacy settings may block the WebDriver from running.
The WebDriver binary is missing, inaccessible, or lacks the necessary execution permissions (e.g., on Linux/macOS, the driver file may not be executable).
Possible Solutions
Ensure the WebDriver version matches the browser version. For Chrome, check the browser version at chrome://settings/help and download the matching driver from ChromeDriver Downloads.
On macOS, go to System Settings > Privacy & Security, and allow the driver to run if blocked.
Verify the driver binary is executable (chmod +x /path/to/driver on Linux/macOS).
ElementNotInteractableException
This exception occurs when Selenium tries to interact with an element that is not interactable in its current state.
Likely Cause
Unsupported Operation: Performing an action, like sendKeys, on an element that doesn’t support it (e.g., <form> or <label>).
Multiple Elements Matching Locator: The locator targets a non-interactable element, such as a <td> tag, instead of the intended <input> field.
Hidden Elements: The element is present in the DOM but not visible on the page due to CSS, the hidden attribute, or being outside the visible viewport.
Possible Solutions
Use actions appropriate for the element type (e.g., use sendKeys with <input> fields only).
Ensure locators uniquely identify the intended element to avoid incorrect matches.
Check if the element is visible on the page before interacting with it. Use scrolling to bring the element into view, if required.
Use explicit waits to ensure the element is interactable before performing actions.
2.10.1.1 - Unable to Locate Driver Error
Troubleshooting missing path to driver executable.
Historically, this is the most common error beginning Selenium users get
when trying to run code for the first time:
The path to the driver executable must
be set by the webdriver.chrome.driver system property;
for more information, see https://chromedriver.chromium.org/.
The latest version can be downloaded from https://chromedriver.chromium.org/downloads
The executable chromedriver needs to be available in the path.
The file geckodriver does not exist. The driver can be downloaded at https://github.com/mozilla/geckodriver/releases"
Unable to locate the chromedriver executable;
Likely cause
Through WebDriver, Selenium supports all major browsers.
In order to drive the requested browser, Selenium needs to
send commands to it via an executable driver.
This error means the necessary driver could not be
found by any of the means Selenium attempts to use.
Possible solutions
There are several ways to ensure Selenium gets the driver it needs.
Use the latest version of Selenium
As of Selenium 4.6, Selenium downloads the correct driver for you.
You shouldn’t need to do anything. If you are using the latest version
of Selenium and you are getting an error,
please turn on logging
and file a bug report with that information.
If you want to read more information about how Selenium manages driver downloads for you,
you can read about the Selenium Manager.
This is a flexible option to change location of drivers without having to update your code,
and will work on multiple machines without requiring that each machine put the
drivers in the same place.
You can either place the drivers in a directory that is already listed in PATH,
or you can place them in a directory and add it to PATH.
To see what directories are already on PATH, open a Terminal and execute:
echo$PATH
If the location to your driver is not already in a directory listed,
you can add a new directory to PATH:
You can test if it has been added correctly by checking the version of the driver:
chromedriver --version
To see what directories are already on PATH, open a Command Prompt and execute:
echo %PATH%
If the location to your driver is not already in a directory listed,
you can add a new directory to PATH:
setx PATH "%PATH%;C:\WebDriver\bin"
You can test if it has been added correctly by checking the version of the driver:
chromedriver.exe --version
Specify the location of the driver
If you cannot upgrade to the latest version of Selenium, you
do not want Selenium to download drivers for you, and you can’t figure
out the environment variables, you can specify the location of the driver in the Service object.
Specifying the location in the code itself has the advantage of not needing
to figure out Environment Variables on your system, but has the drawback of
making the code less flexible.
Driver management libraries
Before Selenium managed drivers itself, other projects were created to
do so for you.
If you can’t use Selenium Manager because you are using
an older version of Selenium (please upgrade),
or need an advanced feature not yet implemented by Selenium Manager,
you might try one of these tools to keep your drivers automatically updated:
Note: The Opera driver no longer works with the latest functionality of Selenium and is currently officially unsupported.
2.10.2 - Logging Selenium commands
Getting information about Selenium execution.
Turning on logging is a valuable way to get extra information that might help you determine
why you might be having a problem.
Getting a logger
Java logs are typically created per class. You can work with the default logger to
work with all loggers. To filter out specific classes, see Filtering
Java Logging is not exactly straightforward, and if you are just looking for an easy way
to look at the important Selenium logs,
take a look at the Selenium Logger project
Python logs are typically created per module. You can match all submodules by referencing the top
level module. So to work with all loggers in selenium module, you can do this:
.NET logger is managed with a static class, so all access to logging is managed simply by referencing Log from the OpenQA.Selenium.Internal.Logging namespace.
If you want to see as much debugging as possible in all the classes,
you can turn on debugging globally in Ruby by setting $DEBUG = true.
For more fine-tuned control, Ruby Selenium created its own Logger class to wrap the default Logger class.
This implementation provides some interesting additional features.
Obtain the logger directly from the #loggerclass method on the Selenium::WebDriver module:
Things get complicated when you use PyTest, though. By default, PyTest hides logging unless the test
fails. You need to set 3 things to get PyTest to display logs on passing tests.
To always output logs with PyTest you need to run with additional arguments.
First, -s to prevent PyTest from capturing the console.
Second, -p no:logging, which allows you to override the default PyTest logging settings so logs can
be displayed regardless of errors.
So you need to set these flags in your IDE, or run PyTest on command line like:
pytest -s -p no:logging
Finally, since you turned off logging in the arguments above, you now need to add configuration to
turn it back on:
logging.basicConfig(level=logging.WARN)
.NET has 6 logger levels: Error, Warn, Info, Debug, Trace and None. The default level is Info.
Things are logged as warnings if they are something the user needs to take action on. This is often used
for deprecations. For various reasons, Selenium project does not follow standard Semantic Versioning practices.
Our policy is to mark things as deprecated for 3 releases and then remove them, so deprecations
may be logged as warnings.
Java logs actionable content at logger level WARN
Example:
May 08, 2023 9:23:38 PM dev.selenium.troubleshooting.LoggingTest logging
WARNING: this is a warning
Python logs actionable content at logger level — WARNING
Details about deprecations are logged at this level.
Example:
WARNING selenium:test_logging.py:23 this is a warning
.NET logs actionable content at logger level Warn.
Example:
11:04:40.986 WARN LoggingTest: this is a warning
Ruby logs actionable content at logger level — :warn.
Details about deprecations are logged at this level.
For example:
2023-05-08 20:53:13 WARN Selenium [:example_id] this is a warning
Because these items can get annoying, we’ve provided an easy way to turn them off, see filtering section below.
Content Help
Note: This section needs additional and/or updated content
This is the default level where Selenium logs things that users should be aware of but do not need to take actions on.
This might reference a new method or direct users to more information about something
Java logs useful information at logger level INFO
Example:
May 08, 2023 9:23:38 PM dev.selenium.troubleshooting.LoggingTest logging
INFO: this is useful information
Python logs useful information at logger level — INFO
Example:
INFO selenium:test_logging.py:22 this is useful information
.NET logs useful information at logger level Info.
Example:
11:04:40.986 INFO LoggingTest: this is useful information
Ruby logs useful information at logger level — :info.
Example:
2023-05-08 20:53:13 INFO Selenium [:example_id] this is useful information
Logs useful information at level: INFO
Content Help
Note: This section needs additional and/or updated content
Java logging is managed on a per class level, so
instead of using the root logger (Logger.getLogger("")), set the level you want to use on a per-class
basis:
Ruby’s logger allows you to opt in (“allow”) or opt out (“ignore”) of log messages based on their IDs.
Everything that Selenium logs includes an ID. You can also turn on or off all deprecation notices by
using :deprecations.
These methods accept one or more symbols or an array of symbols:
<dependencies><!-- more dependencies ... --><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>3.141.59</version></dependency><!-- more dependencies ... --></dependencies>
After
<dependencies><!-- more dependencies ... --><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.4.0</version></dependency><!-- more dependencies ... --></dependencies>
var browserOptions = new ChromeOptions();
browserOptions.PlatformName = "Windows 10";
browserOptions.BrowserVersion = "latest";
var cloudOptions = new Dictionary<string, object>();
browserOptions.AddAdditionalCapability("cloud:options", cloudOptions, true);
After
var browserOptions = new ChromeOptions();
browserOptions.PlatformName = "Windows 10";
browserOptions.BrowserVersion = "latest";
var cloudOptions = new Dictionary<string, object>();
browserOptions.AddAdditionalOption("cloud:options", cloudOptions);
Selenium Manager is a command-line tool implemented in Rust that provides automated driver and browser management for Selenium. Selenium bindings use this tool by default, so you do not need to download it or add anything to your code or do anything else to use it.
Motivation
TL;DR:Selenium Manager is the official driver manager of the Selenium project, and it is shipped out of the box with every Selenium release.
Selenium uses the native support implemented by each browser to carry out the automation process. For this reason, Selenium users need to place a component called driver (chromedriver, geckodriver, msedgedriver, etc.) between the script using the Selenium API and the browser. For many years, managing these drivers was a manual process for Selenium users. This way, they had to download the required driver for a browser (chromedriver for Chrome, geckodriver for Firefox, etc.) and place it in the PATH or export the driver path as a system property (Java, JavaScript, etc.). But this process was cumbersome and led to maintainability issues.
Let’s consider an example. Imagine you manually downloaded the required chromedriver for driving your Chrome with Selenium. When you did this process, the stable version of Chrome was 113, so you downloaded chromedriver 113 and put it in your PATH. At that moment, your Selenium script executed correctly. But the problem is that Chrome is evergreen. This name refers to Chrome’s ability to upgrade automatically and silently to the next stable version when available. This feature is excellent for end-users but potentially dangerous for browser automation. Let’s go back to the example to discover it. Your local Chrome eventually updates to version 115. And that moment, your Selenium script is broken due to the incompatibility between the manually downloaded driver (113) and the Chrome version (115). Thus, your Selenium script fails with the following error message: “session not created: This version of ChromeDriver only supports Chrome version 113”.
This problem is the primary reason for the existence of the so-called driver managers (such as WebDriverManager for Java,
webdriver-manager for Python, webdriver-manager for JavaScript, WebDriverManager.Net for C#, and webdrivers for Ruby). All these projects were an inspiration and a clear sign that the community needed this feature to be built in Selenium. Thus, the Selenium project has created Selenium Manager, the official driver manager for Selenium, shipped out of the box with each Selenium release as of version 4.6.
Usage
TL;DR:Selenium Manager is used by the Selenium bindings when the drivers (chromedriver, geckodriver, etc.) are unavailable.
Driver management through Selenium Manager is opt-in for the Selenium bindings. Thus, users can continue managing their drivers manually (putting the driver in the PATH or using system properties) or rely on a third-party driver manager to do it automatically. Selenium Manager only operates as a fallback: if no driver is provided, Selenium Manager will come to the rescue.
Selenium Manager is a CLI (command line interface) tool implemented in Rust to allow cross-platform execution and compiled for Windows, Linux, and macOS. The Selenium Manager binaries are shipped with each Selenium release. This way, each Selenium binding language invokes Selenium Manager to carry out the automated driver and browser management explained in the following sections.
Automated driver management
TL;DR:Selenium Manager automatically discovers, downloads, and caches the drivers required by Selenium when these drivers are unavailable.
The primary feature of Selenium Manager is called automated driver management. Let’s consider an example to understand it. Suppose we want to driver Chrome with Selenium (see the doc about how to start a session with Selenium). Before the session begins, and when the driver is unavailable, Selenium Manager manages chromedriver for us. We use the term management for this feature (and not just download) since this process is broader and implies different steps:
Browser version discovery. Selenium Manager discovers the browser version (e.g., Chrome, Firefox, Edge) installed in the machine that executes Selenium. This step uses shell commands (e.g., google-chrome --version).
Driver version discovery. With the discovered browser version, the proper driver version is resolved. For this step, the online metadata/endpoints maintained by the browser vendors (e.g., chromedriver, geckodriver, or msedgedriver) are used.
Driver download. The driver URL is obtained with the resolved driver version; with that URL, the driver artifact is downloaded, uncompressed, and stored locally.
Driver cache. Uncompressed driver binaries are stored in a local cache folder (~/.cache/selenium). The next time the same driver is required, it will be used from there if the driver is already in the cache.
Automated browser management
TL;DR:Selenium Manager automatically discovers, downloads, and caches the browsers driven with Selenium (Chrome, Firefox, and Edge) when these browsers are not installed in the local system.
As of Selenium 4.11.0, Selenium Manager also implements automated browser management. With this feature, Selenium Manager allows us to discover, download, and cache the different browser releases, making them seamlessly available for Selenium. Internally, Selenium Manager uses an equivalent management procedure explained in the section before, but this time, for browser releases.
The browser automatically managed by Selenium Manager are:
Let’s consider again the typical example of driving Chrome with Selenium. And this time, suppose Chrome is not installed on the local machine when starting a new session). In that case, the current stable CfT release will be discovered, downloaded, and cached (in ~/.cache/selenium/chrome) by Selenium Manager.
But there is more. In addition to the stable browser version, Selenium Manager also allows downloading older browser versions (in the case of CfT, starting in version 113, the first version published as CfT). To set a browser version with Selenium, we use a browser option called browserVersion.
Let’s consider another simple example. Suppose we set browserVersion to 114 using Chrome options. In this case, Selenium Manager will check if Chrome 114 is already installed. If it is, it will be used. If not, Selenium Manager will manage (i.e., discover, download, and cache) CfT 114. And in either case, the chromedriver is also managed. Finally, Selenium will start Chrome to be driven programmatically, as usual.
But there is even more. In addition to fixed browser versions (e.g., 113, 114, 115, etc.), we can use the following labels for browserVersion:
stable: Current CfT version.
beta: Next version to stable.
dev: Version in development at this moment.
canary: Nightly build for developers.
esr: Extended Support Release (only for Firefox).
When these labels are specified, Selenium Manager first checks if a given browser is already installed (beta, dev, etc.), and when it is not detected, the browser is automatically managed.
Edge in Windows
Automated Edge management by Selenium Manager in Windows is different from other browsers. Both Chrome and Firefox (and Edge in macOS and Linux) are downloaded automatically to the local cache (~/.cache/selenium) by Selenium Manager. Nevertheless, the same cannot be done for Edge in Windows. The reason is that the Edge installer for Windows is distributed as a Microsoft Installer (MSI) file, designed to be executed with administrator rights. This way, when Edge is attempted to be installed with Selenium Manager in Windows with a non-administrator session, a warning message will be displayed by Selenium Manager as follows:
edge can only be installed in Windows with administrator permissions
Therefore, administrator permissions are required to install Edge in Windows automatically through Selenium Manager, and Edge is eventually installed in the usual program files folder (e.g., C:\Program Files (x86)\Microsoft\Edge).
Data collection
Selenium Manager will report anonymised usage statistics to Plausible. This allows the Selenium team to understand more about how Selenium is being used so that we can better focus our development efforts. The data being collected is:
Data
Purpose
Selenium version
This allows the Selenium developers to safely deprecate and remove features, as well as determine which new features may be available to you
Language binding
Programming language used to execute Selenium scripts (Java, JavaScript, Python, .Net, Ruby)
OS and architecture Selenium Manager is running on
The Selenium developers can use this information to help prioritise bug reports, and to identify if there are systemic OS-related issues
Browser and browser version
Helping for prioritising bug reports
Rough geolocation
Derived from the IP address you connect from. This is useful for determining where we need to focus our documentation efforts
Selenium Manager sends these data to Plausible once a day. This period is based on the TTL value (see configuration).
Opting out of data collection
Data collection is on by default. To disable it, set the SE_AVOID_STATS environment variable to true. You may also disable data collection in the configuration file (see below) by setting avoid-stats = true.
Configuration
TL;DR:Selenium Manager should work silently and transparently for most users. Nevertheless, there are scenarios (e.g., to specify a custom cache path or setup globally a proxy) where custom configuration can be required.
Selenium Manager is a CLI tool. Therefore, under the hood, the Selenium bindings call Selenium Manager by invoking shell commands. Like any other CLI tool, arguments can be used to specify specific capabilities in Selenium Manager. The different arguments supported by Selenium Manager can be checked by running the following command:
$ ./selenium-manager --help
In addition to CLI arguments, Selenium Manager allows two additional mechanisms for configuration:
Configuration file. Selenium Manager uses a file called se-config.toml located in the Selenium cache (by default, at ~/.cache/selenium) for custom configuration values. This TOML file contains a key-value collection used for custom configuration.
Environmental variables. Each configuration key has its equivalence in environmental variables by converting each key name to uppercase, replacing the dash symbol (-) with an underscore (_), and adding the prefix SE_.
The configuration file is honored by Selenium Manager when it is present, and the corresponding CLI parameter is not specified. Besides, the environmental variables are used when neither of the previous options (CLI arguments and configuration file) is specified. In other words, the order of preference for Selenium Manager custom configuration is as follows:
CLI arguments.
Configuration file.
Environment variables.
Notice that the Selenium bindings use the CLI arguments to specify configuration values, which in turn, are defined in each binding using browser options.
The following table summarizes all the supported arguments supported by Selenium Manager and their correspondence key in the configuration file and environment variables.
CLI argument
Configuration file
Env variable
Description
--browser BROWSER
browser = "BROWSER"
SE_BROWSER=BROWSER
Browser name: chrome, firefox, edge, iexplorer, safari, safaritp, or webview2
--driver <DRIVER>
driver = "DRIVER"
SE_DRIVER=DRIVER
Driver name: chromedriver, geckodriver, msedgedriver, IEDriverServer, or safaridriver
--browser-version <BROWSER_VERSION>
browser-version = "BROWSER_VERSION"
SE_BROWSER_VERSION=BROWSER_VERSION
Major browser version (e.g., 105, 106, etc. Also: beta, dev, canary -or nightly-, and esr -in Firefox- are accepted)
--driver-version <DRIVER_VERSION>
driver-version = "DRIVER_VERSION"
SE_DRIVER_VERSION=DRIVER_VERSION
Driver version (e.g., 106.0.5249.61, 0.31.0, etc.)
--browser-path <BROWSER_PATH>
browser-path = "BROWSER_PATH"
SE_BROWSER_PATH=BROWSER_PATH
Browser path (absolute) for browser version detection (e.g., /usr/bin/google-chrome, /Applications/Google Chrome.app/Contents/MacOS/Google Chrome, C:\Program Files\Google\Chrome\Application\chrome.exe)
--driver-mirror-url <DRIVER_MIRROR_URL>
driver-mirror-url = "DRIVER_MIRROR_URL"
SE_DRIVER_MIRROR_URL=DRIVER_MIRROR_URL
Mirror URL for driver repositories
--browser-mirror-url <BROWSER_MIRROR_URL>
browser-mirror-url = "BROWSER_MIRROR_URL"
SE_BROWSER_MIRROR_URL=BROWSER_MIRROR_URL
Mirror URL for browser repositories
--output <OUTPUT>
output = "OUTPUT"
SE_OUTPUT=OUTPUT
Output type: LOGGER (using INFO, WARN, etc.), JSON (custom JSON notation), SHELL (Unix-like), or MIXED (INFO, WARN, DEBUG, etc. to stderr and minimal JSON to stdout). Default: LOGGER
--os <OS>
os = "OS"
SE_OS=OS
Operating system for drivers and browsers (i.e., windows, linux, or macos)
--arch <ARCH>
arch = "ARCH"
SE_ARCH=ARCH
System architecture for drivers and browsers (i.e., x32, x64, or arm64)
--proxy <PROXY>
proxy = "PROXY"
SE_PROXY=PROXY
HTTP proxy for network connection (e.g., myproxy:port, myuser:mypass@myproxy:port)
--timeout <TIMEOUT>
timeout = TIMEOUT
SE_TIMEOUT=TIMEOUT
Timeout for network requests (in seconds). Default: 300
--offline
offline = true
SE_OFFLINE=true
Offline mode (i.e., disabling network requests and downloads)
--force-browser-download
force-browser-download = true
SE_FORCE_BROWSER_DOWNLOAD=true
Force to download browser, e.g., when a browser is already installed in the system, but you want Selenium Manager to download and use it
--avoid-browser-download
avoid-browser-download = true
SE_AVOID_BROWSER_DOWNLOAD=true
Avoid to download browser, e.g., when a browser is supposed to be downloaded by Selenium Manager, but you prefer to avoid it
--debug
debug = true
SE_DEBUG=true
Display DEBUG messages
--trace
trace = true
SE_TRACE=true
Display TRACE messages
--cache-path <CACHE_PATH>
cache-path="CACHE_PATH"
SE_CACHE_PATH=CACHE_PATH
Local folder used to store downloaded assets (drivers and browsers), local metadata, and configuration file. See next section for details. Default: ~/.cache/selenium. For Windows paths in the TOML configuration file, double backslashes are required (e.g., C:\\custom\\cache).
--ttl <TTL>
ttl = TTL
SE_TTL=TTL
Time-to-live in seconds. See next section for details. Default: 3600 (1 hour)
--language-binding <LANGUAGE>
language-binding = "LANGUAGE"
SE_LANGUAGE_BINDING=LANGUAGE
Language that invokes Selenium Manager (e.g., Java, JavaScript, Python, DotNet, Ruby)
--avoid-stats
avoid-stats = true
SE_AVOID_STATS=true
Avoid sends usage statistics to plausible.io. Default: false
In addition to the configuration keys specified in the table before, there are some special cases, namely:
Browser version. In addition to browser-version, we can use the specific configuration keys to specify custom versions per supported browser. This way, the keys chrome-version, firefox-version, edge-version, etc., are supported. The same applies to environment variables (i.e., SE_CHROME_VERSION, SE_FIREFOX_VERSION, SE_EDGE_VERSION, etc.).
Driver version. Following the same pattern, we can use chromedriver-version, geckodriver-version, msedgedriver-version, etc. (in the configuration file), and SE_CHROMEDRIVER_VERSION, SE_GECKODRIVER_VERSION, SE_MSEDGEDRIVER_VERSION, etc. (as environment variables).
Browser path. Following the same pattern, we can use chrome-path, firefox-path, edge-path, etc. (in the configuration file), and SE_CHROME_PATH, SE_FIREFOX_PATH, SE_EDGE_PATH, etc. (as environment variables). The Selenium bindings also allow to specify a custom location of the browser path using options, namely: Chrome), Edge, or Firefox.
Driver mirror. Following the same pattern, we can use chromedriver-mirror-url, geckodriver-mirror-url, msedgedriver-mirror-url, etc. (in the configuration file), and SE_CHROMEDRIVER_MIRROR_URL, SE_GECKODRIVER_MIRROR_URL, SE_MSEDGEDRIVER_MIRROR_URL, etc. (as environment variables).
Browser mirror. Following the same pattern, we can use chrome-mirror-url, firefox-mirror-url, edge-mirror-url, etc. (in the configuration file), and SE_CHROME_MIRROR_URL, SE_FIREFOX_MIRROR_URL, SE_EDGE_MIRROR_URL, etc. (as environment variables).
TL;DR:The drivers and browsers managed by Selenium Manager are stored in a local folder (~/.cache/selenium).
The cache in Selenium Manager is a local folder (~/.cache/selenium by default) in which the downloaded assets (drivers and browsers) are stored. For the sake of performance, when a driver or browser is already in the cache (i.e., there is a cache hint), Selenium Manager uses it from there.
In addition to the downloaded drivers and browsers, two additional files live in the cache’s root:
Configuration file (se-config.toml). This file is optional and, as explained in the previous section, allows to store custom configuration values for Selenium Manager. This file is maintained by the end-user and read by Selenium Manager.
Metadata file (se-metadata.json). This file contains versions discovered by Selenium Manger making network requests (e.g., using the CfT JSON endpoints) and the time-to-live (TTL) in which they are valid. Selenium Manager automatically maintains this file.
The TTL in Selenium Manager is inspired by the TTL for DNS, a well-known mechanism that refers to how long some values are cached before they are automatically refreshed. In the case of Selenium Manager, these values are the versions found by making network requests for driver and browser version discovery. By default, the TTL is 3600 seconds (i.e., 1 hour) and can be tuned using configuration values or disabled by setting this configuration value to 0.
The TTL mechanism is a way to improve the overall performance of Selenium. It is based on the fact that the discovered driver and browser versions (e.g., the proper chromedriver version for Chrome 115 is 115.0.5790.170) will likely remain the same in the short term. Therefore, the discovered versions are written in the metadata file and read from there instead of making the same consecutive network request. This way, during the driver version discovery (step 2 of the automated driver management process previously introduced), Selenium Manager first reads the file metadata. When a fresh resolution (i.e., a driver/browser version valid during a TTL) is found, that version is used (saving some time in making a new network request). If not found or the TTL has expired, a network request is made, and the result is stored in the metadata file.
Let’s consider an example. A Selenium binding asks Selenium Manager to resolve chromedriver. Selenium Manager detects that Chrome 115 is installed, so it makes a network request to the CfT endpoints to discover the proper chromedriver version (115.0.5790.170, at that moment). This version is stored in the metadata file and considered valid during the next hour (TTL). If Selenium Manager is asked to resolve chromedriver during that time (which is likely to happen in the execution of a test suite), the chromedriver version is discovered by reading the metadata file instead of making a new request to the CfT endpoints. After one hour, the chromedriver version stored in the cache will be considered as stale, and Selenium Manager will refresh it by making a new network request to the corresponding endpoint.
Selenium Manager includes two additional arguments two handle the cache, namely:
--clear-cache: To remove the cache folder (equivalent to the environment variable SE_CLEAR_CACHE=true).
--clear-metadata: To remove the metadata file (equivalent to the environment variable SE_CLEAR_METADATA=true).
Versioning
Selenium Manager follows the same versioning schema as Selenium. Nevertheless, we use the major version 0 for Selenium Manager releases because it is still in beta. For example, the Selenium Manager binaries shipped with Selenium 4.12.0 corresponds to version 0.4.12.
Getting Selenium Manager
For most users, direct interaction with Selenium Manager is not required since the Selenium bindings use it internally. Nevertheless, if you want to play with Selenium Manager or use it for your use case involving driver or browser management, you can get the Selenium Manager binaries in different ways:
From the Selenium repository. The Selenium Manager source code is stored in the main Selenium repo under the folder rust. Moreover, you can find the compiled versions for Windows, Linux, and macOS in the Selenium Manager Artifacts repo. The stable Selenium Manager binaries (i.e., those distributed in the latest stable Selenium version) are linked in this file.
From the build workflow. Selenium Manager is compiled using a GitHub Actions workflow. This workflow creates binaries for Windows, Linux, and macOS. You can download these binaries from these workflow executions.
From the cache. As of version 4.15.0 of the Selenium Java bindings, the Selenium Manager binary is extracted and copied to the cache folder. For instance, the Selenium Manager binary shipped with Selenium 4.15.0 is stored in the folder ~/.cache/selenium/manager/0.4.15).
Examples
Let’s consider a typical example: we want to manage chromedriver automatically. For that, we invoke Selenium Manager as follows (notice that the flag --debug is optional, but it helps us to understand what Selenium Manager is doing):
$ ./selenium-manager --browser chrome --debug
DEBUG chromedriver not found in PATH
DEBUG chrome detected at C:\Program Files\Google\Chrome\Application\chrome.exe
DEBUG Running command: wmic datafile where name='C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe' get Version /value
DEBUG Output: "\r\r\n\r\r\nVersion=116.0.5845.111\r\r\n\r\r\n\r\r\n\r"
DEBUG Detected browser: chrome 116.0.5845.111
DEBUG Discovering versions from https://googlechromelabs.github.io/chrome-for-testing/known-good-versions-with-downloads.json
DEBUG Required driver: chromedriver 116.0.5845.96
DEBUG Downloading chromedriver 116.0.5845.96 from https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/116.0.5845.96/win64/chromedriver-win64.zip
INFO Driver path: C:\Users\boni\.cache\selenium\chromedriver\win64\116.0.5845.96\chromedriver.exe
INFO Browser path: C:\Program Files\Google\Chrome\Application\chrome.exe
In this case, the local Chrome (in Windows) is detected by Selenium Manager. Then, using its version and the CfT endpoints, the proper chromedriver version (115, in this example) is downloaded to the local cache. Finally, Selenium Manager provides two results: i) the driver path (downloaded) and ii) the browser path (local).
Let’s consider another example. Now we want to use Chrome beta. Therefore, we invoke Selenium Manager specifying that version label as follows (notice that the CfT beta is discovered, downloaded, and stored in the local cache):
$ ./selenium-manager --browser chrome --browser-version beta --debug
DEBUG chromedriver not found in PATH
DEBUG chrome not found in PATH
DEBUG chrome beta not found in the system
DEBUG Discovering versions from https://googlechromelabs.github.io/chrome-for-testing/last-known-good-versions-with-downloads.json
DEBUG Required browser: chrome 117.0.5938.22
DEBUG Downloading chrome 117.0.5938.22 from https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/117.0.5938.22/win64/chrome-win64.zip
DEBUG chrome 117.0.5938.22 has been downloaded at C:\Users\boni\.cache\selenium\chrome\win64\117.0.5938.22\chrome.exe
DEBUG Discovering versions from https://googlechromelabs.github.io/chrome-for-testing/known-good-versions-with-downloads.json
DEBUG Required driver: chromedriver 117.0.5938.22
DEBUG Downloading chromedriver 117.0.5938.22 from https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/117.0.5938.22/win64/chromedriver-win64.zip
INFO Driver path: C:\Users\boni\.cache\selenium\chromedriver\win64\117.0.5938.22\chromedriver.exe
INFO Browser path: C:\Users\boni\.cache\selenium\chrome\win64\117.0.5938.22\chrome.exe
Selenium Manager allows you to configure the drivers automatically when setting up Selenium Grid. To that aim, you need to include the argument --selenium-manager true in the command to start Selenium Grid. For more details, visit the Selenium Grid starting page.
Moreover, Selenium Manager also allows managing Selenium Grid releases automatically. For that, the argument --grid is used as follows:
$ ./selenium-manager --grid
After this command, Selenium Manager discovers the latest version of Selenium Grid, storing the selenium-server.jar in the local cache.
Optionally, the argument --grid allows to specify a Selenium Grid version (--grid <GRID_VERSION>).
Known Limitations
Connectivity issues
Selenium Manager requests remote endpoints (like Chrome for Testing (CfT), among others) to discover and download drivers and browsers from online repositories. When this operation is done in a corporate environment with a proxy or firewall, it might lead to connectivity problems like the following:
error sending request for url (https://googlechromelabs.github.io/chrome-for-testing/known-good-versions-with-downloads.json)
error trying to connect: dns error: failed to lookup address information
error trying to connect: An existing connection was forcibly closed by the remote host. (os error 10054)
When that happens, consider the following solutions:
Use the proxy capabilities of Selenium (see documentation). Alternatively, use the environment variable SE_PROXY to set the proxy URL or use the configuration file (see configuration).
Review your network setup to enable the remote requests and downloads required by Selenium Manager.
Custom package managers
If you are using a Linux package manager (Anaconda, snap, etc) that requires a specific driver be used for your browsers,
you’ll need to either specify the
driver location,
the browser location,
or both, depending on the requirements.
Alternative architectures
Selenium supports all five architectures managed by Google’s Chrome for Testing, and all six drivers provided for Microsoft Edge.
Each release of the Selenium bindings comes with three separate Selenium Manager binaries — one for Linux, Windows, and Mac.
The Mac version supports both x64 and aarch64 (Intel and Apple).
The Windows version should work for both x86 and x64 (32-bit and 64-bit OS).
The Linux version has only been verified to work for x64.
Reasons for not supporting more architectures:
Neither Chrome for Testing nor Microsoft Edge supports additional architectures, so Selenium Manager would need to
manage something unofficial for it to work.
We currently build the binaries from existing GitHub actions runners, which do not support these architectures
Any additional architectures would get distributed with all Selenium releases, increasing the total build size
If you are running Linux on arm64/aarch64, 32-bit architecture, or a Raspberry Pi, Selenium Manager will not work for you.
The biggest issue for people is that they used to get custom-built drivers and put them on PATH and have them work.
Now that Selenium Manager is responsible for locating drivers on PATH, this approach no longer works, and users
need to use a Service class and set the location directly.
There are a number of advantages to having Selenium Manager look for drivers on PATH instead of managing that logic
in each of the bindings, so that’s currently a trade-off we are comfortable with.
However, as of Selenium 4.13.0, the Selenium bindings allow locating the Selenium Manager binary using an environment variable called SE_MANAGER_PATH. If this variable is set, the bindings will use its value as the Selenium Manager path in the local filesystem. This feature will allow users to provide a custom compilation of Selenium Manager, for instance, if the default binaries (compiled for Windows, Linux, and macOS) are incompatible with a given system (e.g., ARM64 in Linux).
Browser dependencies
When automatically managing browsers in Linux, Selenium Manager relies on the releases published by the browser vendors (i.e., Chrome, Firefox, and Edge). These releases are portable in most cases. Nevertheless, there might be cases in which existing libraries are required. In Linux, this problem might be experienced when trying to run Firefox, e.g., as follows:
libdbus-glib-1.so.2: cannot open shared object file: No such file or directory
Couldn't load XPCOM.
If that happens, the solution is to install that library, for instance, as follows:
sudo apt-get install libdbus-glib-1-2
A similar issue might happen when trying to execute Chrome for Testing in Linux:
error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory
In this case, the library to be installed is the following:
sudo apt-get install libatk-bridge2.0-0
Using an environment variable for the driver path
It’s possible to use an environment variable to specify the driver path without using Selenium Manager.
The following environment variables are supported:
SE_CHROMEDRIVER
SE_EDGEDRIVER
SE_GECKODRIVER
SE_IEDRIVER
SE_SAFARIDRIVER
For example, to specify the path to the chromedriver,
you can set the SE_CHROMEDRIVER environment variable to the path of the chromedriver executable.
The following bindings allow you to specify the driver path using an environment variable:
Ruby
Java
Python
This feature is available in the Selenium Ruby binding starting from version 4.25.0 and in the Python binding from version 4.26.0.
Building a Custom Selenium Manager
In order to build your own custom Selenium Manager that works in an architecture we don’t currently support, you can
utilize the following steps:
Install Rust Dev Environment
clone Selenium onto your local machine git clone https://github.com/SeleniumHQ/selenium.git --depth 1
Navigate into your clone cd selenium/rust
Build selenium cargo build --release
Set the following environment variable for the driver path SE_MANAGER_PATH=~/selenium/rust/target/release/selenium-manager
Put the driver you want in a location on your system PATH
Selenium will now use the built Selenium Manager to locate the manually downloaded driver on PATH
ChromeOptionschromeOptions=newChromeOptions();chromeOptions.setCapability("browserVersion","100");chromeOptions.setCapability("platformName","Windows");// Showing a test name instead of the session id in the Grid UIchromeOptions.setCapability("se:name","My simple test");// Other type of metadata can be seen in the Grid UI by clicking on the// session info or via GraphQLchromeOptions.setCapability("se:sampleMetadata","Sample metadata value");WebDriverdriver=newRemoteWebDriver(newURL("http://gridUrl:4444"),chromeOptions);driver.get("http://www.google.com");driver.quit();
Selenium Grid のクエリ
Grid 起動後、ステータスを問い合わせる方法は、
Grid UI と API 呼び出しの主に 2 通りあります。
ノードは受信したコマンドを実行するだけで、コマンドの評価・判断や、フロー制御以外の制御は行いません。
ノードが実行されているマシンは、他のコンポーネントと同じ OS を持つ必要はありません。
たとえば、Windows ノードには IE Mode on Edge をブラウザーオプションとして提供する機能がありますが、
これは Linux または Mac では不可能です。
Grid は 複数の Windows, Mac, Linux ノードで構成することが可能です。
The Distributor uses a fixed-sized thread pool to create new sessions as it consumes new session requests from the queue. This allows configuring the size of the thread pool. The default value is no. of available processors * 3. Note: If the no. of threads is way greater than the available processors it will not always increase the performance. A high number of threads causes more context switching which is an expensive operation.
--purge-nodes-interval
int
30
How often, in seconds, will the Distributor purge Nodes that have been down for a while. This is calculated based on the heartbeat received from a particular node.
Specify which docker host configuration keys should be passed to browser containers. Keys name can be found in the Docker API documentation, or by running docker inspect the node-docker container.
How often, in seconds, will the the SessionQueue response in case there is no data, to reduce the http requests while polling for new session requests.
The Grid infrastructure will try to match a session request with "se:downloadsEnabled" against ONLY those nodes which were started with --enable-managed-downloads true
If a session is matched, then the Node automatically sets the required capabilities to let the browser know, as to where should a file be downloaded.
The Node now allows a user to:
List all the files that were downloaded for a specific session and
Retrieve a specific file from the list of files.
The directory into which files were downloaded for a specific session gets automatically cleaned up when the session ends (or) timesout due to inactivity.
Note: Currently this capability is ONLY supported on:
Edge
Firefox and
Chrome browser
Listing files that can be downloaded for current session:
The endpoint to GET from is /session/<sessionId>/se/files.
The session needs to be active in order for the command to work.
contents - Base64 encoded zipped contents of the file.
The file contents are Base64 encoded and they need to be unzipped.
List files that can be downloaded
The below mentioned curl example can be used to list all the files that were downloaded by the current session in the Node, and which can be retrieved locally.
curl -X GET "http://localhost:4444/session/90c0149a-2e75-424d-857a-e78734943d4c/se/files"
Below is an example in Java that does the following:
Sets the capability to indicate that the test requires automatic managing of downloaded files.
Triggers a file download via a browser.
Lists the files that are available for retrieval from the remote node (These are essentially files that were downloaded in the current session)
Picks one file and downloads the file from the remote node to the local machine.
importcom.google.common.collect.ImmutableMap;importorg.openqa.selenium.By;importorg.openqa.selenium.io.Zip;importorg.openqa.selenium.json.Json;importorg.openqa.selenium.remote.RemoteWebDriver;importorg.openqa.selenium.remote.http.HttpClient;importorg.openqa.selenium.remote.http.HttpRequest;importorg.openqa.selenium.remote.http.HttpResponse;importjava.io.File;importjava.net.URL;importjava.nio.file.Files;importjava.util.List;importjava.util.Map;importjava.util.Optional;importjava.util.concurrent.TimeUnit;import staticorg.openqa.selenium.remote.http.Contents.asJson;import staticorg.openqa.selenium.remote.http.Contents.string;import staticorg.openqa.selenium.remote.http.HttpMethod.GET;import staticorg.openqa.selenium.remote.http.HttpMethod.POST;publicclassDownloadsSample{publicstaticvoidmain(String[]args)throwsException{// Assuming the Grid is running locally.URLgridUrl=newURL("http://localhost:4444");ChromeOptionsoptions=newChromeOptions();options.setCapability("se:downloadsEnabled",true);RemoteWebDriverdriver=newRemoteWebDriver(gridUrl,options);try{demoFileDownloads(driver,gridUrl);}finally{driver.quit();}}privatestaticvoiddemoFileDownloads(RemoteWebDriverdriver,URLgridUrl)throwsException{driver.get("https://www.selenium.dev/selenium/web/downloads/download.html");// Download the two available files on the pagedriver.findElement(By.id("file-1")).click();driver.findElement(By.id("file-2")).click();// The download happens in a remote Node, which makes it difficult to know when the file// has been completely downloaded. For demonstration purposes, this example uses a// 10-second sleep which should be enough time for a file to be downloaded.// We strongly recommend to avoid hardcoded sleeps, and ideally, to modify your// application under test, so it offers a way to know when the file has been completely// downloaded.TimeUnit.SECONDS.sleep(10);//This is the endpoint which will provide us with list of files to download and also to//let us download a specific file.StringdownloadsEndpoint=String.format("/session/%s/se/files",driver.getSessionId());StringfileToDownload;try(HttpClientclient=HttpClient.Factory.createDefault().createClient(gridUrl)){// To list all files that are were downloaded on the remote node for the current session// we trigger GET request.HttpRequestrequest=newHttpRequest(GET,downloadsEndpoint);HttpResponseresponse=client.execute(request);Map<String,Object>jsonResponse=newJson().toType(string(response),Json.MAP_TYPE);@SuppressWarnings("unchecked")Map<String,Object>value=(Map<String,Object>)jsonResponse.get("value");@SuppressWarnings("unchecked")List<String>names=(List<String>)value.get("names");// Let's say there were "n" files downloaded for the current session, we would like// to retrieve ONLY the first file.fileToDownload=names.get(0);}// Now, let's download the filetry(HttpClientclient=HttpClient.Factory.createDefault().createClient(gridUrl)){// To retrieve a specific file from one or more files that were downloaded by the current session// on a remote node, we use a POST request.HttpRequestrequest=newHttpRequest(POST,downloadsEndpoint);request.setContent(asJson(ImmutableMap.of("name",fileToDownload)));HttpResponseresponse=client.execute(request);Map<String,Object>jsonResponse=newJson().toType(string(response),Json.MAP_TYPE);@SuppressWarnings("unchecked")Map<String,Object>value=(Map<String,Object>)jsonResponse.get("value");// The returned map would contain 2 keys,// filename - This represents the name of the file (same as what was provided by the test)// contents - Base64 encoded String which contains the zipped file.StringzippedContents=value.get("contents").toString();// The file contents would always be a zip file and has to be unzipped.FiledownloadDir=Zip.unzipToTempDir(zippedContents,"download","");// Read the file contentsFiledownloadedFile=Optional.ofNullable(downloadDir.listFiles()).orElse(newFile[]{})[0];StringfileContent=String.join("",Files.readAllLines(downloadedFile.toPath()));System.out.println("The file which was "+"downloaded in the node is now available in the directory: "+downloadDir.getAbsolutePath()+" and has the contents: "+fileContent);}}}
[node]detect-drivers=falsemax-sessions=2[docker]configs=["selenium/standalone-chrome:93.0","{\"browserName\": \"chrome\", \"browserVersion\": \"91\"}","selenium/standalone-firefox:92.0","{\"browserName\": \"firefox\", \"browserVersion\": \"92\"}"]#Optionally define all device files that should be mapped to docker containers#devices = [# "/dev/kvm:/dev/kvm"#]url="http://localhost:2375"video-image="selenium/video:latest"
[node]detect-drivers=false[relay]# Default Appium/Cloud server endpointurl="http://localhost:4723/wd/hub"status-endpoint="/status"# Optional, enforce a specific protocol version in HttpClient when communicating with the endpoint service status (e.g. HTTP/1.1, HTTP/2)protocol-version="HTTP/1.1"# Stereotypes supported by the service. The initial number is "max-sessions", and will allocate# that many test slots to that particular configurationconfigs=["5","{\"browserName\": \"chrome\", \"platformName\": \"android\", \"appium:platformVersion\": \"11\"}"]
The Node can be instructed to manage downloads automatically. This will cause the Node to save all files that were downloaded for a particular session into a temp directory, which can later be retrieved from the node.
To turn this capability on, use the below configuration:
コンソール - すべてのトレースと、それに含まれるスパンを FINE レベルでログに出力します。デフォルトでは、Selenium サーバーは INFO レベル以上のログを出力します。
log-level フラグを使うと、Selenium Grid jar を実行する際に任意のログレベルを指定することができます。
java -jar selenium-server-4.0.0-<selenium-version>.jar standalone --log-level FINE
Jaeger UI - OpenTelemetry は、コード内のトレースを計測するための API と SDK を提供します。一方、Jaeger はトレースのバックエンドで、トレースのテレメトリデータを収集し、データのクエリ、フィルタリング、ビジュアライズの機能を提供します。
cURL --request GET 'http://localhost:4444/se/grid/newsessionqueue/queue'
完全分散モードでは、キューの URL は 新規セッションキューのアドレスになります。
cURL --request GET 'http://localhost:4444/se/grid/newsessionqueue/queue'
4.6.4 - Customizing a Node
Page being translated from
English to Japanese. Do you speak Japanese? Help us to translate
it by sending us pull requests!
How to customize a Node
There are times when we would like a Node to be customized to our needs.
For e.g., we may like to do some additional setup before a session begins execution and some clean-up after a session runs to completion.
Following steps can be followed for this:
Create a class that extends org.openqa.selenium.grid.node.Node
Add a static method (this will be our factory method) to the newly created class whose signature looks like this:
public static Node create(Config config). Here:
Node is of type org.openqa.selenium.grid.node.Node
Config is of type org.openqa.selenium.grid.config.Config
Within this factory method, include logic for creating your new Class.
To wire in this new customized logic into the hub, start the node and pass in the fully qualified class name of the above class to the argument --node-implementation
Let’s see an example of all this:
Custom Node as an uber jar
Create a sample project using your favourite build tool (Maven|Gradle).
Note: If you are using Maven as a build tool, please prefer using maven-shade-plugin instead of maven-assembly-plugin because maven-assembly plugin seems to have issues with being able to merge multiple Service Provider Interface files (META-INF/services)
Custom Node as a regular jar
Create a sample project using your favourite build tool (Maven|Gradle).
Below is a sample that just prints some messages on to the console whenever there’s an activity of interest (session created, session deleted, a webdriver command executed etc.,) on the Node.
Sample customized node
packageorg.seleniumhq.samples;importjava.net.URI;importjava.util.UUID;importorg.openqa.selenium.Capabilities;importorg.openqa.selenium.NoSuchSessionException;importorg.openqa.selenium.WebDriverException;importorg.openqa.selenium.grid.config.Config;importorg.openqa.selenium.grid.data.CreateSessionRequest;importorg.openqa.selenium.grid.data.CreateSessionResponse;importorg.openqa.selenium.grid.data.NodeId;importorg.openqa.selenium.grid.data.NodeStatus;importorg.openqa.selenium.grid.data.Session;importorg.openqa.selenium.grid.log.LoggingOptions;importorg.openqa.selenium.grid.node.HealthCheck;importorg.openqa.selenium.grid.node.Node;importorg.openqa.selenium.grid.node.local.LocalNodeFactory;importorg.openqa.selenium.grid.security.Secret;importorg.openqa.selenium.grid.security.SecretOptions;importorg.openqa.selenium.grid.server.BaseServerOptions;importorg.openqa.selenium.internal.Either;importorg.openqa.selenium.remote.SessionId;importorg.openqa.selenium.remote.http.HttpRequest;importorg.openqa.selenium.remote.http.HttpResponse;importorg.openqa.selenium.remote.tracing.Tracer;publicclassDecoratedLoggingNodeextendsNode{privateNodenode;protectedDecoratedLoggingNode(Tracertracer,NodeIdnodeId,URIuri,SecretregistrationSecret,DurationsessionTimeout){super(tracer,nodeId,uri,registrationSecret,sessionTimeout);}publicstaticNodecreate(Configconfig){LoggingOptionsloggingOptions=newLoggingOptions(config);BaseServerOptionsserverOptions=newBaseServerOptions(config);URIuri=serverOptions.getExternalUri();SecretOptionssecretOptions=newSecretOptions(config);NodeOptionsnodeOptions=newNodeOptions(config);DurationsessionTimeout=nodeOptions.getSessionTimeout();// Refer to the foot notes for additional context on this line.Nodenode=LocalNodeFactory.create(config);DecoratedLoggingNodewrapper=newDecoratedLoggingNode(loggingOptions.getTracer(),node.getId(),uri,secretOptions.getRegistrationSecret(),sessionTimeout);wrapper.node=node;returnwrapper;}@OverridepublicEither<WebDriverException,CreateSessionResponse>newSession(CreateSessionRequestsessionRequest){System.out.println("Before newSession()");try{returnthis.node.newSession(sessionRequest);}finally{System.out.println("After newSession()");}}@OverridepublicHttpResponseexecuteWebDriverCommand(HttpRequestreq){try{System.out.println("Before executeWebDriverCommand(): "+req.getUri());returnnode.executeWebDriverCommand(req);}finally{System.out.println("After executeWebDriverCommand()");}}@OverridepublicSessiongetSession(SessionIdid)throwsNoSuchSessionException{try{System.out.println("Before getSession()");returnnode.getSession(id);}finally{System.out.println("After getSession()");}}@OverridepublicHttpResponseuploadFile(HttpRequestreq,SessionIdid){try{System.out.println("Before uploadFile()");returnnode.uploadFile(req,id);}finally{System.out.println("After uploadFile()");}}@Overridepublicvoidstop(SessionIdid)throwsNoSuchSessionException{try{System.out.println("Before stop()");node.stop(id);}finally{System.out.println("After stop()");}}@OverridepublicbooleanisSessionOwner(SessionIdid){try{System.out.println("Before isSessionOwner()");returnnode.isSessionOwner(id);}finally{System.out.println("After isSessionOwner()");}}@OverridepublicbooleanisSupporting(Capabilitiescapabilities){try{System.out.println("Before isSupporting");returnnode.isSupporting(capabilities);}finally{System.out.println("After isSupporting()");}}@OverridepublicNodeStatusgetStatus(){try{System.out.println("Before getStatus()");returnnode.getStatus();}finally{System.out.println("After getStatus()");}}@OverridepublicHealthCheckgetHealthCheck(){try{System.out.println("Before getHealthCheck()");returnnode.getHealthCheck();}finally{System.out.println("After getHealthCheck()");}}@Overridepublicvoiddrain(){try{System.out.println("Before drain()");node.drain();}finally{System.out.println("After drain()");}}@OverridepublicbooleanisReady(){try{System.out.println("Before isReady()");returnnode.isReady();}finally{System.out.println("After isReady()");}}}
Foot Notes:
In the above example, the line Node node = LocalNodeFactory.create(config); explicitly creates a LocalNode.
There are basically 2 types of user facing implementations of org.openqa.selenium.grid.node.Node available.
These classes are good starting points to learn how to build a custom Node and also to learn the internals of a Node.
org.openqa.selenium.grid.node.local.LocalNode - Used to represent a long running Node and is the default implementation that gets wired in when you start a node.
It can be created by calling LocalNodeFactory.create(config);, where:
LocalNodeFactory belongs to org.openqa.selenium.grid.node.local
Config belongs to org.openqa.selenium.grid.config
org.openqa.selenium.grid.node.k8s.OneShotNode - This is a special reference implementation wherein the Node gracefully shuts itself down after servicing one test session. This class is currently not available as part of any pre-built maven artifact.
You can refer to the source code here to understand its internals.
Selenium Grid allows you to persist information related to currently running sessions into an external data store.
The external data store could be backed by your favourite database (or) Redis Cache system.
Setup
Coursier - As a dependency resolver, so that we can download maven artifacts on the fly and make them available in our classpath
Docker - To manage our PostGreSQL/Redis docker containers.
Database backed Session Map
For the sake of this illustration, we are going to work with PostGreSQL database.
We will spin off a PostGreSQL database as a docker container using a docker compose file.
Steps
You can skip this step if you already have a PostGreSQL database instance available at your disposal.
Create a sql file named init.sql with the below contents:
We can now start our database container by running:
docker-compose up -d
Our database name is selenium_sessions with its username and password set to seluser
If you are working with an already running PostGreSQL DB instance, then you just need to create a database named selenium_sessions and the table sessions_map using the above mentioned SQL statement.
Create a Selenium Grid configuration file named sessions.toml with the below contents:
At this point the current directory should contain the following files:
docker-compose.yml
init.sql
sessions.toml
distributed.sh
You can now spawn the Grid by running distributed.sh shell script and quickly run a test. You will notice that the Grid now stores session information into the PostGreSQL database.
In the line which spawns a SessionMap on a machine:
At this point the current directory should contain the following files:
docker-compose.yml
sessions.toml
distributed.sh
You can now spawn the Grid by running distributed.sh shell script and quickly run a test. You will notice that the Grid now stores session information into the Redis instance. You can perhaps make use of a Redis GUI such as TablePlus to see them (Make sure that you have setup a debug point in your test, because the values will get deleted as soon as the test runs to completion).
In the line which spawns a SessionMap on a machine:
We use the W3C WebDriver protocol to communicate with a local instance of an HTTP server. This greatly simplifies the implementation of the language-specific code, and minimzes the number of entry points into the C++ DLL that must be called using a native-code interop technology such as JNA, ctypes, pinvoke or DL.
Memory Management
The IE driver utilizes the Active Template Library (ATL) to take advantage of its implementation of smart pointers to COM objects. This makes reference counting and cleanup of COM objects much easier.
Why Do We Require Protected Mode Settings Changes?
IE 7 on Windows Vista introduced the concept of Protected Mode, which allows for some measure of protection to the underlying Windows OS when browsing. The problem is that when you manipulate an instance of IE via COM, and you navigate to a page that would cause a transition into or out of Protected Mode, IE requires that another browser session be created. This will orphan the COM object of the previous session, not allowing you to control it any longer.
In IE 7, this will usually manifest itself as a new top-level browser window; in IE 8, a new IExplore.exe process will be created, but it will usually (not always!) seamlessly attach it to the existing IE top-level frame window. Any browser automation framework that drives IE externally (as opposed to using a WebBrowser control) will run into these problems.
In order to work around that problem, we dictate that to work with IE, all zones must have the same Protected Mode setting. As long as it’s on for all zones, or off for all zones, we can prevent the transistions to different Protected Mode zones that would invalidate our browser object. It also allows users to continue to run with UAC turned on, and to run securely in the browser if they set Protected Mode “on” for all zones.
In earlier releases of the IE driver, if the user’s Protected Mode settings were not correctly set, we would launch IE, and the process would simply hang until the HTTP request timed out. This was suboptimal, as it gave no indication what needed to be set. Erring on the side of caution, we do not modify the user’s Protected Mode settings. Current versions, however check that the Protected Mode settings are properly set, and will return an error response if they are not.
There are two ways that we could simulate keyboard and mouse input. The first way, which is used in parts of webdriver, is to synthesize events on the DOM. This has a number of drawbacks, since each browser (and version of a browser) has its own unique quirks; to model each of these is a demanding task, and impossible to get completely right (for example, it’s hard to tell what window.selection should be and this is a read-only property on some browsers) The alternative approach is to synthesize keyboard and mouse input at the OS level, ideally without stealing focus from the user (who tends to be doing other things on their computer as long-running webdriver tests run)
The code for doing this is in interactions.cpp The key thing to note here is that we use PostMessages to push window events on to the message queue of the IE instance. Typing, in particular, is interesting: we only send the “keydown” and “keyup” messages. The “keypress” event is created if necessary by IE’s internal event processing. Because the key press event is not always generated (for example, not every character is printable, and if the default event bubbling is cancelled, listeners don’t see the key press event) we send a “probe” event in after the key down. Once we see that this has been processed, we know that the key press event is on the stack of events to be processed, and that it is safe to send the key up event. If this was not done, it is possible for events to fire in the wrong order, which is definitely sub-optimal.
Working On the InternetExplorerDriver
Currently, there are tests that will run for the InternetExplorerDriver in all languages (Java, C#, Python, and Ruby), so you should be able to test your changes to the native code no matter what language you’re comfortable working in from the client side. For working on the C++ code, you’ll need Visual Studio 2010 Professional or higher. Unfortunately, the C++ code of the driver uses ATL to ease the pain of working with COM objects, and ATL is not supplied with Visual C++ 2010 Express Edition. If you’re using Eclipse, the process for making and testing modifications is:
Edit the C++ code in VS.
Build the code to ensure that it compiles
Do a complete rebuild when you are ready to run a test. This will cause the created DLL to be copied to the right place to allow its use in Eclipse
Load Eclipse (or some other IDE, such as Idea)
Edit the SingleTestSuite so that it is usingDriver(IE)
Create a JUnit run configuration that uses the “webdriver-internet-explorer” project. If you don’t do this, the test won’t work at all, and there will be a somewhat cryptic error message on the console.
Once the basic setup is done, you can start working on the code pretty quickly. You can attach to the process you execute your code from using Visual Studio (from the Debug menu, select Attach to Process…).
6 - Selenium IDE
Selenium IDEは、ユーザーのアクションを記録および再生するブラウザー拡張機能です。
Seleniumの統合開発環境(Selenium IDE)は、
各要素のコンテキストによって定義されたパラメーターを使用して、
既存のSeleniumコマンドを使用してブラウザーでのユーザーのアクションを記録する、使いやすいブラウザー拡張機能です。
これは、Seleniumの構文を学習するための優れた方法を提供します。
Google Chrome、Mozilla Firefox、およびMicrosoftEdgeで利用できます。
@Overrideprotectedvoidload(){driver.get("https://github.com/SeleniumHQ/selenium/issues/new?assignees=&labels=I-defect%2Cneeds-triaging&projects=&template=bug-report.yml&title=%5B%F0%9F%90%9B+Bug%5D%3A+");}@OverrideprotectedvoidisLoaded()throwsError{Stringurl=driver.getCurrentUrl();assertTrue("Not on the issue entry page: "+url,url.endsWith("/new"));}
packagecom.example.webdriver;importorg.openqa.selenium.By;importorg.openqa.selenium.WebDriver;importorg.openqa.selenium.WebElement;importorg.openqa.selenium.support.FindBy;importorg.openqa.selenium.support.PageFactory;import staticjunit.framework.Assert.assertTrue;publicclassEditIssueextendsLoadableComponent<EditIssue>{privatefinalWebDriverdriver;// By default the PageFactory will locate elements with the same name or id// as the field. Since the issue_title element has an id attribute of "issue_title"// we don't need any additional annotations.privateWebElementissue_title;// But we'd prefer a different name in our code than "issue_body", so we use the// FindBy annotation to tell the PageFactory how to locate the element.@FindBy(id="issue_body")privateWebElementbody;publicEditIssue(WebDriverdriver){this.driver=driver;// This call sets the WebElement fields.PageFactory.initElements(driver,this);}@Overrideprotectedvoidload(){driver.get("https://github.com/SeleniumHQ/selenium/issues/new?assignees=&labels=I-defect%2Cneeds-triaging&projects=&template=bug-report.yml&title=%5B%F0%9F%90%9B+Bug%5D%3A+");}@OverrideprotectedvoidisLoaded()throwsError{Stringurl=driver.getCurrentUrl();assertTrue("Not on the issue entry page: "+url,url.endsWith("/new"));}publicvoidsetHowToReproduce(StringhowToReproduce){WebElementfield=driver.findElement(By.id("issue_form_repro-command"));clearAndType(field,howToReproduce);}publicvoidsetLogOutput(StringlogOutput){WebElementfield=driver.findElement(By.id("issue_form_logs"));clearAndType(field,logOutput);}publicvoidsetOperatingSystem(StringoperatingSystem){WebElementfield=driver.findElement(By.id("issue_form_operating-system"));clearAndType(field,operatingSystem);}publicvoidsetSeleniumVersion(StringseleniumVersion){WebElementfield=driver.findElement(By.id("issue_form_selenium-version"));clearAndType(field,logOutput);}publicvoidsetBrowserVersion(StringbrowserVersion){WebElementfield=driver.findElement(By.id("issue_form_browser-versions"));clearAndType(field,browserVersion);}publicvoidsetDriverVersion(StringdriverVersion){WebElementfield=driver.findElement(By.id("issue_form_browser-driver-versions"));clearAndType(field,driverVersion);}publicvoidsetUsingGrid(StringusingGrid){WebElementfield=driver.findElement(By.id("issue_form_selenium-grid-version"));clearAndType(field,usingGrid);}publicIssueListsubmit(){driver.findElement(By.cssSelector("button[type='submit']")).click();returnnewIssueList(driver);}privatevoidclearAndType(WebElementfield,Stringtext){field.clear();field.sendKeys(text);}}
packagecom.example.webdriver;importorg.openqa.selenium.By;importorg.openqa.selenium.NoSuchElementException;importorg.openqa.selenium.WebDriver;importorg.openqa.selenium.WebElement;import staticorg.junit.Assert.fail;publicclassSecuredPageextendsLoadableComponent<SecuredPage>{privatefinalWebDriverdriver;privatefinalLoadableComponent<?>parent;privatefinalStringusername;privatefinalStringpassword;publicSecuredPage(WebDriverdriver,LoadableComponent<?>parent,Stringusername,Stringpassword){this.driver=driver;this.parent=parent;this.username=username;this.password=password;}@Overrideprotectedvoidload(){parent.get();StringoriginalUrl=driver.getCurrentUrl();// Sign indriver.get("https://www.google.com/accounts/ServiceLogin?service=code");driver.findElement(By.name("Email")).sendKeys(username);WebElementpasswordField=driver.findElement(By.name("Passwd"));passwordField.sendKeys(password);passwordField.submit();// Now return to the original URLdriver.get(originalUrl);}@OverrideprotectedvoidisLoaded()throwsError{// If you're signed in, you have the option of picking a different login.// Let's check for the presence of that.try{WebElementdiv=driver.findElement(By.id("multilogin-dropdown"));}catch(NoSuchElementExceptione){fail("Cannot locate user name link");}}}
publicclassActionBot{privatefinalWebDriverdriver;publicActionBot(WebDriverdriver){this.driver=driver;}publicvoidclick(Bylocator){driver.findElement(locator).click();}publicvoidsubmit(Bylocator){driver.findElement(locator).submit();}/**
* Type something into an input field. WebDriver doesn't normally clear these
* before typing, so this method does that first. It also sends a return key
* to move the focus out of the element.
*/publicvoidtype(Bylocator,Stringtext){WebElementelement=driver.findElement(locator);element.clear();element.sendKeys(text+"\n");}}
// Create a user who has read-only permissions--they can configure a unicorn,// but they do not have payment information set up, nor do they have// administrative privileges. At the time the user is created, its email// address and password are randomly generated--you don't even need to// know them.Useruser=UserFactory.createCommonUser();//This method is defined elsewhere.// Log in as this user.// Logging in on this site takes you to your personal "My Account" page, so the// AccountPage object is returned by the loginAs method, allowing you to then// perform actions from the AccountPage.AccountPageaccountPage=loginAs(user.getEmail(),user.getPassword());
# Create a user who has read-only permissions--they can configure a unicorn,# but they do not have payment information set up, nor do they have# administrative privileges. At the time the user is created, its email# address and password are randomly generated--you don't even need to# know them.user=user_factory.create_common_user()#This method is defined elsewhere.# Log in as this user.# Logging in on this site takes you to your personal "My Account" page, so the# AccountPage object is returned by the loginAs method, allowing you to then# perform actions from the AccountPage.account_page=login_as(user.get_email(),user.get_password())
// Create a user who has read-only permissions--they can configure a unicorn,// but they do not have payment information set up, nor do they have// administrative privileges. At the time the user is created, its email// address and password are randomly generated--you don't even need to// know them.Useruser=UserFactory.CreateCommonUser();//This method is defined elsewhere.// Log in as this user.// Logging in on this site takes you to your personal "My Account" page, so the// AccountPage object is returned by the loginAs method, allowing you to then// perform actions from the AccountPage.AccountPageaccountPage=LoginAs(user.Email,user.Password);
# Create a user who has read-only permissions--they can configure a unicorn,# but they do not have payment information set up, nor do they have# administrative privileges. At the time the user is created, its email# address and password are randomly generated--you don't even need to# know them.user=UserFactory.create_common_user#This method is defined elsewhere.# Log in as this user.# Logging in on this site takes you to your personal "My Account" page, so the# AccountPage object is returned by the loginAs method, allowing you to then# perform actions from the AccountPage.account_page=login_as(user.email,user.password)
// Create a user who has read-only permissions--they can configure a unicorn,
// but they do not have payment information set up, nor do they have
// administrative privileges. At the time the user is created, its email
// address and password are randomly generated--you don't even need to
// know them.
varuser=userFactory.createCommonUser();//This method is defined elsewhere.
// Log in as this user.
// Logging in on this site takes you to your personal "My Account" page, so the
// AccountPage object is returned by the loginAs method, allowing you to then
// perform actions from the AccountPage.
varaccountPage=loginAs(user.email,user.password);
// Create a user who has read-only permissions--they can configure a unicorn,
// but they do not have payment information set up, nor do they have
// administrative privileges. At the time the user is created, its email
// address and password are randomly generated--you don't even need to
// know them.
valuser=UserFactory.createCommonUser()//This method is defined elsewhere.
// Log in as this user.
// Logging in on this site takes you to your personal "My Account" page, so the
// AccountPage object is returned by the loginAs method, allowing you to then
// perform actions from the AccountPage.
valaccountPage=loginAs(user.getEmail(),user.getPassword())
// The Unicorn is a top-level Object--it has attributes, which are set here. // This only stores the values; it does not fill out any web forms or interact// with the browser in any way.Unicornsparkles=newUnicorn("Sparkles",UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS);// Since we are already "on" the account page, we have to use it to get to the// actual place where you configure unicorns. Calling the "Add Unicorn" method// takes us there.AddUnicornPageaddUnicornPage=accountPage.addUnicorn();// Now that we're on the AddUnicornPage, we will pass the "sparkles" object to// its createUnicorn() method. This method will take Sparkles' attributes,// fill out the form, and click submit.UnicornConfirmationPageunicornConfirmationPage=addUnicornPage.createUnicorn(sparkles);
# The Unicorn is a top-level Object--it has attributes, which are set here.# This only stores the values; it does not fill out any web forms or interact# with the browser in any way.sparkles=Unicorn("Sparkles",UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS)# Since we're already "on" the account page, we have to use it to get to the# actual place where you configure unicorns. Calling the "Add Unicorn" method# takes us there.add_unicorn_page=account_page.add_unicorn()# Now that we're on the AddUnicornPage, we will pass the "sparkles" object to# its createUnicorn() method. This method will take Sparkles' attributes,# fill out the form, and click submit.unicorn_confirmation_page=add_unicorn_page.create_unicorn(sparkles)
// The Unicorn is a top-level Object--it has attributes, which are set here. // This only stores the values; it does not fill out any web forms or interact// with the browser in any way.Unicornsparkles=newUnicorn("Sparkles",UnicornColors.Purple,UnicornAccessories.Sunglasses,UnicornAdornments.StarTattoos);// Since we are already "on" the account page, we have to use it to get to the// actual place where you configure unicorns. Calling the "Add Unicorn" method// takes us there.AddUnicornPageaddUnicornPage=accountPage.AddUnicorn();// Now that we're on the AddUnicornPage, we will pass the "sparkles" object to// its createUnicorn() method. This method will take Sparkles' attributes,// fill out the form, and click submit.UnicornConfirmationPageunicornConfirmationPage=addUnicornPage.CreateUnicorn(sparkles);
# The Unicorn is a top-level Object--it has attributes, which are set here.# This only stores the values; it does not fill out any web forms or interact# with the browser in any way.sparkles=Unicorn.new('Sparkles',UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS)# Since we're already "on" the account page, we have to use it to get to the# actual place where you configure unicorns. Calling the "Add Unicorn" method# takes us there.add_unicorn_page=account_page.add_unicorn# Now that we're on the AddUnicornPage, we will pass the "sparkles" object to# its createUnicorn() method. This method will take Sparkles' attributes,# fill out the form, and click submit.unicorn_confirmation_page=add_unicorn_page.create_unicorn(sparkles)
// The Unicorn is a top-level Object--it has attributes, which are set here.
// This only stores the values; it does not fill out any web forms or interact
// with the browser in any way.
varsparkles=newUnicorn("Sparkles",UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS);// Since we are already "on" the account page, we have to use it to get to the
// actual place where you configure unicorns. Calling the "Add Unicorn" method
// takes us there.
varaddUnicornPage=accountPage.addUnicorn();// Now that we're on the AddUnicornPage, we will pass the "sparkles" object to
// its createUnicorn() method. This method will take Sparkles' attributes,
// fill out the form, and click submit.
varunicornConfirmationPage=addUnicornPage.createUnicorn(sparkles);
// The Unicorn is a top-level Object--it has attributes, which are set here.
// This only stores the values; it does not fill out any web forms or interact
// with the browser in any way.
valsparkles=Unicorn("Sparkles",UnicornColors.PURPLE,UnicornAccessories.SUNGLASSES,UnicornAdornments.STAR_TATTOOS)// Since we are already "on" the account page, we have to use it to get to the
// actual place where you configure unicorns. Calling the "Add Unicorn" method
// takes us there.
valaddUnicornPage=accountPage.addUnicorn()// Now that we're on the AddUnicornPage, we will pass the "sparkles" object to
// its createUnicorn() method. This method will take Sparkles' attributes,
// fill out the form, and click submit.
unicornConfirmationPage=addUnicornPage.createUnicorn(sparkles)
// The exists() method from UnicornConfirmationPage will take the Sparkles // object--a specification of the attributes you want to see, and compare// them with the fields on the page.Assert.assertTrue("Sparkles should have been created, with all attributes intact",unicornConfirmationPage.exists(sparkles));
# The exists() method from UnicornConfirmationPage will take the Sparkles# object--a specification of the attributes you want to see, and compare# them with the fields on the page.assertunicorn_confirmation_page.exists(sparkles),"Sparkles should have been created, with all attributes intact"
// The exists() method from UnicornConfirmationPage will take the Sparkles // object--a specification of the attributes you want to see, and compare// them with the fields on the page.Assert.True(unicornConfirmationPage.Exists(sparkles),"Sparkles should have been created, with all attributes intact");
# The exists() method from UnicornConfirmationPage will take the Sparkles# object--a specification of the attributes you want to see, and compare# them with the fields on the page.expect(unicorn_confirmation_page.exists?(sparkles)).tobe,'Sparkles should have been created, with all attributes intact'
// The exists() method from UnicornConfirmationPage will take the Sparkles
// object--a specification of the attributes you want to see, and compare
// them with the fields on the page.
assert(unicornConfirmationPage.exists(sparkles),"Sparkles should have been created, with all attributes intact");
// The exists() method from UnicornConfirmationPage will take the Sparkles
// object--a specification of the attributes you want to see, and compare
// them with the fields on the page.
assertTrue("Sparkles should have been created, with all attributes intact",unicornConfirmationPage.exists(sparkles))
Note: this page has merged contents from multiple sources, including
the Selenium wiki
Overview
Within your web app’s UI, there are areas where your tests interact with.
A Page Object only models these as objects within the test code.
This reduces the amount of duplicated code and means that if the UI changes,
the fix needs only to be applied in one place.
Page Object is a Design Pattern that has become popular in test automation for
enhancing test maintenance and reducing code duplication. A page object is an
object-oriented class that serves as an interface to a page of your AUT. The
tests then use the methods of this page object class whenever they need to
interact with the UI of that page. The benefit is that if the UI changes for
the page, the tests themselves don’t need to change, only the code within the
page object needs to change. Subsequently, all changes to support that new UI
are located in one place.
Advantages
There is a clean separation between the test code and page-specific code, such as
locators (or their use if you’re using a UI Map) and layout.
There is a single repository for the services or operations the page offers
rather than having these services scattered throughout the tests.
In both cases, this allows any modifications required due to UI changes to all
be made in one place. Helpful information on this technique can be found on
numerous blogs as this ‘test design pattern’ is becoming widely used. We
encourage readers who wish to know more to search the internet for blogs
on this subject. Many have written on this design pattern and can provide
helpful tips beyond the scope of this user guide. To get you started,
we’ll illustrate page objects with a simple example.
Examples
First, consider an example, typical of test automation, that does not use a
page object:
/***
* Tests login feature
*/publicclassLogin{publicvoidtestLogin(){// fill login data on sign-in pagedriver.findElement(By.name("user_name")).sendKeys("userName");driver.findElement(By.name("password")).sendKeys("my supersecret password");driver.findElement(By.name("sign-in")).click();// verify h1 tag is "Hello userName" after logindriver.findElement(By.tagName("h1")).isDisplayed();assertThat(driver.findElement(By.tagName("h1")).getText(),is("Hello userName"));}}
There are two problems with this approach.
There is no separation between the test method and the AUT’s locators (IDs in
this example); both are intertwined in a single method. If the AUT’s UI changes
its identifiers, layout, or how a login is input and processed, the test itself
must change.
The ID-locators would be spread in multiple tests, in all tests that had to
use this login page.
Applying the page object techniques, this example could be rewritten like this
in the following example of a page object for a Sign-in page.
importorg.openqa.selenium.By;importorg.openqa.selenium.WebDriver;/**
* Page Object encapsulates the Sign-in page.
*/publicclassSignInPage{protectedWebDriverdriver;// <input name="user_name" type="text" value="">privateByusernameBy=By.name("user_name");// <input name="password" type="password" value="">privateBypasswordBy=By.name("password");// <input name="sign_in" type="submit" value="SignIn">privateBysigninBy=By.name("sign_in");publicSignInPage(WebDriverdriver){this.driver=driver;if(!driver.getTitle().equals("Sign In Page")){thrownewIllegalStateException("This is not Sign In Page,"+" current page is: "+driver.getCurrentUrl());}}/**
* Login as valid user
*
* @param userName
* @param password
* @return HomePage object
*/publicHomePageloginValidUser(StringuserName,Stringpassword){driver.findElement(usernameBy).sendKeys(userName);driver.findElement(passwordBy).sendKeys(password);driver.findElement(signinBy).click();returnnewHomePage(driver);}}
and page object for a Home page could look like this.
importorg.openqa.selenium.By;importorg.openqa.selenium.WebDriver;/**
* Page Object encapsulates the Home Page
*/publicclassHomePage{protectedWebDriverdriver;// <h1>Hello userName</h1>privateBymessageBy=By.tagName("h1");publicHomePage(WebDriverdriver){this.driver=driver;if(!driver.getTitle().equals("Home Page of logged in user")){thrownewIllegalStateException("This is not Home Page of logged in user,"+" current page is: "+driver.getCurrentUrl());}}/**
* Get message (h1 tag)
*
* @return String message text
*/publicStringgetMessageText(){returndriver.findElement(messageBy).getText();}publicHomePagemanageProfile(){// Page encapsulation to manage profile functionalityreturnnewHomePage(driver);}/* More methods offering the services represented by Home Page
of Logged User. These methods in turn might return more Page Objects
for example click on Compose mail button could return ComposeMail class object */}
So now, the login test would use these two page objects as follows.
There is a lot of flexibility in how the page objects may be designed, but
there are a few basic rules for getting the desired maintainability of your
test code.
Assertions in Page Objects
Page objects themselves should never make verifications or assertions. This is
part of your test and should always be within the test’s code, never in a page
object. The page object will contain the representation of the page, and the
services the page provides via methods but no code related to what is being
tested should be within the page object.
There is one, single, verification which can, and should, be within the page
object and that is to verify that the page, and possibly critical elements on
the page, were loaded correctly. This verification should be done while
instantiating the page object. In the examples above, both the SignInPage and
HomePage constructors check that the expected page is available and ready for
requests from the test.
Page Component Objects
A page object does not necessarily need to represent all the parts of a
page itself. This was noted by Martin Fowler in the early days, while first coining the term “panel objects”.
The same principles used for page objects can be used to
create “Page Component Objects”, as it was later called, that represent discrete chunks of the
page and can be included in page objects. These component objects can
provide references to the elements inside those discrete chunks, and
methods to leverage the functionality or behavior provided by them.
For example, a Products page has multiple products.
<!-- Inventory Item --><divclass="inventory_item"><divclass="inventory_item_name">Backpack</div><divclass="pricebar"><divclass="inventory_item_price">$29.99</div><buttonid="add-to-cart-backpack">Add to cart</button></div></div>
The Products page HAS-A list of products. This object relationship is called Composition. In simpler terms, something is composed of another thing.
publicabstractclassBasePage{protectedWebDriverdriver;publicBasePage(WebDriverdriver){this.driver=driver;}}// Page ObjectpublicclassProductsPageextendsBasePage{publicProductsPage(WebDriverdriver){super(driver);// No assertions, throws an exception if the element is not loadednewWebDriverWait(driver,Duration.ofSeconds(3)).until(d->d.findElement(By.className("header_container")));}// Returning a list of products is a service of the pagepublicList<Product>getProducts(){returndriver.findElements(By.className("inventory_item")).stream().map(e->newProduct(e))// Map WebElement to a product component.toList();}// Return a specific product using a boolean-valued function (predicate)// This is the behavioral Strategy Pattern from GoFpublicProductgetProduct(Predicate<Product>condition){returngetProducts().stream().filter(condition)// Filter by product name or price.findFirst().orElseThrow();}}
The Product component object is used inside the Products page object.
publicabstractclassBaseComponent{protectedWebElementroot;publicBaseComponent(WebElementroot){this.root=root;}}// Page Component ObjectpublicclassProductextendsBaseComponent{// The root element contains the entire componentpublicProduct(WebElementroot){super(root);// inventory_item}publicStringgetName(){// Locating an element begins at the root of the componentreturnroot.findElement(By.className("inventory_item_name")).getText();}publicBigDecimalgetPrice(){returnnewBigDecimal(root.findElement(By.className("inventory_item_price")).getText().replace("$","")).setScale(2,RoundingMode.UNNECESSARY);// Sanitation and formatting}publicvoidaddToCart(){root.findElement(By.id("add-to-cart-backpack")).click();}}
So now, the products test would use the page object and the page component object as follows.
publicclassProductsTest{@TestpublicvoidtestProductInventory(){varproductsPage=newProductsPage(driver);// page objectvarproducts=productsPage.getProducts();assertEquals(6,products.size());// expected, actual}@TestpublicvoidtestProductPrices(){varproductsPage=newProductsPage(driver);// Pass a lambda expression (predicate) to filter the list of products// The predicate or "strategy" is the behavior passed as parametervarbackpack=productsPage.getProduct(p->p.getName().equals("Backpack"));// page component objectvarbikeLight=productsPage.getProduct(p->p.getName().equals("Bike Light"));assertEquals(newBigDecimal("29.99"),backpack.getPrice());assertEquals(newBigDecimal("9.99"),bikeLight.getPrice());}}
The page and component are represented by their own objects. Both objects only have methods for the services they offer, which matches the real-world application in object-oriented programming.
You can even
nest component objects inside other component objects for more complex
pages. If a page in the AUT has multiple components, or common
components used throughout the site (e.g. a navigation bar), then it
may improve maintainability and reduce code duplication.
Other Design Patterns Used in Testing
There are other design patterns that also may be used in testing. Discussing all of these is
beyond the scope of this user guide. Here, we merely want to introduce the
concepts to make the reader aware of some of the things that can be done. As
was mentioned earlier, many have blogged on this topic and we encourage the
reader to search for blogs on these topics.
Implementation Notes
PageObjects can be thought of as facing in two directions simultaneously. Facing toward the developer of a test, they represent the services offered by a particular page. Facing away from the developer, they should be the only thing that has a deep knowledge of the structure of the HTML of a page (or part of a page) It’s simplest to think of the methods on a Page Object as offering the “services” that a page offers rather than exposing the details and mechanics of the page. As an example, think of the inbox of any web-based email system. Amongst the services it offers are the ability to compose a new email, choose to read a single email, and list the subject lines of the emails in the inbox. How these are implemented shouldn’t matter to the test.
Because we’re encouraging the developer of a test to try and think about the services they’re interacting with rather than the implementation, PageObjects should seldom expose the underlying WebDriver instance. To facilitate this, methods on the PageObject should return other PageObjects. This means we can effectively model the user’s journey through our application. It also means that should the way that pages relate to one another change (like when the login page asks the user to change their password the first time they log into a service when it previously didn’t do that), simply changing the appropriate method’s signature will cause the tests to fail to compile. Put another way; we can tell which tests would fail without needing to run them when we change the relationship between pages and reflect this in the PageObjects.
One consequence of this approach is that it may be necessary to model (for example) both a successful and unsuccessful login; or a click could have a different result depending on the app’s state. When this happens, it is common to have multiple methods on the PageObject:
publicclassLoginPage{publicHomePageloginAs(Stringusername,Stringpassword){// ... clever magic happens here}publicLoginPageloginAsExpectingError(Stringusername,Stringpassword){// ... failed login here, maybe because one or both of the username and password are wrong}publicStringgetErrorMessage(){// So we can verify that the correct error is shown}}
The code presented above shows an important point: the tests, not the PageObjects, should be responsible for making assertions about the state of a page. For example:
publicvoidtestMessagesAreReadOrUnread(){Inboxinbox=newInbox(driver);inbox.assertMessageWithSubjectIsUnread("I like cheese");inbox.assertMessageWithSubjectIsNotUnread("I'm not fond of tofu");}
could be re-written as:
publicvoidtestMessagesAreReadOrUnread(){Inboxinbox=newInbox(driver);assertTrue(inbox.isMessageWithSubjectIsUnread("I like cheese"));assertFalse(inbox.isMessageWithSubjectIsUnread("I'm not fond of tofu"));}
Of course, as with every guideline, there are exceptions, and one that is commonly seen with PageObjects is to check that the WebDriver is on the correct page when we instantiate the PageObject. This is done in the example below.
Finally, a PageObject need not represent an entire page. It may represent a section that appears frequently within a site or page, such as site navigation. The essential principle is that there is only one place in your test suite with knowledge of the structure of the HTML of a particular (part of a) page.
Summary
The public methods represent the services that the page offers
Try not to expose the internals of the page
Generally don’t make assertions
Methods return other PageObjects
Need not represent an entire page
Different results for the same action are modelled as different methods
Example
publicclassLoginPage{privatefinalWebDriverdriver;publicLoginPage(WebDriverdriver){this.driver=driver;// Check that we're on the right page.if(!"Login".equals(driver.getTitle())){// Alternatively, we could navigate to the login page, perhaps logging out firstthrownewIllegalStateException("This is not the login page");}}// The login page contains several HTML elements that will be represented as WebElements.// The locators for these elements should only be defined once.ByusernameLocator=By.id("username");BypasswordLocator=By.id("passwd");ByloginButtonLocator=By.id("login");// The login page allows the user to type their username into the username fieldpublicLoginPagetypeUsername(Stringusername){// This is the only place that "knows" how to enter a usernamedriver.findElement(usernameLocator).sendKeys(username);// Return the current page object as this action doesn't navigate to a page represented by another PageObjectreturnthis;}// The login page allows the user to type their password into the password fieldpublicLoginPagetypePassword(Stringpassword){// This is the only place that "knows" how to enter a passworddriver.findElement(passwordLocator).sendKeys(password);// Return the current page object as this action doesn't navigate to a page represented by another PageObjectreturnthis;}// The login page allows the user to submit the login formpublicHomePagesubmitLogin(){// This is the only place that submits the login form and expects the destination to be the home page.// A seperate method should be created for the instance of clicking login whilst expecting a login failure. driver.findElement(loginButtonLocator).submit();// Return a new page object representing the destination. Should the login page ever// go somewhere else (for example, a legal disclaimer) then changing the method signature// for this method will mean that all tests that rely on this behaviour won't compile.returnnewHomePage(driver);}// The login page allows the user to submit the login form knowing that an invalid username and / or password were enteredpublicLoginPagesubmitLoginExpectingFailure(){// This is the only place that submits the login form and expects the destination to be the login page due to login failure.driver.findElement(loginButtonLocator).submit();// Return a new page object representing the destination. Should the user ever be navigated to the home page after submiting a login with credentials // expected to fail login, the script will fail when it attempts to instantiate the LoginPage PageObject.returnnewLoginPage(driver);}// Conceptually, the login page offers the user the service of being able to "log into"// the application using a user name and password. publicHomePageloginAs(Stringusername,Stringpassword){// The PageObject methods that enter username, password & submit login have already defined and should not be repeated here.typeUsername(username);typePassword(password);returnsubmitLogin();}}
/**
* Takes a username and password, fills out the fields, and clicks "login".
* @return An instance of the AccountPage
*/publicAccountPageloginAsUser(Stringusername,Stringpassword){WebElementloginField=driver.findElement(By.id("loginField"));loginField.clear();loginField.sendKeys(username);// Fill out the password field. The locator we're using is "By.id", and we should// have it defined elsewhere in the class.WebElementpasswordField=driver.findElement(By.id("password"));passwordField.clear();passwordField.sendKeys(password);// Click the login button, which happens to have the id "submit".driver.findElement(By.id("submit")).click();// Create and return a new instance of the AccountPage (via the built-in Selenium// PageFactory).returnPageFactory.newInstance(AccountPage.class);}
publicvoidloginTest(){loginAsUser("cbrown","cl0wn3");// Now that we're logged in, do some other stuff--since we used a DSL to support// our testers, it's as easy as choosing from available methods.do.something();do.somethingElse();Assert.assertTrue("Something should have been done!",something.wasDone());// Note that we still haven't referred to a button or web control anywhere in this// script...}
If you choose pytest as your test runner, this can be
easily done by yielding your driver in a global fixture. This way each test gets its own
driver instance, and you can ensure that drivers always quit after a test is finished
(pass or fail).
publicabstractclassBasePage{protectedWebDriverdriver;publicBasePage(WebDriverdriver){this.driver=driver;}}publicclassGoogleSearchPageextendsBasePage{publicGoogleSearchPage(WebDriverdriver){super(driver);// Generally do not assert within pages or components.// Effectively throws an exception if the lambda condition is not met.newWebDriverWait(driver,Duration.ofSeconds(3)).until(d->d.findElement(By.id("logo")));}publicGoogleSearchPagesetSearchString(Stringsstr){driver.findElement(By.id("gbqfq")).sendKeys(sstr);returnthis;}publicvoidclickSearchButton(){driver.findElement(By.id("gbqfb")).click();}}
7.4.10 - テストごとに新しいブラウザを起動する
クリーンな既知の状態から各テストを開始します。
理想的には、テストごとに新しい仮想マシンを起動します。
新しい仮想マシンの起動が実用的でない場合は、少なくともテストごとに新しいWebDriverを起動してください。
Firefoxの場合、既知のプロファイルでWebDriverを起動します。
Most browser drivers like GeckoDriver and ChromeDriver will start with a clean
known state with a new user profile, by default.
WebDriverdriver=newFirefoxDriver();
7.5 - 推奨されない行動
Seleniumでブラウザを自動化するときに避けるべきこと。
7.5.1 - CAPTCHA(キャプチャ)
CAPTCHA(キャプチャ)は、 Completely Automated Public Turing test
to tell Computers and Humans Apart (コンピューターと人間を区別するための完全に自動化された公開チューリングテスト)の略で、自動化を防ぐように明示的に設計されているため、試さないでください!
CAPTCHAチェックを回避するための2つの主要な戦略があります。
Most of the documentation found in this section is still in English.
Please note we are not accepting pull requests to translate this content
as translating documentation of legacy components does not add value to
the community nor the project.
usingSystem;usingSystem.Text;usingSystem.Text.RegularExpressions;usingSystem.Threading;usingNUnit.Framework;usingSelenium;namespaceSeleniumTests{ [TestFixture]publicclassNewTest{privateISeleniumselenium;privateStringBuilderverificationErrors; [SetUp]publicvoidSetupTest(){selenium=newDefaultSelenium("localhost",4444,"*firefox","http://www.google.com/");selenium.Start();verificationErrors=newStringBuilder();} [TearDown]publicvoidTeardownTest(){try{selenium.Stop();}catch(Exception){// Ignore errors if unable to close the browser}Assert.AreEqual("",verificationErrors.ToString());} [Test]publicvoidTheNewTest(){selenium.Open("/");selenium.Type("q","selenium rc");selenium.Click("btnG");selenium.WaitForPageToLoad("30000");Assert.AreEqual("selenium rc - Google Search",selenium.GetTitle());}}}
Java
/** Add JUnit framework to your classpath if not already there
* for this example to work
*/packagecom.example.tests;importcom.thoughtworks.selenium.*;importjava.util.regex.Pattern;publicclassNewTestextendsSeleneseTestCase{publicvoidsetUp()throwsException{setUp("http://www.google.com/","*firefox");}publicvoidtestNew()throwsException{selenium.open("/");selenium.type("q","selenium rc");selenium.click("btnG");selenium.waitForPageToLoad("30000");assertTrue(selenium.isTextPresent("Results * for selenium rc"));}}
Php
<?phprequire_once'PHPUnit/Extensions/SeleniumTestCase.php';classExampleextendsPHPUnit_Extensions_SeleniumTestCase{functionsetUp(){$this->setBrowser("*firefox");$this->setBrowserUrl("http://www.google.com/");}functiontestMyTestCase(){$this->open("/");$this->type("q","selenium rc");$this->click("btnG");$this->waitForPageToLoad("30000");$this->assertTrue($this->isTextPresent("Results * for selenium rc"));}}?>
Python
fromseleniumimportseleniumimportunittest,time,reclassNewTest(unittest.TestCase):defsetUp(self):self.verificationErrors=[]self.selenium=selenium("localhost",4444,"*firefox","http://www.google.com/")self.selenium.start()deftest_new(self):sel=self.seleniumsel.open("/")sel.type("q","selenium rc")sel.click("btnG")sel.wait_for_page_to_load("30000")self.failUnless(sel.is_text_present("Results * for selenium rc"))deftearDown(self):self.selenium.stop()self.assertEqual([],self.verificationErrors)
Ruby
require"selenium/client"require"test/unit"classNewTest<Test::Unit::TestCasedefsetup@verification_errors=[]if$selenium@selenium=$seleniumelse@selenium=Selenium::Client::Driver.new("localhost",4444,"*firefox","http://www.google.com/",60);@selenium.startend@selenium.set_context("test_new")enddefteardown@selenium.stopunless$seleniumassert_equal[],@verification_errorsenddeftest_new@selenium.open"/"@selenium.type"q","selenium rc"@selenium.click"btnG"@selenium.wait_for_page_to_load"30000"assert@selenium.is_text_present("Results * for selenium rc")endend
packagecom.example.tests;// We specify the package of our testsimportcom.thoughtworks.selenium.*;// This is the driver's import. You'll use this for instantiating a// browser and making it do what you need.importjava.util.regex.Pattern;// Selenium-IDE add the Pattern module because it's sometimes used for // regex validations. You can remove the module if it's not used in your // script.publicclassNewTestextendsSeleneseTestCase{// We create our Selenium test casepublicvoidsetUp()throwsException{setUp("http://www.google.com/","*firefox");// We instantiate and start the browser}publicvoidtestNew()throwsException{selenium.open("/");selenium.type("q","selenium rc");selenium.click("btnG");selenium.waitForPageToLoad("30000");assertTrue(selenium.isTextPresent("Results * for selenium rc"));// These are the real test steps}}
C#
.NETクライアントドライバーはMicrosoft.NETで動作します。
NUnitやVisual Studio 2005 Team Systemなどの.NETテストフレームワークで利用できます。
Selenium-IDEは、テストフレームワークとしてNUnitを使用することを想定しています。
以下の生成コードでこれを確認できます。
NUnitの using ステートメントと、テストクラスの各メンバー関数の役割を識別する対応するNUnit属性が含まれています。
usingSystem;usingSystem.Text;usingSystem.Text.RegularExpressions;usingSystem.Threading;usingNUnit.Framework;usingSelenium;namespaceSeleniumTests{ [TestFixture]publicclassNewTest{privateISeleniumselenium;privateStringBuilderverificationErrors; [SetUp]publicvoidSetupTest(){selenium=newDefaultSelenium("localhost",4444,"*iehta","http://www.google.com/");selenium.Start();verificationErrors=newStringBuilder();} [TearDown]publicvoidTeardownTest(){try{selenium.Stop();}catch(Exception){// Ignore errors if unable to close the browser}Assert.AreEqual("",verificationErrors.ToString());} [Test]publicvoidTheNewTest(){// Open Google search engine. selenium.Open("http://www.google.com/");// Assert Title of page.Assert.AreEqual("Google",selenium.GetTitle());// Provide search term as "Selenium OpenQA"selenium.Type("q","Selenium OpenQA");// Read the keyed search term and assert it.Assert.AreEqual("Selenium OpenQA",selenium.GetValue("q"));// Click on Search button.selenium.Click("btnG");// Wait for page to load.selenium.WaitForPageToLoad("5000");// Assert that "www.openqa.org" is available in search results.Assert.IsTrue(selenium.IsTextPresent("www.openqa.org"));// Assert that page title is - "Selenium OpenQA - Google Search"Assert.AreEqual("Selenium OpenQA - Google Search",selenium.GetTitle());}}}
fromseleniumimportselenium# This is the driver's import. You'll use this class for instantiating a# browser and making it do what you need.importunittest,time,re# This are the basic imports added by Selenium-IDE by default.# You can remove the modules if they are not used in your script.classNewTest(unittest.TestCase):# We create our unittest test casedefsetUp(self):self.verificationErrors=[]# This is an empty array where we will store any verification errors# we find in our testsself.selenium=selenium("localhost",4444,"*firefox","http://www.google.com/")self.selenium.start()# We instantiate and start the browserdeftest_new(self):# This is the test code. Here you should put the actions you need# the browser to do during your test.sel=self.selenium# We assign the browser to the variable "sel" (just to save us from # typing "self.selenium" each time we want to call the browser).sel.open("/")sel.type("q","selenium rc")sel.click("btnG")sel.wait_for_page_to_load("30000")self.failUnless(sel.is_text_present("Results * for selenium rc"))# These are the real test stepsdeftearDown(self):self.selenium.stop()# we close the browser (I'd recommend you to comment this line while# you are creating and debugging your tests)self.assertEqual([],self.verificationErrors)# And make the test fail if we found that any verification errors# were found
# load the Selenium-Client gemrequire"selenium/client"# Load Test::Unit, Ruby's default test framework.# If you prefer RSpec, see the examples in the Selenium-Client# documentation.require"test/unit"classUntitled<Test::Unit::TestCase# The setup method is called before each test.defsetup# This array is used to capture errors and display them at the# end of the test run.@verification_errors=[]# Create a new instance of the Selenium-Client driver.@selenium=Selenium::Client::Driver.new\:host=>"localhost",:port=>4444,:browser=>"*chrome",:url=>"http://www.google.com/",:timeout_in_second=>60# Start the browser session@selenium.start# Print a message in the browser-side log and status bar# (optional).@selenium.set_context("test_untitled")end# The teardown method is called after each test.defteardown# Stop the browser session.@selenium.stop# Print the array of error messages, if any.assert_equal[],@verification_errorsend# This is the main body of your test.deftest_untitled# Open the root of the site we specified when we created the# new driver instance, above.@selenium.open"/"# Type 'selenium rc' into the field named 'q'@selenium.type"q","selenium rc"# Click the button named "btnG"@selenium.click"btnG"# Wait for the search results page to load.# Note that we don't need to set a timeout here, because that# was specified when we created the new driver instance, above.@selenium.wait_for_page_to_loadbegin# Test whether the search results contain the expected text.# Notice that the star (*) is a wildcard that matches any# number of characters.assert@selenium.is_text_present("Results * for selenium rc")rescueTest::Unit::AssertionFailedError# If the assertion fails, push it onto the array of errors.@verification_errors<<$!endendend
これらの各例はブラウザを開き、“ブラウザーインスタンス"をプログラム変数に割り当てることでそのブラウザを表します。
このプログラム変数は、ブラウザからメソッドを呼び出すために使用されます。
これらのメソッドは、Seleniumコマンドを実行します。
つまり、 open コマンドや type コマンド、 verify コマンドなどです。
// Collection of String values.String[]arr={"ide","rc","grid"};// Execute loop for each String in array 'arr'.foreach(Stringsinarr){sel.open("/");sel.type("q","selenium "+s);sel.click("btnG");sel.waitForPageToLoad("30000");assertTrue("Expected text: "+s+" is missing on page.",sel.isTextPresent("Results * for selenium "+s));}
// If element is available on page then perform type operation.if(selenium.isElementPresent("q")){selenium.type("q","Selenium rc");}else{System.out.printf("Element: "+q+" is not available on page.")}
publicstaticString[]getAllCheckboxIds(){Stringscript="var inputId = new Array();";// Create array in java script.script+="var cnt = 0;";// Counter for check box ids. script+="var inputFields = new Array();";// Create array in java script.script+="inputFields = window.document.getElementsByTagName('input');";// Collect input elements.script+="for(var i=0; i<inputFields.length; i++) {";// Loop through the collected elements.script+="if(inputFields[i].id !=null "+"&& inputFields[i].id !='undefined' "+"&& inputFields[i].getAttribute('type') == 'checkbox') {";// If input field is of type check box and input id is not null.script+="inputId[cnt]=inputFields[i].id ;"+// Save check box id to inputId array."cnt++;"+// increment the counter."}"+// end of if."}";// end of for.script+="inputId.toString();";// Convert array in to string. String[]checkboxIds=selenium.getEval(script).split(",");// Split the string.returncheckboxIds;}
"Unable to connect to remote server (Inner Exception Message:
No connection could be made because the target machine actively
refused it )"(using .NET and XP Service Pack 2)
このエラーは断続的に発生する場合があります。
問題はデバッガーのオーバーヘッドがシステムに追加されたときに再現できない競合状態に起因するため、デバッガーで問題を再現することはできません。
パーミッションの問題については、チュートリアルで詳しく説明します。
The Same Origin Policy、Proxy Injectionに関する章を注意深くお読みください。
Selenium 3 was the implementation of WebDriver without the Selenium RC Code. It has since been replaced with Selenium 4, which implements the W3C WebDriver specification.
8.3.1 - Grid 3
Selenium Grid 3 supported WebDriver without Selenium RC code. Grid 3 was completely rewritten for the new Grid 4.
{"_comment":"Configuration for Hub - hubConfig.json","host":ip,"maxSession":5,"port":4444,"cleanupCycle":5000,"timeout":300000,"newSessionWaitTimeout":-1,"servlets":[],"prioritizer":null,"capabilityMatcher":"org.openqa.grid.internal.utils.DefaultCapabilityMatcher","throwOnCapabilityNotPresent":true,"nodePolling":180000,"platform":"WINDOWS"}
The Selenese HTML syntax can be used to write and run tests without requiring
knowledge of a programming language. With a basic knowledge of selenese and
Selenium-IDE you can quickly produce and run testcases.
<html><head><title>Test Suite Function Tests - Priority 1</title></head><body><table><tr><td><b>Suite Of Tests</b></td></tr><tr><td><ahref="./Login.html">Login</a></td></tr><tr><td><ahref="./SearchValues.html">Test Searching for Values</a></td></tr><tr><td><ahref="./SaveValues.html">Test Save</a></td></tr></table></body></html>
注 : 一部のタイプの XPath ロケータや DOM ロケータと異なり、これまでに示した 3 つのタイプのロケータを使えば、ページ上の位置に関係なく UI 要素をテストすることができます。
したがって、ページの構造や構成が変わっても、テストはパスします。
ページの構造が変わったかどうかについては、テストしたい場合もテストしたくない場合もあるでしょう。
Web デザイナーが頻繁にページに手を加えていて、ページの機能を回帰テストの対象にする必要がある場合には、id 属性や name 属性、または任意の HTML プロパティによるテストが非常に重要になります。
XPathによる特定
XPath は、XML ドキュメント内のノードを特定するために使われる言語です。
HTML は XML (XHTML) の実装でもありうるので、Selenium ユーザーは XPath という強力な言語を使って、Web アプリケーション内の要素を特定することができます。
XPath は、id 属性や name 属性による要素の特定という単純な方法を (サポートすると当時に) さらに拡張しており、ページ上の3番目のチェックボックスを特定するなど、あらゆる種類の新しい可能性を開いてくれる言語です。
XPathを使う主な理由の1つは、特定したい要素に対応する適切な id 属性や name 属性がない場合があることです。
XPathを使うと、要素を絶対的に特定したり (ただし、このやり方は推奨されません)、id 属性または name 属性を持つ要素からの相対位置で要素を特定したりできます。
XPath ロケータを使って、id や name 以外の属性から要素を特定することもできます。
絶対 XPath には、ルート (html) からのすべての要素の位置が含まれており、したがって 、アプリケーションにわずかな変更を加えただけで、XPath による特定がうまくいかなる可能性があります。
id 属性または name 属性を持つ近くの要素 (理想的には親要素) を見つけることによって、対象となる要素を相対関係に基づいて特定できるようになります。
これは、アプリケーションに変更が加えられても変わる可能性は低く、テストをより堅牢にすることができます。
プレーンな store コマンドは、たくさんある store コマンド群の中で最も基本的なコマンドで、Selenium 変数に単純に定数値を格納するのに使用できます。
store コマンドは、変数に格納するテキスト値と Selenium 変数の 2 つのパラメータを取ります。
変数の名前を付けるときは、英数文字だけを使う標準的な命名規則に従ってください。
<!DOCTYPE HTML><html><head><scripttype="text/javascript">functionoutput(resultText){document.getElementById('output').childNodes[0].nodeValue=resultText;}functionshow_confirm(){varconfirmation=confirm("Chose an option.");if(confirmation==true){output("Confirmed.");}else{output("Rejected!");}}functionshow_alert(){alert("I'm blocking!");output("Alert is gone.");}functionshow_prompt(){varresponse=prompt("What's the best web QA tool?","Selenium");output(response);}functionopen_window(windowName){window.open("newWindow.html",windowName);}</script></head><body><inputtype="button"id="btnConfirm"onclick="show_confirm()"value="Show confirm box"/><inputtype="button"id="btnAlert"onclick="show_alert()"value="Show alert"/><inputtype="button"id="btnPrompt"onclick="show_prompt()"value="Show prompt"/><ahref="newWindow.html"id="lnkNewWindow"target="_blank">New Window Link</a><inputtype="button"id="btnNewNamelessWindow"onclick="open_window()"value="Open Nameless Window"/><inputtype="button"id="btnNewNamedWindow"onclick="open_window('Mike')"value="Open Named Window"/><br/><spanid="output"></span></body></html>
テストスイートファイルは、1 列のテーブルを含む HTML ファイルです。
<tbody> セクション内の各行のセルには、テストケースへのリンクが収められています。
次に示すのは、4 つのテストケースを含むテストスイートの例です。
<html><head><metahttp-equiv="Content-Type"content="text/html; charset=UTF-8"><title>Sample Selenium Test Suite</title></head><body><tablecellpadding="1"cellspacing="1"border="1"><thead><tr><td>Test Cases for De Anza A-Z Directory Links</td></tr></thead><tbody><tr><td><ahref="./a.html">A Links</a></td></tr><tr><td><ahref="./b.html">B Links</a></td></tr><tr><td><ahref="./c.html">C Links</a></td></tr><tr><td><ahref="./d.html">D Links</a></td></tr></tbody></table></body></html>
注 : テストケースファイルは、呼び出し元のテストスイートファイルと同じ場所に置く必要はありません。
実際、Mac OS と Linux システムではそのとおりです。
ただし、この項目の執筆時点では、Windows システムで使う場合にはバグがあって、テストケースファイルを呼び出し元のテストスイートファイルと別の場所に置くことはできません。
上記の open コマンドの場合のように変数置換を使用しようとして失敗した場合は、アクセスしようとしている値を持つ変数を実際に作成していないことを示します。
これは、変数を Target フィールドに配置する必要がある場合に Value フィールドに配置するか、その逆の場合があります。
上記の例では、storeコマンドの2つのパラメーターが、必要なものと逆の順序で誤って配置されています。
Seleneseコマンドの場合、最初の必須パラメーターは Target フィールドに入力し、2番目の必須パラメーター(存在する場合)は Value フィールドに入力する必要があります。
error loading test case: [Exception… “Component returned failure code:
0x80520012 (NS_ERROR_FILE_NOT_FOUND) [nsIFileInputStream.init]” nresult:
“0x80520012 (NS_ERROR_FILE_NOT_FOUND)” location: “JS frame ::
chrome://selenium-ide/content/file-utils.js :: anonymous :: line 48” data: no]
[user@localhost ~]$ xvfb-run java -Dwebdriver.gecko.driver=/home/mmasek/geckodriver.0.18.0 -jar selenium-html-runner-3.7.1.jar -htmlSuite "*firefox""https://YOUR-BASE-URL""$(pwd)/testsuite.html""results.html"; grep result: -A1 results.html/firefox.results.html
Multi-window mode is longer used as an option and will be ignored.
1510061109691 geckodriver INFO geckodriver 0.18.0
1510061109708 geckodriver INFO Listening on 127.0.0.1:2885
1510061110162 geckodriver::marionette INFO Starting browser /usr/bin/firefox with args ["-marionette"]1510061111084 Marionette INFO Listening on port 432291510061111187 Marionette WARN TLS certificate errors will be ignored for this session
Nov 07, 2017 1:25:12 PM org.openqa.selenium.remote.ProtocolHandshake createSession
INFO: Detected dialect: W3C
2017-11-07 13:25:12.714:INFO::main: Logging initialized @3915ms to org.seleniumhq.jetty9.util.log.StdErrLog
2017-11-07 13:25:12.804:INFO:osjs.Server:main: jetty-9.4.z-SNAPSHOT
2017-11-07 13:25:12.822:INFO:osjsh.ContextHandler:main: Started o.s.j.s.h.ContextHandler@87a85e1{/tests,null,AVAILABLE}2017-11-07 13:25:12.843:INFO:osjs.AbstractConnector:main: Started ServerConnector@52102734{HTTP/1.1,[http/1.1]}{0.0.0.0:31892}2017-11-07 13:25:12.843:INFO:osjs.Server:main: Started @4045ms
Nov 07, 2017 1:25:13 PM org.openqa.selenium.server.htmlrunner.CoreTestCase run
INFO: |open | /auth_mellon.php ||Nov 07, 2017 1:25:14 PM org.openqa.selenium.server.htmlrunner.CoreTestCase run
INFO: |waitForPageToLoad |3000||.
.
.etc
<td>result:</td>
<td>PASS</td>
We want to be able to run all of our code examples in the CI to ensure that people can copy and paste and
execute everything on the site. So we put the code where it belongs in the
examples directory.
Each page in the documentation correlates to a test file in each of the languages, and should follow naming conventions.
For instance examples for this page https://www.selenium.dev/documentation/webdriver/browsers/chrome/ get added in these
files:
Each example should get its own test. Ideally each test has an assertion that verifies the code works as intended.
Once the code is copied to its own test in the proper file, it needs to be referenced in the markdown file.
For example, the tab in Ruby would look like this:
The line numbers at the end represent only the line or lines of code that actually represent the item being displayed.
If a user wants more context, they can click the link to the GitHub page that will show the full context.
Make sure that if you add a test to the page that all the other line numbers in the markdown file are still
correct. Adding a test at the top of a page means updating every single reference in the documentation that has a line
number for that file.
Everything from the Creating Examples section applies, with one addition.
Make sure the tab includes text=true. By default, the tabs get formatted
for code, so to use markdown or other shortcode statements (like gh-codeblock) it needs to be declared as text.
For most examples, the tabpane declares the text=true, but if some of the tabs have code examples, the tabpane
cannot specify it, and it must be specified in the tabs that do not need automatic code formatting.
% git clone git@github.com:seleniumhq/seleniumhq.github.io.git
% cd seleniumhq.github.io
依存関係: Hugo
We use Hugo and the Docsy theme
to build and render the site. You will need the “extended”
Sass/SCSS version of the Hugo binary to work on this site. We recommend
to use Hugo 0.125.4 .
Please follow the Install Hugo
instructions from Docsy.
The repository contains the site and docs. Before jumping into
making changes, please initialize the submodules and install the
needed dependencies (see commands below). To make changes to the site,
work on the website_and_docs directory. To see a live preview of
your changes, run hugo server on the site’s root directory.
% git submodule update --init --recursive
% cd website_and_docs
% hugo server
See Style Guide for more information on our conventions for contribution
Fixes #Nを含めてください。ここでは N がこのコミットで修正したイシュー番号です(存在する場合)。
適切なコミットメッセージは次のようになります:
explain commit normatively in one line
Body of commit message is a few lines of text, explaining things
in more detail, possibly giving some background about the issue
being fixed, etc.
The body of the commit message can be several paragraphs, and
please do proper word-wrap and keep columns shorter than about
72 characters or so. That way `git log` will show things
nicely even when it is indented.
Fixes #141
Our documentation uses Title Capitalization for linkTitle which should be short
and Sentence capitalization for title which can be longer and more descriptive.
For example, a linkTitle of Special Heading might have a title of
The importance of a special heading in documentation
Line length
When editing the documentation’s source,
which is written in plain HTML,
limit your line lengths to around 100 characters.
Some of us take this one step further
and use what is called
semantic linefeeds,
which is a technique whereby the HTML source lines,
which are not read by the public,
are split at ‘natural breaks’ in the prose.
In other words, sentences are split
at natural breaks between clauses.
Instead of fussing with the lines of each paragraph
so that they all end near the right margin,
linefeeds can be added anywhere
that there is a break between ideas.
This can make diffs very easy to read
when collaborating through git,
but it is not something we enforce contributors to use.
Translations
Selenium now has official translators for each of the supported languages.
If you add a code example to the important_documentation.en.md file,
also add it to important_documentation.ja.md, important_documentation.pt-br.md,
important_documentation.zh-cn.md.
If you make text changes in the English version, just make a Pull Request.
The new process is for issues to be created and tagged as needs translation based on
changes made in a given PR.
Code examples
All references to code should be language independent,
and the code itself should be placed inside code tabs.
To generate the above tabs, this is what you need to write.
Note that the tabpane includes langEqualsHeader=true.
This auto-formats the code in each tab to match the header name,
and ensures that all tabs on the page with a language are set to the same thing.
To ensure that all code is kept up to date, our goal is to write the code in the repo where it
can be executed when Selenium versions are updated to ensure that everything is correct.
This code can be automatically displayed in the documentation using the gh-codeblock shortcode.
The shortcode automatically generates its own html, so we do not want it to auto-format with the language header.
If all tabs are using this shortcode, set text=true in the tabpane and remove langEqualsHeader=true.
If only some tabs are using this shortcode, keep langEqualsHeader=true in the tabpane and add text=true
to the tab. Note that the gh-codeblock line can not be indented at all.
One great thing about using gh-codeblock is that it adds a link to the full example.
This means you don’t have to include any additional context code, just the line(s) that
are needed, and the user can navigate to the repo to see how to use it.
If you want your example to include something other than code (default) or html (from gh-codeblock),
you need to first set text=true,
then change the Hugo syntax for the tabto use % instead of < and > with curly braces:
This is preferred to writing code comments because those will not be translated.
Only include the code that is needed for the documentation, and avoid over-explaining.
Finally, remember not to indent plain text or it will rendered as a codeblock.